为什么要学 Go?
以下引用自左耳听风专栏。
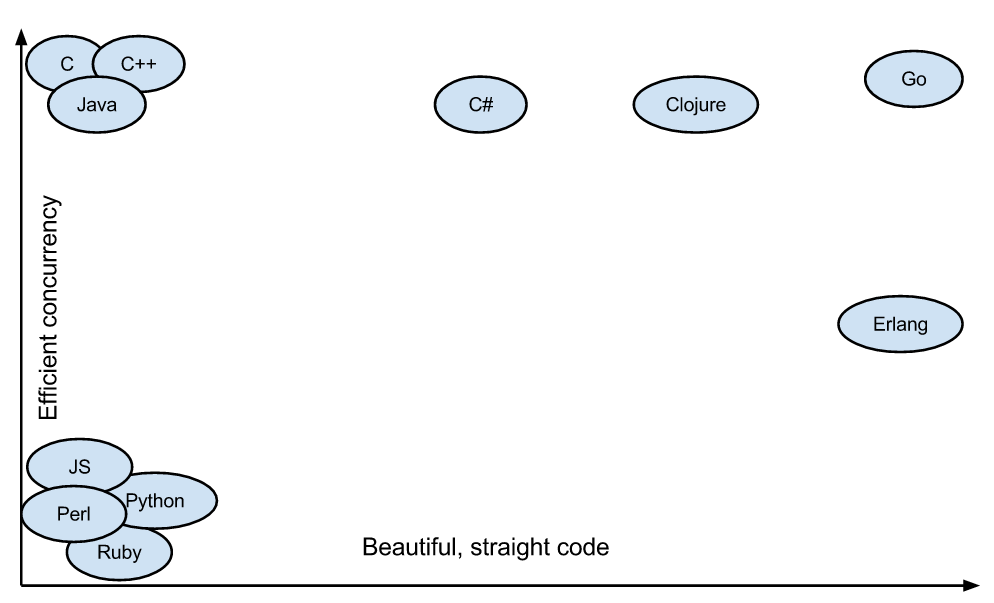
第一,语言简单,上手快 。Go 语言的语法特性简直是太简单了,简单到你几乎玩不出什么花招,直来直去的,学习难度很低,容易上手。
第二,并行和异步编程几乎无痛点 。Go 语言的 Goroutine 和 Channel 这两个神器简直就是并发和异步编程的巨大福音。像 C、C++、Java、Python 和 JavaScript 这些语言的并发和异步的编程方式控制起来就比较复杂了,并且容易出错,但 Go 语言却用非常优雅和流畅的方式解决了这个问题。这对于编程多年受尽并发和异步折磨的我来说,完全就是眼前一亮的感觉。
(图片来自 Medium:Why should you learn Go?)
第三,Go 语言的 lib 库 “麻雀虽小,五脏俱全” 。Go 语言的 lib 库中基本上有绝大多数常用的库,虽然有些库还不是很好,但我觉得这都不是主要问题,因为随着技术的发展和成熟,这些问题肯定也都会随之解决。
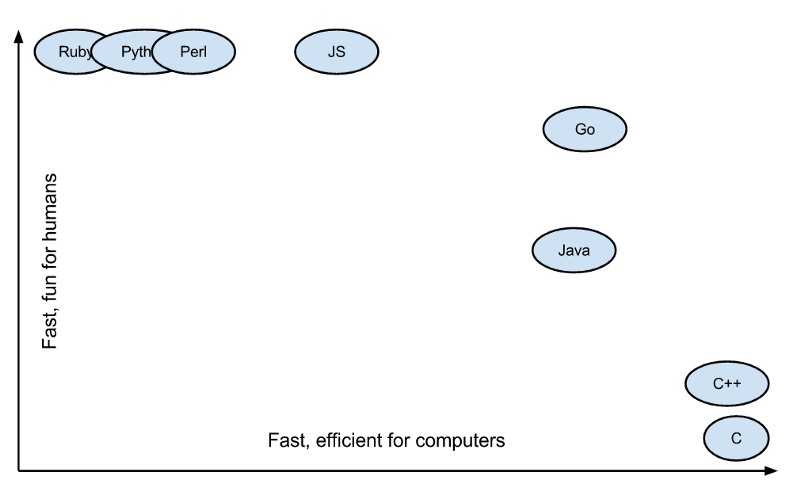
第四,C 语言的理念和 Python 的姿态 。C 语言的理念是信任程序员,保持语言的小巧,不屏蔽底层且对底层友好,关注语言的执行效率和性能。而 Python 的姿态是用尽量少的代码完成尽量多的事。于是我能够感觉到,Go 语言是想要把 C 和 Python 统一起来,这是多棒的一件事。
(图片来自 Medium:Why should you learn Go?)
所以,即便 Go 语言存在诸多的问题,比如垃圾回收、异常处理、泛型编程等,但相较于上面这几个优势,我认为这些问题都是些小问题。于是就毫不犹豫地入坑了。
学习资源 资源合集:https://github.com/developer-learning/learning-golang
官方教程:https://learn.go.dev/
入门
首首推,通过 TDD 学习 Go https://studygolang.gitbook.io/learn-go-with-tests/
首推 Go by Example 作为你的入门教程。然后,Go 101 也是一个很不错的在线电子书。
The Go Programming Language 中译本:Go 语言圣经
Go 语言官方的 Effective Go 是必读的,这篇文章告诉你如何更好地使用 Go 语言,以及 Go 语言中的一些原理。
web 开发:https://github.com/astaxie/build-web-application-with-golang/ 33.7k 星
进阶
查询 Go 项目,https://gowalker.org/,感觉是 GitHub advance search 的封装。
Go 语言高级编程 https://github.com/chai2010/advanced-go-programming-book
Go 语言原本 https://changkun.de/golang/ 学习源码
如何写出优雅的 Go https://draveness.me/golang-101
https://github.com/qcrao/Go-Questions
博客
只收录有深度的博客,请享用!
Go 语言最突出之处是并发编程,Unix 老牌黑客罗勃・派克(Rob Pike)在 Google I/O 上的两个分享,可以让你学习到一些并发编程的模式。
Go Concurrency Patterns( 幻灯片 和演讲视频 )。
Advanced Go Concurrency Patterns(幻灯片 、演讲视频 )。
然后,Go 在 GitHub 的 wiki 上有好多不错的学习资源,你可以从中学习到多。比如:
此外,还有个内容丰富的 Go 资源列表 Awesome Go ,推荐看看。
类似 awesome-go https://github.com/hackstoic/golang-open-source-projects
Go roadmap https://github.com/Alikhll/golang-developer-roadmap
http://tmrts.com/go-patterns/
Uber Go Style Guide https://github.com/uber-go/guide/blob/master/style.md
官方规范 https://github.com/golang/go/wiki/CodeReviewComments
GoLand Tips & Tricks https://www.bilibili.com/video/av57075824
Goroutine Leak 检测器,Uber出品。https://github.com/uber-go/goleak
有关安全项目 库
gopacket - Go语言用于处理网络数据包的库
xorm - Go语言实现的ORM库,支持多种数据库
代码安全
Go-SCP - Go语言安全编码实践指南
gosec - Go语言源码安全分析工具
安全工具
certigo - Go语言编写用于检查/验证证书信息的命令行工具
Blind-SQL-Injector - Go语言编写的手工盲注辅助工具
lonely-shell - Go语言实现的反弹Shell后门
hershell - Go语言反弹Shell后门
go-deliver - Go语言编写的Payload交互工具
go-shellcode - Go语言编写的ShellCode执行工具
go-mimikatz - Go语言版本的Mimikatz
NtlmSocks - 一个工作在网络层的跨平台哈希传递工具
CHAOS - Go语言编写的Windows远控工具
judas - Go语言编写的反向钓鱼工具
Modlishka - Go语言编写的反向代理钓鱼工具
Gophish - Go语言编写的开源钓鱼框架
goddi - Go语言编写的活动目录信息导出工具
goHackTools - Go语言编写的黑客工具集
honeybits - 一款Go语言开发的蜜罐
xsec-checker - Go语言编写的服务器安全检测辅助工具
janusec - Golang打造的开源WAF网关
xsec-ip-database - Go语言实现的恶意IP和域名库
xsec-traffic - Go语言编写的轻量级恶意流量分析程序
GoCrack - Go语言编写密码爆破平台
扫描工具
blacksheepwall - Go语言编写的域名信息搜集工具
amass - Go语言编写的子域名收集工具
vuls - Go语言编写的Linux/FreeBSD漏洞扫描器
gryffin - 大规模Web安全扫描平台
Gobuster - Kai下敏感目录扫描工具
OnionScan - Go语言编写的暗网扫描仪
x-crack - Go语言编写的弱口令扫描器
kraken - Go语言编写的YARA跨平台扫描器
网络工具
GoReplay - Go语言编写HTTP流量记录重放工具
NATBypass - LCX/Htran在Golang下的实现
ngrok - 反向代理/内网穿透工具
brook - Go语言编写的一款跨平台代理应用
Hyperfox - HTTP/HTTPS流量监控工具
gost - Go语言编写多功能网络代理转发工具
gomitmproxy - Go语言实现的Mitmproxy
netcap - Go语言编写的网络流量分析框架
基础语法 变量声明 每个类型都有默认的初值,比如 0,“”,false
定义的变量必须要用到,实在不用的可以用 “_”
var a, b, c int = 1 , 2 , 3 var a, b, c = 1 , 'a' , false var ( home = os.Getenv("HOME" ) user = os.Getenv("USER" ) ) a, b, c := 1 , 'a' , false
变量类型
必须显式强制类型转换
布尔:bool
整型:int、(u)int8、(u)int16、(u)int32、(u)int64、uintptr
浮点:float32、float64、原生复数:complex64、complex128
字符串:string
字符:rune(int32 别名)
byte:(int8 别名)
派生:
结构体 struct
channel
func
slice
interface
map
可用 type 设置别名
运算符 Go operator precedence: 1. * / % << >> & &^ 2. + - | ^ 3. == != < <= > >= 4. && 5. ||
new 与 make Go 提供了两种分配原语,即 new 和 make。
new 是分配一个内存,返回一个内存地址,它不会初始化内存,只会将内存置零。
type SyncedBuffer struct { lock sync.Mutex buffer bytes.Buffer } p := new (SyncedBuffer)
make 只用于创建 slice、map 和 channel,并返回一个“已初始化”的值。
常量与枚举 未指定类型的常量类似替换,不需要关心类型转换
Go 里的大写有其他含义,常量不再大写
const b string = "string" const a = "string" const ( a = 1 b = 2 c = 3 ) const ( cpp = ioat python java ) const ( _ = iota b = 1 << (10 * iota ) kb mb gb tb )
条件语句 if contents, err := ioutil.ReadFile(filename); err != nil { } switch i { case 1 : case 2 : case 3 , 4 , 5 : default : } g := "" switch { case g: } whatAmI := func (i interface {}) switch t := i.(type ) { case bool : case int : default : } } whatAmI(true )
循环 i := 1 for i <= 3 { fmt.Println(i) i } for j := 1 ; j < 3 ; j++ { } for { fmt.Println("loop" ) break }
函数 Go 只有值传递,每次传值都拷贝了一个副本,只是这副本里的某个部分可能指着同一块内存,比如 slice。
可传递指针
返回一个局部变量的地址没有问题,该局部变量对应的数据在函数返回后依然有效,编译器采用逃逸分析技术。
func eval (a, b int , opt string ) (int , error) return -1 , fmt.Errorf("error: %s" , err) } func test () t string t = "test" return } func apply (op func (int , int ) int , a , b int ) int p := reflect.ValueOf(op).Pointer() opName := runtime.FuncForPC(p).Name() fmt.Printf("Calling function %s with args %d, %d" , opName, a, b) return op(a, b) } apply(func (a, b int ) int return a + b }, 1 , 2 ) var f func (int ) int f = func (int ) int f() } func sumArgs (members ...int ) int s := 0 for i := range numbers { s += numbers[i] } return s } arr := [...]int {1 , 2 , 3 } sumArgs(arr...)
指针 指针不能运算
var a int = 2 var pa *int = &a*pa = 3
数组 Go 一般不用数组,用切片
var arr [5 ]int b := [5 ]int {1 , 2 , 3 , 4 , 5 } b := [...]int {1 , 2 , 3 , 4 , 5 } var grid [2 ][3 ]int var grid [][]int = [][]int {{1 , 2 , 3 }, {4 , 5 , 6 }}grid := [2 ][3 ]int {{1 , 2 , 3 }, {4 , 5 , 6 }} for k, v := range grid { fmt.Println(k, v) } func printArray (arr [10]int ) fmt.Println(arr) }
切片 切片本身没有数据,是对底层数组的一个 view,是功能强悍的”动态数组“。
切片通过对数组进行封装,为数据序列提供了更通用、强大的接口。
除了矩阵变换这类需要明确维度的情况外, Go 中大部分数组编程都是通过切片来实现的。
切片保存了对底层数组的引用,若将某个切片赋值给另一个切片,它们将引用同一个数组。
len(s) 用来获取长度,当前有多少个值,用了多少
cap(s) 切片总容量
append(s, tg) 添加元素
copy(dst, src) 拷贝切片
slice := []int slice := []int {1 , 2 , 3 , 4 } slice := make ([]type , len ) slice := make ([]type , len , cap ) fmt.Println(arr[:]) fmt.Println(arr[:3 ]) fmt.Println(arr[2 :]) fmt.Println(arr[3 :5 ]) s := arr[3 :5 ] rs := s[4 :6 ] b = append (b, 10 ) b = append (b, s...) fmt.Println(b)
排序 intList := []int {2 , 4 , 3 , 5 , 7 , 6 , 9 , 8 , 1 , 0 } float8List := []float64 {4.2 , 5.9 , 12.3 , 10.0 , 50.4 , 99.9 , 31.4 , 27.81828 , 3.14 } stringList := []string {"a" , "c" , "b" , "d" , "f" , "i" , "z" , "x" , "w" , "y" } sort.Ints(intList) sort.Sort(sort.IntSlice(intList)) sort.Sort(sort.Reverse(sort.IntSlice(intList))) sort.Sort(sort.Reverse(sort.Float64Slice(float8List))) sort.Sort(sort.Reverse(sort.StringSlice(stringList))) type IntSlice []int func (p IntSlice) Len () int return len (p) }func (p IntSlice) Less (i, j int ) bool return p[i] < p[j] }func (p IntSlice) Swap (i, j int ) func (p IntSlice) Sort () sort.Slice(arr, func (i, j int ) bool return arr[i][0 ] < arr[j][0 ] }) type ByLength []string func (s ByLength) Len () int return len (s) } func (s ByLength) Swap (i, j int ) s[i], s[j] = s[j], s[i] } func (s ByLength) Less (i, j int ) bool return len (s[i]) < len (s[j]) } fruits := []string {"peach" , "banana" , "kiwi" } sort.Sort(ByLength(fruits))
就地去重,需要先排序 import "sort" in := []int {3 ,2 ,1 ,4 ,3 ,2 ,1 ,4 ,1 } sort.Ints(in) j := 0 for i := 1 ; i < len (in); i++ { if in[j] == in[i] { continue } j++ in[j] = in[i] } result := in[:j+1 ] fmt.Println(result)
删除元素 a = append (a[:i], a[i+1 :]...) a = a[:i+copy (a[i:], a[i+1 :])] a := []string {"A" , "B" , "C" , "D" , "E" } i := 2 a[i] = a[len (a)-1 ] a[len (a)-1 ] = "" a = a[:len (a)-1 ] fmt.Println(a) copy (a[i:], a[i+1 :]) a[len (a)-1 ] = "" a = a[:len (a)-1 ]
切片比较 reflect.DeepEqual(s1, s2)
reverse To replace the contents of a slice with the same elements but in reverse order:
for i := len (a)/2 -1 ; i >= 0 ; i-- { opp := len (a)-1 -i a[i], a[opp] = a[opp], a[i] }
The same thing, except with two indices:
for left, right := 0 , len (a)-1 ; left < right; left, right = left+1 , right-1 { a[left], a[right] = a[right], a[left] }
底层结构 https://github.com/golang/go/blob/440f7d64048cd94cba669e16fe92137ce6b84073/src/runtime/slice.go
加深理解:https://www.calhoun.io/why-are-slices-sometimes-altered-when-passed-by-value-in-go/
所以传值的时候,slice 对应的变量是拷贝的,但里面指向的 array 没变,除非 append 等操作改变了这个指针。
type slice struct { array unsafe.Pointer len int cap int } +--------+ | | | ptr |+------------+-------+-----------+ | | | | +--------+ | | | | | | | | | | | len 5 | | | | | | | +--------+ v v | | +-----+-----+-----+-----+----+ | | | | | | | | | cap 5 | [5]int | 0 | 1 | 2 | 3 | 4 | | | +-----+-----+-----+-----+----+ +--------+ slice := arr[1:4] arr := [5]int{0,1,2,3,4}
package mainimport ( "fmt" ) func main () s := make ([]int , 0 , 7 ) for i := 1 ; i <= 3 ; i++ { s = append (s, i) } reverse(s) fmt.Println(len (s), cap (s)) fmt.Println(s) } func reverse (s []int ) newElem := 999 for len (s) < cap (s) { fmt.Println("Adding an element:" , newElem, "cap:" , cap (s), "len:" , len (s)) s = append (s, newElem) newElem++ } fmt.Println(len (s), cap (s)) fmt.Println(s) for i, j := 0 , len (s)-1 ; i < j; i++ { j = len (s) - (i + 1 ) s[i], s[j] = s[j], s[i] } } Adding an element: 999 cap : 7 len : 3 Adding an element: 1000 cap : 7 len : 4 Adding an element: 1001 cap : 7 len : 5 Adding an element: 1002 cap : 7 len : 6 7 7 [1 2 3 999 1000 1001 1002 ] 3 7 [1002 1001 1000 ]
Copy b = make([]T, len(a)) copy(b, a) // or b = append([]T(nil), a...) // or b = append(a[:0:0], a...) // See https://github.com/go101/go101/wiki
Cut a = append(a[:i], a[j:]...)
Delete without preserving order a[i] = a[len(a)-1] a = a[:len(a)-1]
NOTE If the type of the element is a pointer or a struct with pointer fields, which need to be garbage collected, the above implementations of Cut and Delete have a potential memory leak problem: some elements with values are still referenced by slice a and thus can not be collected. The following code can fix this problem:
Cut
copy(a[i:], a[j:]) for k, n := len(a)-j+i, len(a); k < n; k++ { a[k] = nil // or the zero value of T } a = a[:len(a)-j+i]
Delete
if i < len(a)-1 { copy(a[i:], a[i+1:]) } a[len(a)-1] = nil // or the zero value of T a = a[:len(a)-1]
Delete without preserving order
a[i] = a[len(a)-1] a[len(a)-1] = nil a = a[:len(a)-1]
Expand a = append(a[:i], append(make([]T, j), a[i:]...)...)
Extend a = append(a, make([]T, j)...)
Filter (in place) n := 0 for _, x := range a { if keep(x) { a[n] = x n++ } } a = a[:n]
Insert a = append(a[:i], append([]T{x}, a[i:]...)...)
NOTE The second append creates a new slice with its own underlying storage and copies elements in a[i:] to that slice, and these elements are then copied back to slice a (by the first append). The creation of the new slice (and thus memory garbage) and the second copy can be avoided by using an alternative way:
Insert
s = append(s, 0 /* use the zero value of the element type */) copy(s[i+1:], s[i:]) s[i] = x
InsertVector a = append(a[:i], append(b, a[i:]...)...)
Push Front/Unshift Pop Front/Shift Filtering without allocating This trick uses the fact that a slice shares the same backing array and capacity as the original, so the storage is reused for the filtered slice. Of course, the original contents are modified.
b := a[:0] for _, x := range a { if f(x) { b = append(b, x) } }
For elements which must be garbage collected, the following code can be included afterwards:
for i := len(b); i < len(a); i++ { a[i] = nil // or the zero value of T }
Reversing Shuffling Fisher–Yates algorithm:
Since go1.10, this is available at math/rand.Shuffle
for i := len(a) - 1; i > 0; i-- { j := rand.Intn(i + 1) a[i], a[j] = a[j], a[i] }
Batching with minimal allocation Useful if you want to do batch processing on large slices.
actions := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} batchSize := 3 batches := make([][]int, 0, (len(actions) + batchSize - 1) / batchSize) for batchSize < len(actions) { actions, batches = actions[batchSize:], append(batches, actions[0:batchSize:batchSize]) } batches = append(batches, actions)
Yields the following:
[[0 1 2] [3 4 5] [6 7 8] [9]]
Map 哈希表实现,除了 slice、map、function 的内建类型都可以做 key,不含这些字段的 Struct 也可
m := make (map [string ]int ) m["one" ] = 1 m["two" ] = 2 m := map [string ]int { "one" : 1 , "two" : 2 , } var m map [string ]int one := m["one" ] one, ok := m["one" ] for k, v := range m { fmt.Println(k, v) } delete (m, "one" )
stack
项目要用的话直接 import “github.com/golang-collections/collections/stack”
用 list 实现 stack
package stack import "container/list" type Stack struct { list *list.List } func NewStack () *Stack list := list.New() return &Stack{list} } func (stack *Stack) Push (value interface {}) stack.list.PushBack(value) } func (stack *Stack) Pop () interface e := stack.list.Back() if e != nil { stack.list.Remove(e) return e.Value } return nil } func (stack *Stack) Peak () interface e := stack.list.Back() if e != nil { return e.Value } return nil } func (stack *Stack) Len () int return stack.list.Len() } func (stack *Stack) Empty () bool return stack.list.Len() == 0 }
heap 字符串 Go 特意做了优化,设计了 rune,可以完美的支持多语言。
'a' 为字符 rune、"abc" 为字符串,`` 可包含复杂的字符串。
s := "我爱Go语言!" for i, ch := range []rune (s) { fmt.Printf("(%d %c)" , i, ch) } s[i] 并不是字符串,而是 uint8 ,即 ASCII 码,需要转一下 str := string (s[i])
fmt.Printf("%t\n" , 1 ==2 ) fmt.Printf("%t\n" , true ) fmt.Printf("二进制:%b\n" , 255 ) fmt.Printf("八进制:%o\n" , 255 ) fmt.Printf("十进制:%d\n" , 255 ) fmt.Printf("十六进制:%X\n" , 255 ) fmt.Printf("%c\n" , 33 ) fmt.Printf("浮点数:%f\n" , math.Pi) fmt.Printf("字符串:%s\n" , "hello world" ) fmt.Printf("%q\n" , "\"string\"" ) fmt.Printf("%p\n" , &p) fmt.Printf("类型:%T\n" , "hello world" ) fmt.Printf("字段在内的实例的完整信息:%+v\n" , "hello world" ) fmt.Printf("字段和限定类型名称在内的实例的完整信息:%#v\n" , "hello world" ) p := point{1 , 2 } fmt.Printf("%v\n" , p) fmt.Printf("%+v\n" , p) fmt.Printf("%#v\n" , p) fmt.Printf("%T\n" , p) fmt.Printf("%e\n" , 123400000.0 ) fmt.Printf("%E\n" , 123400000.0 ) fmt.Printf("%x\n" , "hex this" ) fmt.Printf("|%6d|%6d|\n" , 12 , 345 ) fmt.Printf("|%6.2f|%6.2f|\n" , 1.2 , 3.45 ) fmt.Printf("|%-6.2f|%-6.2f|\n" , 1.2 , 3.45 ) fmt.Printf("|%6s|%6s|\n" , "foo" , "b" ) fmt.Printf("|%-6s|%-6s|\n" , "foo" , "b" ) s := fmt.Sprintf("a %s" , "string" ) fmt.Println(s) fmt.Fprintf(os.Stderr, "an %s\n" , "error" )
还有对应的 strings、strconv 包。
s := "This is an example of a string.中文" println (strings.HasPrefix(s, "This" ))println (strings.HasSuffix(s, "string" ))println (strings.Contains(s, "a " ))println (strings.Index(s, "is" ))println (strings.LastIndex(s, "i" ))strings.Replace() strings.ToLower(s) string strconv.Itoa(int (item))
文件操作 f, err := os.Open('/etc/passwd' ) defer f.Close()buf := make ([]byte , 10 ) f.Read(buf) r := bufio.NewReader(f) for { str, err := r.ReadString('\n' ) if err == io.EOF { break } fmt.Printf(str) } content, err := ioutil.ReadFile('/etc/passwd' ) ioutil.ReadDir("." )
命令执行 cmd := exec.Command("id" ) stdoutStderr, err := cmd.CombinedOutput() if err != nil { log.Fatal(err) }
泛型 package mainimport "strings" import "fmt" func Index (vs []string , t string ) int for i, v := range vs { if v == t { return i } } return -1 } func Include (vs []string , t string ) bool return Index(vs, t) >= 0 } func Any (vs []string , f func (string ) bool ) bool for _, v := range vs { if f(v) { return true } } return false } func All (vs []string , f func (string ) bool ) bool for _, v := range vs { if !f(v) { return false } } return true } func Filter (vs []string , f func (string ) bool ) []string vsf := make ([]string , 0 ) for _, v := range vs { if f(v) { vsf = append (vsf, v) } } return vsf } func Map (vs []string , f func (string ) string ) []string vsm := make ([]string , len (vs)) for i, v := range vs { vsm[i] = f(v) } return vsm } func main () var strs = []string {"peach" , "apple" , "pear" , "plum" } fmt.Println(Index(strs, "pear" )) fmt.Println(Include(strs, "grape" )) fmt.Println(Any(strs, func (v string ) bool return strings.HasPrefix(v, "p" ) })) fmt.Println(All(strs, func (v string ) bool return strings.HasPrefix(v, "p" ) })) fmt.Println(Filter(strs, func (v string ) bool return strings.Contains(v, "e" ) })) fmt.Println(Map(strs, strings.ToUpper)) }
面向“对象” 仅支持封装,不支持继承和多态
结构体和方法 用大小写来区分,大写开头 public、小写开头 private,private 只能在当前包内使用(使用工厂模式解决,即自行实现(大写开头)构造函数)
type Books struct { title string author string book_id string } books := Books{ title: "Go" , author: "Tim" , book_id: "1" , } type Member struct { Id int `json:"id,-"` Name string `json:"name"` Email string `json:"email"` Gender int `json:"gender,"` Age int `json:"age"` } books = Books{"Go" , "Tim" , "2" } func (book Books) print () } func (book *Books) print () if book == nil { } } type Edu struct { Books name string }
包和封装 同一个目录下只能有一个包,main 包下为主入口
为结构定义的方法必须放在同一个包内
可以是不同文件
import 中可以使用相对路径 ./、../ 引用包,如果没有用相对路径,go 会去 $GOPATH/src/ 目录找
扩展已有类型 定义别名 使用组合 使用内嵌来扩展已有类型 依赖管理 依赖管理 GOPATH 和 GOVENDOR gopath 和 path 一样,可以接受多个路径,路径之间用冒号分隔
go mod go: cannot find main module; see ‘go help modules’
go env -w GO111MODULE=on go env -w GOPROXY=https://mirrors.aliyun.com/goproxy/,direct
go mod 子命令
go mod init module_name go list -m -u all # 检查可以升级的包 go get -u need-upgrade-package # 升级 download edit graph init tidy vendor verify why
面向接口 duck typing
“像鸭子走路,像鸭子叫,长的像鸭子,那么就是鸭子”
描述事物的外部行为而非内部结构
严格来说 go 属于结构化类型系统,类似 duck typing
Python 中的鸭子
// 运行时才知道传入的 retriever 有没有 get 方法 // 需要注释来说明接口 def download (retriever) : return retriever.get("http://qq.com" )
C++ 中的鸭子
template <class R >string download (const R & retriver ) { return retriver.get("http://qq.com" ) }
Java 中的类似代码
<R extends Retriver> String download (R r) { return r.get("http://qq.com" ) }
Go
type Retriver interface { Get(source string ) string } func download (retriver Retriver) string return retriver.Get("http://qq.com" ) }
接口的概念 接口由使用者定义
接口的实现时隐式的,只要实现里面的方法(不太理解这句话
接口本身不能创建实例,但可以指向一个实现了该接口的(自定义)类型的变量。
一个自定义类型需要将某个接口的所有方法都实现,才说这个自定义类型实现了该接口,否则编译不通过。
一个自定义类型可以实现多个接口
一个接口可以继承多个接口
interface 类型默认是一个指针
空接口 interface{} 没有任何方法,所以所有类型都实现了空接口,即可以把任何一个变量赋值给空接口。
类型断言
var x interface {}var f float32 = 1.1 x = f y := x.(float32 ) if y, ok := x.(float32 ); ok { }
继承与接口
当 A 结构体继承了 B 结构体,那么 A 就有了 B 的所有字段和方法,并可以直接调用。
当 A 结构体需要扩展功能,同时不希望破坏继承关系,实现某个接口即可。
因此,实现接口可以看做是对继承机制的补充。
继承的价值:解决代码的复用性和可维护性。
接口的价值:设计,设计好各种规范(方法),让其它自定义类型去实现这种方法。
接口比继承更加灵活,继承是满足 is-a 的关系,而接口只需满足 like-a 的关系,在一定程度上实现了解耦。
接口的定义和实现
实际上就是实现了多态,同样的方法在不同对象调用时表现不同的意义?
还有个典型的列子,即 sort(),需要实现三个方法就可以给自定义类型排序
type geometry interface { area() float64 perim() float64 } type rect struct { width, height float64 } type circle struct { radius float64 } func (r rect) area float64 return r.width * r.height } func (r rect) perim () float64 return (r.width + r.height) * 2 } func (c circle) area () float64 return math.Pi * c.radius * c.radius } func (c circle) perim () float64 return 2 * math.Pi * c.radius } func measure (g geometry) fmt.Println(g) fmt.Println(g.area()) fmt.Println(g.perim()) } func main () r := rect{width: 3 , height: 4 } c := circle{radius: 5 } measure(r) measure(c) }
接口的值类型 接口的组合 常用系统接口 函数式编程 闭包 函数内的局部变量 + 匿名函数构成闭包
func adder () func (int ) int sum := 0 return func (value int ) int sum += value return sum } }
为函数实现接口
反射 使用反射遍历结构体字段,调用结构体的方法,并获取结构体标签的值。
定义多个函数,再定义一个适配器函数用作统一处理接口。
使用反射创建并操作结构体。
错误处理和资源管理 defer 延时机制,在 return 后再调用,先 defer 的后调用。
常常需要创建资源(数据库连接、文件句柄、锁),使用 defer 来关闭更省心。
错误处理概念 服务器统一出错处理 panic 和 recover panic 一旦出错直接终止程序。
recover 可对接收到的错误自定义处理。
defer func () if err := recover (); err { println (err) } }()
哪些不能 Recover:
Thread Limit,超过了系统的线程限制,详细参考下面的说明;
Concurrent Map Writers,竞争条件,同时写 map,参考下面的例子。推荐使用标准库的 sync.Map 解决这个问题。
最佳实践 Go 的 err 过于简单,需要增加上下文信息。
package mainimport ( "fmt" ) type Handler interface { Filter(err error, r interface {}) error } type Logger interface { Ef(format string , a ...interface {}) } func HandlePanic (hdr Handler, logger Logger) error return handlePanic(recover (), hdr, logger) } type hdrFunc func (err error, r interface {}) error func (v hdrFunc) Filter (err error, r interface {}) error return v(err, r) } type loggerFunc func (format string , a ...interface {}) func (v loggerFunc) Ef (format string , a ...interface {}) v(format, a...) } func HandlePanicFunc (hdr func (err error, r interface {}) error , logger func (format string , a ...interface {}) , ) error { var f Handler if hdr != nil { f = hdrFunc(hdr) } var l Logger if logger != nil { l = loggerFunc(logger) } return handlePanic(recover (), f, l) } func handlePanic (r interface {}, hdr Handler, logger Logger) error if r != nil { err, ok := r.(error) if !ok { err = fmt.Errorf("r is %v" , r) } if hdr != nil { err = hdr.Filter(err, r) } if err != nil && logger != nil { logger.Ef("panic err %+v" , err) } return err } return nil } func main () func () defer HandlePanicFunc(nil , func (format string , a ...interface {}) fmt.Println(fmt.Sprintf(format, a...)) }) panic ("ok" ) }() logger := func (format string , a ...interface {}) fmt.Println(fmt.Sprintf(format, a...)) } func () defer HandlePanicFunc(nil , logger) panic ("ok" ) }() }
问题追踪和调试 打印日志 GDB 测试与调优 TDD 先写测试 => 尝试运行测试 => 写少量代码跑起来 => 补充完整通过测试 => 重构 => 跳到第二步
先写测试代码,编写足够的代码来使编译通过,仅此而已 。
请记住,我们要查看的是,测试是否因为合理的原因失败。
迭代!
尽你所能拆分需求是一项很重要的技能,这样你就能拥有可以工作的软件 。
在测试的支持下,将功能切分成小的功能点,并使其首尾相连顺利的运行。
敏捷开发:让它运作,使它正确,使它快速
过早的优化是万恶之源 —— Donald Knuth
单元测试 单元测试:保证项目工程质量的最有效办法。
可测试:意味着面向接口编程以及减少单个函数中包含的逻辑,使用『小方法』;
组织方式:使用 Go 语言默认的 Test 框架、开源的 suite 或者 BDD 的风格对单元测试进行合理组织;
Mock 方法:四种不同的单元测试 Mock 方法;
断言:使用社区的 testify 快速验证方法的返回值;
命名约定
测试用例文件名必须以 _test.go 结尾。
测试函数必须以 Test 开头
测试函数只接受一个 t *testing.T 参数。
import "testing" func TestHello (t *testing.T) assertCorrectMessage := func (t *testing.T, got string , want string ) t.Helper() if got != want { t.Errorf("want %q got %q" , want, got) } } t.Run("saying hello to people" , func (t *testing.T) got := Hello("wywwzj" ) want := "Hello, wywwzjj" assertCorrectMessage(t, got, want) }) t.Run("empty string defaults to 'world'" , func (t *testing.T) want := "Hello, world" got := Hello("" ) assertCorrectMessage(t, got, want) }) } func TestFib (t *testing.T) var fibTests = []struct { in int expected int }{ {1 , 1 }, {2 , 1 }, {3 , 2 }, {4 , 3 }, {5 , 5 }, {6 , 8 }, {7 , 13 }, } for _, tt := range fibTests { actual := Fib(tt.in) if actual != tt.expected { t.Errorf("Fib(%d) = %d; expected %d" , tt.in, actual, tt.expected) } } }
测试并发中的条件竞争
example 既能生成文档,也是做了一次测试。
func Example_GetScore () score := getScore(100 , 100 , 100 , 2.1 ) fmt.Println(score) }
testing 的变量 gotest 的变量有这些:
test.short : 一个快速测试的标记,在测试用例中可以使用 testing.Short () 来绕开一些测试
test.outputdir : 输出目录
test.coverprofile : 测试覆盖率参数,指定输出文件
test.run : 指定正则来运行某个 / 某些测试用例
test.memprofile : 内存分析参数,指定输出文件
test.memprofilerate : 内存分析参数,内存分析的抽样率
test.cpuprofile : cpu 分析输出参数,为空则不做 cpu 分析
test.blockprofile : 阻塞事件的分析参数,指定输出文件
test.blockprofilerate : 阻塞事件的分析参数,指定抽样频率
test.timeout : 超时时间
test.cpu : 指定 cpu 数量
test.parallel : 指定运行测试用例的并行数
testing 包内的结构
B : 压力测试
BenchmarkResult : 压力测试结果
Cover : 代码覆盖率相关结构体
CoverBlock : 代码覆盖率相关结构体
InternalBenchmark : 内部使用的结构
InternalExample : 内部使用的结构
InternalTest : 内部使用的结构
M : main 测试使用的结构
PB : Parallel benchmarks 并行测试使用结果
T : 普通测试用例
TB : 测试用例的接口
testing 的通用方法 T 结构内部是继承自 common 结构,common 结构提供集中方法,是我们经常会用到的:
当我们遇到一个断言错误的时候,我们就会判断这个测试用例失败,就会使用到:
Fail : case 失败,测试用例继续 FailedNow : case 失败,测试用例中断
当我们遇到一个断言错误,只希望跳过这个错误,但是不希望标示测试用例失败,会使用到:
SkipNow : case 跳过,测试用例不继续
当我们只希望在一个地方打印出信息,我们会用到 :
Log : 输出信息 Logf : 输出有 format 的信息
当我们希望跳过这个用例,并且打印出信息 :
Skip : Log + SkipNow Skipf : Logf + SkipNow
当我们希望断言失败的时候,测试用例失败,打印出必要的信息,但是测试用例继续:
Error : Log + Fail Errorf : Logf + Fail
当我们希望断言失败的时候,测试用例失败,打印出必要的信息,测试用例中断:
Fatal : Log + FailNow Fatalf : Logf + FailNow
基准测试 func BenchmarkHello (t testing.B) b.ResetTimer() for i := 0 ; i < b.N; i++ { Hello(); } }
测试 http 服务器 httptest server := httptest.NewServer(http.HandlerFunc(func (w http.ResponseWriter, r *http.Request) w.WriteHeader(http.StatusOK) })) server.URL
####
代码覆盖率和性能测试 pprof runtime/pprof
net/http/pprof
runtime/trace
只需在程序执行前加上环境变量 GODEBUG=gctrace=1
GODEBUG=gctrace=1 go test -bench=. GODEBUG=gctrace=1 go run main.go
生成文档和示例代码 性能调优分析指标
Wall Time
CPU Time
Block Time
Memory allocation
GC times / time spent
别让性能被锁住 高效字符串连接 字符串是不可变对象,已经生成不能改变,每次改变都是产生了一个新的字符串。
string.Builder 性能最好
var builder strings.Builderfor i := 0 ; i < b.N; i++ { builder.WriteString(strconv.Itoa(i)) } str := builder.String()
bytes.Buffer 次之
var buf bytes.Bufferfor i := 0 ; i < b.N; i++ { buf.WriteString(strconv.Itoa(i)) } str := buf.String()
+
sprintf 最慢
var s string for i := 0 ; i < b.N; i++ { s = fmt.Sprintf("%v%v" , s, i) }
GC 友好 避免内存分配和复制
复杂对象尽量传引用
复用内存
slice 初始化合适的大小。
并发编程
https://github.com/golang/go/wiki/LearnConcurrency
Go 实现了 CSP(通信顺序进程,Communicaing Sequential Process)模型来作为 goroutine 间的推荐通信方式
Goroutine MPG模式
M:操作系统的主线程(物理线程)
P:协程执行需要的上下文
G:协程
如果协程中出现了 panic,则整个程序都会崩溃。
设置运行 CPU 数量
num := runtime.NumCPU() runtime.GOMAXPROCS(233 )
channel
不要通过共享内存来通信,而应通过通信来共享内存。
类似 Unix 下的双向管道,可指定单向,用于goroutine 之间通信,可传送任意数据类型。符号为 <- chan <-。
线程安全,多 goroutine 访问时,不需要加锁,即本身就是线程安全的。
func main () channel := make (chan string ) go func () channel <- "Hello" } }
main 函数所处的是一个主 goroutine,由 runtime.main 启动。
main 函数一旦运行结束退出,其他的 goroutine 会被杀掉。
channel := make (chan int , 3 )
channel 默认是阻塞的,满了阻塞写,空了阻塞读。
获取 channel 内容可使用 range 遍历,但发送方 channel 要手动 close 一下。
queue := make (chan string , 2 ) queue <- "one" queue <- "two" close (queue)for elem := range queue { fmt.Println(elem) }
Go 中的 select
for i := 0 ; i < 2 ; i++ { select { case msg1 := <- c1: case msg2 := <- c2: } } for { timeout_cnt := 0 select { case msg1 := <- c1: case msg2 := <- c2: case <- time.After(time.Second * 30 ): timeout_cnt++ } if time_cnt > 3 { break } } for { select { case msg1 := <- c1: case msg2 := <- c2: default : } } close (channel)more := true for more { select { case msg, more = <- channel: if more { } else { } } }
var sem = make (chan int , MaxOutstanding)func handle (r *Request) sem <- 1 process(r) <-sem } func Serve (queue chan *Request) for { req := <-queue go handle(req) } } func Serve (queue chan *Request) for { req := <-queue sem <- 1 go func () process(req) <- sem }() } } func Serve (queue chan *Request) for { req := <-queue sem <- 1 go func (req *Request) process(req) <- sem }(req) } } func Serve (queue chan *Request) for req := range queue { req := req sem <- 1 go func () process(req) <- sem }() } }
理解调度器 线程池 package mainimport "fmt" import "time" func worker (id int , jobs <-chan int , results chan <- int ) for j := range jobs { fmt.Println("worker" , id, "processing job" , j) time.Sleep(time.Second) results <- j * 2 } } func main () jobs := make (chan int , 100 ) results := make (chan int , 100 ) for w := 1 ; w <= 3 ; w++ { go worker(w, jobs, results) } for j := 1 ; j <= 9 ; j++ { jobs <- j } close (jobs) for a := 1 ; a <= 9 ; a++ { <-results } }
runtime context 原子操作 这样的函数还有很多,参看 go 的 atomic 包文档
imort "sync/atomic" var cnt uint32 = 0 atomic.AddUint32(&cnt, 1) cntFinal := atomic.LoadUint32(&cnt) // 取数据
互斥锁 Mutex var memoryAccess sync.Mutexvar value int go func () memoryAccess.Lock() value++ memoryAccess.Unlock() } memoryAccess.Lock() if value == 0 { println (value) } memoryAccess.Unlock() func main () var state = make (map [int ]int ) var mutex = &sync.Mutex{} var ops int64 = 0 for r := 0 ; r < 100 ; r++ { go func () total := 0 for { key := rand.Intn(5 ) mutex.Lock() total += state[key] mutex.Unlock() atomic.AddInt64(&ops, 1 ) runtime.Gosched() } }() } for w := 0 ; w < 10 ; w++ { go func () for { key := rand.Intn(5 ) val := rand.Intn(100 ) mutex.Lock() state[key] = val mutex.Unlock() atomic.AddInt64(&ops, 1 ) runtime.Gosched() } }() } time.Sleep(time.Second) opsFinal := atomic.LoadInt64(&ops) fmt.Println("ops:" , opsFinal) mutex.Lock() fmt.Println("state:" , state) mutex.Unlock() }
读写锁 RWMutex Once 调用无数次也只执行一次。
var once sync.OnceonceBody := func () fmt.Println(time.Now()) } done := make (chan bool ) for i := 0 ; i < 10 ; i++ { go func () once.Do(onceBody) done <- true }() } for i := 0 ; i < 10 ; i++ { fmt.Println(<- done) }
WaitGroup wg := sync.WaitGroup{} wg.Add(10 ) wg.Done() wg.Wait()
竞争条件检测 go build,go run 或者 go test 命令后面加上 -race
常用库 os 尽量多用 os 提供的方法,这里的方法都是跨平台的,少用 syscall。
time package mainimport ( "fmt" "time" ) func daysBetweenDates (date1 string , date2 string ) int d1, _ := time.Parse("2006-01-02" , date1) d2, _ := time.Parse("2006-01-02" , date2) delta := d1.Sub(d2) return abs(int (delta.Hours()) / 24 ) } func main () timeString := time.Now().Format("2006-01-02 15:04:05" ) fmt.Println(timeString) fmt.Println(time.Now().Format("2017-09-07 18:05:32" )) p := fmt.Println now := time.Now() p(now) then := time.Date(2009 , 11 , 17 , 20 , 34 , 58 , 651387237 , time.UTC) p(then) p(then.Year()) p(then.Month()) p(then.Day()) p(then.Hour()) p(then.Minute()) p(then.Second()) p(then.Nanosecond()) p(then.Location()) p(then.Weekday()) p(then.Before(now)) p(then.After(now)) p(then.Equal(now)) diff := now.Sub(then) p(diff) p(diff.Hours()) p(diff.Minutes()) p(diff.Seconds()) p(diff.Nanoseconds()) p(then.Add(diff)) p(then.Add(-diff)) }
定时器 Timers timer = time.NewTimer(time.Second * 2 ) go func () <-timer.C }() timer.Stop()
打点器 Tickers 间隔一段时间发一个信号。
ticker := time.NewTicker(time.Millisecond * 500 ) go func () for t := range .ticker.C { fmt.Println("Tick at " , t) } }() ticker.Stop()
速率限制 Rate Limiting func main () requests := make (chan int , 5 ) for i := 1 ; i <= 5 ; i++ { requests <- i } close (requests) limiter := time.Tick(time.Millisecond * 200 ) for req := range requests { <-limiter fmt.Println("request" , req, time.Now()) } burstyLimiter := make (chan time.Time, 3 ) for i := 0 ; i < 3 ; i++ { burstyLimiter <- time.Now() } go func () for t := range time.Tick(time.Millisecond * 200 ) { burstyLimiter <- t } }() burstyRequests := make (chan int , 5 ) for i := 1 ; i <= 5 ; i++ { burstyRequests <- i } close (burstyRequests) for req := range burstyRequests { <-burstyLimiter fmt.Println("request" , req, time.Now()) } }
encoding import b64 "encoding/base64" import "fmt" func main () data := "abc123!?$*&()'-=@~" sEnc := b64.StdEncoding.EncodeToString([]byte (data)) fmt.Println(sEnc) sDec, _ := b64.StdEncoding.DecodeString(sEnc) fmt.Println(string (sDec)) fmt.Println() uEnc := b64.URLEncoding.EncodeToString([]byte (data)) fmt.Println(uEnc) uDec, _ := b64.URLEncoding.DecodeString(uEnc) fmt.Println(string (uDec)) }
container heap type IntHeap []int func (h IntHeap) Len () int return len (h) }func (h IntHeap) Less (i, j int ) bool return h[i] < h[j] }func (h IntHeap) Swap (i, j int ) func (h *IntHeap) Push (x interface {}) *h = append (*h, x.(int )) } func (h *IntHeap) Pop () interface old := *h n := len (old) x := old[n-1 ] *h = old[0 : n-1 ] return x } h := &IntHeap{2 , 1 , 5 } heap.Init(h) heap.Push(h, 3 ) heap.Pop(h)
list type Element struct { next, prev *Element list *List Value interface {} } type List struct { root Element len int }
package mainimport ( "container/list" "fmt" ) func main () list := list.New() list.PushBack(1 ) list.PushBack(2 ) fmt.Printf("len: %v\n" , list.Len()) fmt.Printf("first: %#v\n" , list.Front()) fmt.Printf("second: %#v\n" , list.Front().Next()) }
type Element func (e *Element) Next () *Element func (e *Element) Prev () *Element type List func New () *List func (l *List) Back () *Element // 最后一个元素 func (l *List) Front () *Element // 第一个元素 func (l *List) Init () *List // 链表初始化 func (l *List) InsertAfter (v interface {}, mark *Element) *Element // 在某个元素后插入 func (l *List) InsertBefore (v interface {}, mark *Element) *Element // 在某个元素前插入 func (l *List) Len () int // 在链表长度 func (l *List) MoveAfter (e, mark *Element) // 把 e 元素移动到 mark 之后 func (l *List) MoveBefore (e, mark *Element) // 把 e 元素移动到 mark 之前 func (l *List) MoveToBack (e *Element) // 把 e 元素移动到队列最后 func (l *List) MoveToFront (e *Element) // 把 e 元素移动到队列最头部 func (l *List) PushBack (v interface {}) *Element // 在队列最后插入元素 func (l *List) PushBackList (other *List) // 在队列最后插入接上新队列 func (l *List) PushFront (v interface {}) *Element // 在队列头部插入元素 func (l *List) PushFrontList (other *List) // 在队列头部插入接上新队列 func (l *List) Remove (e *Element) interface {}
ring type Ring struct { next, prev *Ring Value interface{} }
package mainimport ( "container/ring" "fmt" ) func main () ring := ring.New(3 ) for i := 1 ; i <= 3 ; i++ { ring.Value = i ring = ring.Next() } s := 0 ring.Do(func (p interface {}) s += p.(int ) }) fmt.Println("sum is" , s) }
type Ring func New (n int ) *Ring // 初始化环 func (r *Ring) Do (f func (interface {}) ) // 循环环进行操作 func (r *Ring) Len () int // 环长度 func (r *Ring) Link (s *Ring) *Ring // 连接两个环 func (r *Ring) Move (n int ) *Ring // 指针从当前元素开始向后移动或者向前(n 可以为负数) func (r *Ring) Next () *Ring // 当前元素的下个元素 func (r *Ring) Prev () *Ring // 当前元素的上个元素 func (r *Ring) Unlink (n int ) *Ring // 从当前元素开始,删除 n 个元素
regexp package mainimport "bytes" import "fmt" import "regexp" func main () match, _ := regexp.MatchString("p([a-z]+)ch" , "peach" ) fmt.Println(match) r, _ := regexp.Compile("p([a-z]+)ch" ) fmt.Println(r.MatchString("peach" )) fmt.Println(r.FindString("peach punch" )) fmt.Println(r.FindStringIndex("peach punch" )) fmt.Println(r.FindStringSubmatch("peach punch" )) fmt.Println(r.FindStringSubmatchIndex("peach punch" )) fmt.Println(r.FindAllString("peach punch pinch" , -1 )) fmt.Println(r.FindAllStringSubmatchIndex( "peach punch pinch" , -1 )) fmt.Println(r.FindAllString("peach punch pinch" , 2 )) fmt.Println(r.Match([]byte ("peach" ))) r = regexp.MustCompile("p([a-z]+)ch" ) fmt.Println(r) fmt.Println(r.ReplaceAllString("a peach" , "<fruit>" )) in := []byte ("a peach" ) out := r.ReplaceAllFunc(in, bytes.ToUpper) fmt.Println(string (out)) }
strings func Compare (a, b string ) int func Contains (s, substr string ) bool func ContainsAny (s, chars string ) bool func ContainsRune (s string , r rune ) bool func Count (s, substr string ) int func EqualFold (s, t string ) bool func Fields (s string ) []string func FieldsFunc (s string , f func (rune ) bool ) []string func HasPrefix (s, prefix string ) bool func HasSuffix (s, suffix string ) bool func Index (s, substr string ) int func IndexAny (s, chars string ) int func IndexByte (s string , c byte ) int func IndexFunc (s string , f func (rune ) bool ) int func IndexRune (s string , r rune ) int func Join (a []string , sep string ) string func LastIndex (s, substr string ) int func LastIndexAny (s, chars string ) int func LastIndexByte (s string , c byte ) int func LastIndexFunc (s string , f func (rune ) bool ) int func Map (mapping func (rune ) rune , s string ) string func Repeat (s string , count int ) string func Replace (s, old, new string , n int ) string func ReplaceAll (s, old, new string ) string func Split (s, sep string ) []string func SplitAfter (s, sep string ) []string func SplitAfterN (s, sep string , n int ) []string func SplitN (s, sep string , n int ) []string func Title (s string ) string func ToLower (s string ) string func ToLowerSpecial (c unicode.SpecialCase, s string ) string func ToTitle (s string ) string func ToTitleSpecial (c unicode.SpecialCase, s string ) string func ToUpper (s string ) string func ToUpperSpecial (c unicode.SpecialCase, s string ) string func ToValidUTF8 (s, replacement string ) string func Trim (s string , cutset string ) string func TrimFunc (s string , f func (rune ) bool ) string func TrimLeft (s string , cutset string ) string func TrimLeftFunc (s string , f func (rune ) bool ) string func TrimPrefix (s, prefix string ) string func TrimRight (s string , cutset string ) string func TrimRightFunc (s string , f func (rune ) bool ) string func TrimSpace (s string ) string func TrimSuffix (s, suffix string ) string type Builder func (b *Builder) Cap () int func (b *Builder) Grow (n int ) func (b *Builder) Len () int func (b *Builder) Reset () func (b *Builder) String () string func (b *Builder) Write (p []byte ) (int , error) func (b *Builder) WriteByte (c byte ) error func (b *Builder) WriteRune (r rune ) (int , error) func (b *Builder) WriteString (s string ) (int , error) type Reader func NewReader (s string ) *Reader func (r *Reader) Len () int func (r *Reader) Read (b []byte ) (n int , err error) func (r *Reader) ReadAt (b []byte , off int64 ) (n int , err error) func (r *Reader) ReadByte () (byte , error) func (r *Reader) ReadRune () (ch rune , size int , err error) func (r *Reader) Reset (s string ) func (r *Reader) Seek (offset int64 , whence int ) (int64 , error) func (r *Reader) Size () int64 func (r *Reader) UnreadByte () error func (r *Reader) UnreadRune () error func (r *Reader) WriteTo (w io.Writer) (n int64 , err error) type Replacer func NewReplacer (oldnew ...string ) *Replacer func (r *Replacer) Replace (s string ) string func (r *Replacer) WriteString (w io.Writer, s string ) (n int , err error)
bytes 操作 byte slice
func Compare (a, b []byte ) int func Contains (b, subslice []byte ) bool func ContainsAny (b []byte , chars string ) bool func ContainsRune (b []byte , r rune ) bool func Count (s, sep []byte ) int func Equal (a, b []byte ) bool func EqualFold (s, t []byte ) bool func Fields (s []byte ) [][]byte func FieldsFunc (s []byte , f func (rune ) bool ) [][]byte func HasPrefix (s, prefix []byte ) bool func HasSuffix (s, suffix []byte ) bool func Index (s, sep []byte ) int func IndexAny (s []byte , chars string ) int func IndexByte (b []byte , c byte ) int func IndexFunc (s []byte , f func (r rune ) bool ) int func IndexRune (s []byte , r rune ) int func Join (s [][]byte , sep []byte ) []byte func LastIndex (s, sep []byte ) int func LastIndexAny (s []byte , chars string ) int func LastIndexByte (s []byte , c byte ) int func LastIndexFunc (s []byte , f func (r rune ) bool ) int func Map (mapping func (r rune ) rune , s []byte ) []byte func Repeat (b []byte , count int ) []byte func Replace (s, old, new []byte , n int ) []byte func ReplaceAll (s, old, new []byte ) []byte func Runes (s []byte ) []rune func Split (s, sep []byte ) [][]byte func SplitAfter (s, sep []byte ) [][]byte func SplitAfterN (s, sep []byte , n int ) [][]byte func SplitN (s, sep []byte , n int ) [][]byte func Title (s []byte ) []byte func ToLower (s []byte ) []byte func ToLowerSpecial (c unicode.SpecialCase, s []byte ) []byte func ToTitle (s []byte ) []byte func ToTitleSpecial (c unicode.SpecialCase, s []byte ) []byte func ToUpper (s []byte ) []byte func ToUpperSpecial (c unicode.SpecialCase, s []byte ) []byte func ToValidUTF8 (s, replacement []byte ) []byte func Trim (s []byte , cutset string ) []byte func TrimFunc (s []byte , f func (r rune ) bool ) []byte func TrimLeft (s []byte , cutset string ) []byte func TrimLeftFunc (s []byte , f func (r rune ) bool ) []byte func TrimPrefix (s, prefix []byte ) []byte func TrimRight (s []byte , cutset string ) []byte func TrimRightFunc (s []byte , f func (r rune ) bool ) []byte func TrimSpace (s []byte ) []byte func TrimSuffix (s, suffix []byte ) []byte type Buffer func NewBuffer (buf []byte ) *Buffer func NewBufferString (s string ) *Buffer func (b *Buffer) Bytes () []byte func (b *Buffer) Cap () int func (b *Buffer) Grow (n int ) func (b *Buffer) Len () int func (b *Buffer) Next (n int ) []byte func (b *Buffer) Read (p []byte ) (n int , err error) func (b *Buffer) ReadByte () (byte , error) func (b *Buffer) ReadBytes (delim byte ) (line []byte , err error) func (b *Buffer) ReadFrom (r io.Reader) (n int64 , err error) func (b *Buffer) ReadRune () (r rune , size int , err error) func (b *Buffer) ReadString (delim byte ) (line string , err error) func (b *Buffer) Reset () func (b *Buffer) String () string func (b *Buffer) Truncate (n int ) func (b *Buffer) UnreadByte () error func (b *Buffer) UnreadRune () error func (b *Buffer) Write (p []byte ) (n int , err error) func (b *Buffer) WriteByte (c byte ) error func (b *Buffer) WriteRune (r rune ) (n int , err error) func (b *Buffer) WriteString (s string ) (n int , err error) func (b *Buffer) WriteTo (w io.Writer) (n int64 , err error) type Reader func NewReader (b []byte ) *Reader func (r *Reader) Len () int func (r *Reader) Read (b []byte ) (n int , err error) func (r *Reader) ReadAt (b []byte , off int64 ) (n int , err error) func (r *Reader) ReadByte () (byte , error) func (r *Reader) ReadRune () (ch rune , size int , err error) func (r *Reader) Reset (b []byte ) func (r *Reader) Seek (offset int64 , whence int ) (int64 , error) func (r *Reader) Size () int64 func (r *Reader) UnreadByte () error func (r *Reader) UnreadRune () error func (r *Reader) WriteTo (w io.Writer) (n int64 , err error)
strconv func AppendBool (dst []byte , b bool ) []byte func AppendFloat (dst []byte , f float64 , fmt byte , prec, bitSize int ) []byte func AppendInt (dst []byte , i int64 , base int ) []byte func AppendQuote (dst []byte , s string ) []byte func AppendQuoteRune (dst []byte , r rune ) []byte func AppendQuoteRuneToASCII (dst []byte , r rune ) []byte func AppendQuoteRuneToGraphic (dst []byte , r rune ) []byte func AppendQuoteToASCII (dst []byte , s string ) []byte func AppendQuoteToGraphic (dst []byte , s string ) []byte func AppendUint (dst []byte , i uint64 , base int ) []byte func Atoi (s string ) (int , error) func CanBackquote (s string ) bool func FormatBool (b bool ) string func FormatFloat (f float64 , fmt byte , prec, bitSize int ) string func FormatInt (i int64 , base int ) string func FormatUint (i uint64 , base int ) string func IsGraphic (r rune ) bool func IsPrint (r rune ) bool func Itoa (i int ) string func ParseBool (str string ) (bool , error) func ParseFloat (s string , bitSize int ) (float64 , error) func ParseInt (s string , base int , bitSize int ) (i int64 , err error) func ParseUint (s string , base int , bitSize int ) (uint64 , error) func Quote (s string ) string func QuoteRune (r rune ) string func QuoteRuneToASCII (r rune ) string func QuoteRuneToGraphic (r rune ) string func QuoteToASCII (s string ) string func QuoteToGraphic (s string ) string func Unquote (s string ) (string , error) func UnquoteChar (s string , quote byte ) (value rune , multibyte bool , tail string , err error) type NumError func (e *NumError) Error () string
casbin jwt-go cobra urfave/cli termui viper redigo grpc-go pkg/errors notify gopherjs logrus zap excelize dig fasthttp gopsutil resty GORM gonum jsoniter gofpdf Testify 写个爬虫
简单分布式爬虫,爬取相亲网站资料
工具集 开发 1)sql2go http://stming.cn/tool/sql2go.html
2)toml2go https://xuri.me/toml-to-go/
3)curl2go https://mholt.github.io/curl-to-go/
4)json2go https://mholt.github.io/json-to-go/
5) mysql 转 ES 工具 http://www.ischoolbar.com/EsParser/
6)golang https://github.com/cheekybits/genny
7) 查看某一个库的依赖情况,类似于 go list 功能 https://github.com/KyleBanks/depth
8) 一个好用的文件压缩和解压工具,集成了 zip,tar 等多种功能,主要还有跨平台。https://github.com/mholt/archiver
9) go 内置命令
10) 热编译工具 https://github.com/silenceper/gowatch
11)revive https://github.com/mgechev/revive
12)Go Callvis https://github.com/TrueFurby/go-callvis
13)Realize https://github.com/oxequa/realize
14)Gotests https://github.com/cweill/gotests
调试 1)perf https://github.com/uber-archive/go-torch https://github.com/google/gops
2) dlv 远程调试 https://github.com/go-delve/delve
3) 网络代理工具 https://github.com/snail007/goproxy
4) 抓包工具 https://github.com/40t/go-sniffer
5) 反向代理工具,快捷开放内网端口供外部使用。 https://ngrok.com/ https://github.com/inconshreveable/ngrok
6) 配置化生成证书 https://github.com/cloudflare/cfssl
7) 免费的证书获取工具 https://github.com/Neilpang/acme.sh
8) 开发环境管理工具,单机搭建可移植工具的利器。支持多种虚拟机后端。vagrant 常被拿来同 docker 相比,值得拥有。https://github.com/hashicorp/vagrant
9) 轻量级容器调度工具 https://github.com/hashicorp/nomad
10) 敏感信息和密钥管理工具 https://github.com/hashicorp/vault
11) 高度可配置化的 http 转发工具,基于 etcd 配置。 https://github.com/gojek/weaver
12) 进程监控工具 supervisor https://www.jianshu.com/p/39b476e808d8
13) 基于 procFile 进程管理工具。相比 supervisor 更加简单。https://github.com/ddollar/foreman
14) 基于 http,https,websocket 的调试代理工具 ,配置功能丰富。在线教育的 nohost web 调试工具,基于此开发.https://github.com/avwo/whistle
15) 分布式调度工具 https://github.com/shunfei/cronsun/blob/master/README_ZH.md https://github.com/ouqiang/gocron
16) 自动化运维平台 Gaia https://github.com/gaia-pipeline/gaia
网络
常用网站 go 百科全书: https://awesome-go.com/
json 解析: https://www.json.cn/
出口 IP: https://ipinfo.io/
redis 命令: http://doc.redisfans.com/
ES 命令首页: https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
UrlEncode: http://tool.chinaz.com/Tools/urlencode.aspx
Base64: https://tool.oschina.net/encrypt?type=3
Guid: https://www.guidgen.com/
常用工具: http://www.ofmonkey.com/
常用库 日志 https://github.com/Sirupsen/logrus https://github.com/uber-go/zap
配置 https://github.com/spf13/viper
存储 https://github.com/go-xorm/xorm https://github.com/elastic/elasticsearch https://github.com/gomodule/redigo https://github.com/mongodb/mongo-go-driver https://github.com/Shopify/sarama
数据结构 https://github.com/emirpasic/gods
命令行 https://github.com/spf13/cobra
框架 https://github.com/grpc/grpc-go https://github.com/gin-gonic/gin
并发 https://github.com/Jeffail/tunny https://github.com/benmanns/goworker https://github.com/rafaeldias/async
工具 https://github.com/asaskevich/govalidator https://github.com/bytedance/go-tagexpr
protobuf 文件动态解析的接口,可以实现反射相关的能力。https://github.com/jhump/protoreflect
表达式引擎工具 https://github.com/Knetic/govaluate https://github.com/google/cel-go
字符串处理 https://github.com/huandu/xstrings
ratelimit 工具 https://github.com/uber-go/ratelimit https://blog.csdn.net/chenchongg/article/details/85342086 https://github.com/juju/ratelimit
golang 熔断的库 https://github.com/afex/hystrix-go https://github.com/sony/gobreaker
表格 https://github.com/chenjiandongx/go-echarts
tail 工具库 https://github.com/hpcloud/taglshi
最佳实践 Effective Go ,Go 的语法不复杂,所以,Go 语言的最佳实践只需要看这篇官方文档就够了。
以下是在实际开发过程中遇到的一些问题,仅供参考:
异常处理统一使用 error,不要使用 panic/recover 来模拟 throw…catch,最初我是这么做的,后来发现这完全是自以为是的做法。
原生的 error 过于简单,而在实际的 API 开发过程中,不同的异常情况需要附带不同的返回码,基于此,有必要对 error 再进行一层封装。
任何协程逻辑执行体,逻辑最开始处必须要有 defer recover () 异常恢复处理,否则 goroutine 内出现的 panic,将导致整个进程宕掉,需要避免部分逻辑 BUG 造成全局影响。
在 Golang 中,变量 (chan 类型除外) 的操作是非线程安全的,也包括像 int 这样的基本类型,因此并发操作全局变量时一定要考虑加锁,特别是对 map 的并发操作。
所有对 map 键值的获取,都应该判断存在性,最好是对同类操作进行统一封装,避免出现不必要的运行时异常。
定义 slice 数据类型时,尽量预设长度,避免内部出现不必要的数据重组。
代码规范 Go 语言比较常见并且使用广泛的代码规范就是官方提供的 Go Code Review Comments ,无论你是短期还是长期使用 Go 语言编程,都应该至少完整地阅读一遍这个官方的代码规范指南 ,它既是我们在写代码时应该遵守的规则,也是在代码审查时需要注意的规范。
goimports goimports 是 Go 语言官方提供的工具,它能够为我们自动格式化 Go 语言代码并对所有引入的包进行管理,包括自动增删依赖的包引用、将依赖包按字母序排序并分类。相信很多人使用的 IDE 都会将另一个官方提供的工具 gofmt 对代码进行格式化,而 goimports 就是等于 gofmt 加上依赖包管理。
golint 在基础库或者框架中使用 golint 进行静态检查(或者同时使用 golint 和 golangci-lint ),在其他的项目中使用可定制化的 golangci-lint 来进行静态检查,因为在基础库和框架中施加强限制对于整体的代码质量有着更大的收益。
目录结构 https://github.com/golang-standards/project-layout
├── LICENSE.md ├── Makefile ├── README.md ├── api ├── assets ├── build ├── cmd ├── configs ├── deployments ├── docs ├── examples ├── githooks ├── init ├── internal ├── pkg ├── scripts ├── test ├── third_party ├── tools ├── vendor ├── web └── website
模块拆分 显式与隐式 面向接口 面试题
聊聊 GPM?
go 的 new 和 make 区别
go 怎么从源码编译到二进制文件
go 的调度模型
go 的锁如何实现,用了什么 cpu 指令
go 的 runtime 如何实现
看过 sql 的连接池实现吗
c++ 的 map 和 go 的 map 的区别(红黑树和 hashtable)
ctx 包了解吗?有什么用?
go 什么情况下会发生内存泄漏?(他说 ctx 没有 cancel 的时候,这个真不知道)
怎么实现协程完美退出?
智力题:1000 瓶酒中有 1 瓶毒酒,10 只老鼠,7 天后毒性才发作,第 8 天要卖了,怎么求那瓶毒酒?
简单 dp 题,n*n 矩阵从左上角到右下角有多少种走法(只限往下和往右走)
用 channel 实现定时器?(实际上是两个协程同步)
channel 的实现?
go 为什么高并发好?讲了 go 的调度模型
操作系统内存管理?进程通讯,为什么共享存储区效率最高
实现一个 hashmap,解决 hash 冲突的方法,解决 hash 倾斜的方法
c++ 的模板跟 go 的 interface 的区别
怎么理解 go 的 interface
go 代码运行结果(闭包函数)
git 和 svn 区别,模型
唯一订单号问题,并发量高的话怎么解决
hash 表设计要注意什么问题
数组和为 n 的数组对
lru 实现
多个线程读,一个线程写一个 int32 会不会有问题,int64 呢(这里面试官后来说了要看数据总线的位数,32 位的话写 int32 没问题,int64 就有问题)
GO 语言中的协程与 Python 中的协程的区别? 主要讲解 Go 中 GMP 机制
杂项 go doc json // 输出 json 包对应的文档
跨平台编译 GOOS=darwin GOARCH=amd64 go build GOOS=windows GOARCH=amd64 go build
go get 被墙 export http_proxy=socks5://127.0.0.1:1080 GitHub 上有官方镜像库,如 https://github.com/golang/net 即 https://golang.org/x/net git clone https://github.com/golang/tools.git # 然后进对应目录 go install,bin 目录就有了。 go install github/xxx/xxx # go mod 优先使用镜像 go env -w GOPROXY=https://mirrors.aliyun.com/goproxy/
随机数 package mainimport "time" import "fmt" import "math/rand" func main () fmt.Print(rand.Intn(100 ), "," ) fmt.Print(rand.Intn(100 )) fmt.Println() fmt.Println(rand.Float64()) fmt.Print((rand.Float64()*5 )+5 , "," ) fmt.Print((rand.Float64() * 5 ) + 5 ) fmt.Println() s1 := rand.NewSource(time.Now().UnixNano()) r1 := rand.New(s1) fmt.Print(r1.Intn(100 ), "," ) fmt.Print(r1.Intn(100 )) fmt.Println() s2 := rand.NewSource(42 ) r2 := rand.New(s2) fmt.Print(r2.Intn(100 ), "," ) fmt.Print(r2.Intn(100 )) fmt.Println() s3 := rand.NewSource(42 ) r3 := rand.New(s3) fmt.Print(r3.Intn(100 ), "," ) fmt.Print(r3.Intn(100 )) }
Tricks 如何声明一个最大的int和uint常量? const MaxUint = ^uint (0 )const MaxInt = int (^uint (0 ) >> 1 )
如何在编译时刻决定系统原生字的尺寸? 这个技巧和Go无关。
const Is64bitArch = ^uint (0 ) >> 63 == 1 const Is32bitArch = ^uint (0 ) >> 63 == 0 const WordBits = 32 << (^uint (0 ) >> 63 )
使用闭包进行调试 当您在分析和调试复杂的程序时,无数个函数在不同的代码文件中相互调用,如果这时候能够准确地知道哪个文件中的具体哪个函数正在执行,对于调试是十分有帮助的。您可以使用 runtime 或 log 包中的特殊函数来实现这样的功能。包 runtime 中的函数 Caller() 提供了相应的信息,因此可以在需要的时候实现一个 where() 闭包函数来打印函数执行的位置:
where := func () _, file, line, _ := runtime.Caller(1 ) log.Printf("%s:%d" , file, line) } where() where() where()
log.SetFlags(log.Llongfile) log.Print("") var where = log.Print func func1() { where() ... some code where() ... some code where() }