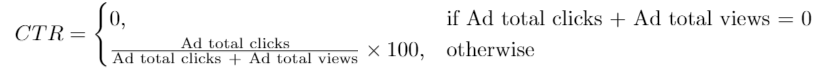业精于勤荒于嬉,持续更新中。
没时间做了,要好好搬砖了。
简单 SQL架构
Create table If Not Exists Employees (id int , name varchar (20 ))Create table If Not Exists EmployeeUNI (id int , unique_id int )Truncate table Employeesinsert into Employees (id , name ) values ('1' , 'Alice' )insert into Employees (id , name ) values ('7' , 'Bob' )insert into Employees (id , name ) values ('11' , 'Meir' )insert into Employees (id , name ) values ('90' , 'Winston' )insert into Employees (id , name ) values ('3' , 'Jonathan' )Truncate table EmployeeUNIinsert into EmployeeUNI (id , unique_id) values ('3' , '1' )insert into EmployeeUNI (id , unique_id) values ('11' , '2' )insert into EmployeeUNI (id , unique_id) values ('90' , '3' )
Employees 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | +---------------+---------+ id 是这张表的主键。 这张表的每一行分别代表了某公司其中一位员工的名字和 ID 。
EmployeeUNI 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | unique_id | int | +---------------+---------+ (id, unique_id) 是这张表的主键。 这张表的每一行包含了该公司某位员工的 ID 和他的唯一标识码(unique ID)。
写一段SQL查询来展示每位用户的 唯一标识码(unique ID ) ;如果某位员工没有唯一标识码,使用 null 填充即可。你可以以 任意 顺序返回结果表。查询结果的格式如下例所示:
Employees table: +----+----------+ | id | name | +----+----------+ | 1 | Alice | | 7 | Bob | | 11 | Meir | | 90 | Winston | | 3 | Jonathan | +----+----------+ EmployeeUNI table: +----+-----------+ | id | unique_id | +----+-----------+ | 3 | 1 | | 11 | 2 | | 90 | 3 | +----+-----------+ EmployeeUNI table: +-----------+----------+ | unique_id | name | +-----------+----------+ | null | Alice | | null | Bob | | 2 | Meir | | 3 | Winston | | 1 | Jonathan | +-----------+----------+ Alice and Bob 没有唯一标识码, 因此我们使用 null 替代。 Meir 的唯一标识码是 2 。 Winston 的唯一标识码是 3 。 Jonathan 唯一标识码是 1 。
解答 select unique_id, name from Employeesleft join EmployeeUNIon Employees.id = EmployeeUNI.id;
SQL架构
Create table If Not Exists Departments (id int , name varchar (30 ))Create table If Not Exists Students (id int , name varchar (30 ), department_id int )Truncate table Departmentsinsert into Departments (id , name ) values ('1' , 'Electrical Engineering' )insert into Departments (id , name ) values ('7' , 'Computer Engineering' )insert into Departments (id , name ) values ('13' , 'Bussiness Administration' )Truncate table Studentsinsert into Students (id , name , department_id) values ('23' , 'Alice' , '1' )insert into Students (id , name , department_id) values ('1' , 'Bob' , '7' )insert into Students (id , name , department_id) values ('5' , 'Jennifer' , '13' )insert into Students (id , name , department_id) values ('2' , 'John' , '14' )insert into Students (id , name , department_id) values ('4' , 'Jasmine' , '77' )insert into Students (id , name , department_id) values ('3' , 'Steve' , '74' )insert into Students (id , name , department_id) values ('6' , 'Luis' , '1' )insert into Students (id , name , department_id) values ('8' , 'Jonathan' , '7' )insert into Students (id , name , department_id) values ('7' , 'Daiana' , '33' )insert into Students (id , name , department_id) values ('11' , 'Madelynn' , '1' )
院系表: Departments
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | +---------------+---------+ id 是该表的主键 该表包含一所大学每个院系的 id 信息
学生表: Students
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | | department_id | int | +---------------+---------+ id 是该表的主键 该表包含一所大学每个学生的 id 和他/她就读的院系信息
写一条 SQL 语句以查询那些所在院系不存在的学生的 id 和姓名。
可以以任何顺序返回结果,下面是返回结果格式的例子
Departments 表: +------+--------------------------+ | id | name | +------+--------------------------+ | 1 | Electrical Engineering | | 7 | Computer Engineering | | 13 | Bussiness Administration | +------+--------------------------+ Students 表: +------+----------+---------------+ | id | name | department_id | +------+----------+---------------+ | 23 | Alice | 1 | | 1 | Bob | 7 | | 5 | Jennifer | 13 | | 2 | John | 14 | | 4 | Jasmine | 77 | | 3 | Steve | 74 | | 6 | Luis | 1 | | 8 | Jonathan | 7 | | 7 | Daiana | 33 | | 11 | Madelynn | 1 | +------+----------+---------------+ 结果表: +------+----------+ | id | name | +------+----------+ | 2 | John | | 7 | Daiana | | 4 | Jasmine | | 3 | Steve | +------+----------+ John, Daiana, Steve 和 Jasmine 所在的院系分别是 14, 33, 74 和 77, 其中 14, 33, 74 和 77 并不存在于院系表
解答 select id , `name` from Studentswhere department_id not in ( select id from Departments)
SQL架构
Create table Sales (sale_id int , product_id int , year int , quantity int , price int )Create table Product (product_id int , product_name varchar (10 ))Truncate table Salesinsert into Sales (sale_id, product_id, year , quantity, price) values ('1' , '100' , '2008' , '10' , '5000' )insert into Sales (sale_id, product_id, year , quantity, price) values ('2' , '100' , '2009' , '12' , '5000' )insert into Sales (sale_id, product_id, year , quantity, price) values ('7' , '200' , '2011' , '15' , '9000' )Truncate table Productinsert into Product (product_id, product_name) values ('100' , 'Nokia' )insert into Product (product_id, product_name) values ('200' , 'Apple' )insert into Product (product_id, product_name) values ('300' , 'Samsung' )
销售表 Sales:
+-------------+-------+ | Column Name | Type | +-------------+-------+ | sale_id | int | | product_id | int | | year | int | | quantity | int | | price | int | +-------------+-------+ (sale_id, year) 是销售表 Sales 的主键. product_id 是产品表 Product 的外键. 注意: price 表示每单位价格
产品表 Product:
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | +--------------+---------+ product_id 是表的主键.
写一条SQL 查询语句获取产品表 Product 中所有的 产品名称 product name 以及 该产品在 Sales 表中相对应的 上市年份 year 和 价格 price 。
示例:
Sales 表: +---------+------------+------+----------+-------+ | sale_id | product_id | year | quantity | price | +---------+------------+------+----------+-------+ | 1 | 100 | 2008 | 10 | 5000 | | 2 | 100 | 2009 | 12 | 5000 | | 7 | 200 | 2011 | 15 | 9000 | +---------+------------+------+----------+-------+ Product 表: +------------+--------------+ | product_id | product_name | +------------+--------------+ | 100 | Nokia | | 200 | Apple | | 300 | Samsung | +------------+--------------+ Result 表: +--------------+-------+-------+ | product_name | year | price | +--------------+-------+-------+ | Nokia | 2008 | 5000 | | Nokia | 2009 | 5000 | | Apple | 2011 | 9000 | +--------------+-------+-------+
解答 select product_name, `year` , pricefrom Sales sjoin Product p on s.product_id = p.product_id;select product_name, `year` , pricefrom Sales sjoin Product using (product_id);
SQL架构
Create table If Not Exists Employee (employee_id int , team_id int )Truncate table Employeeinsert into Employee (employee_id, team_id) values ('1' , '8' )insert into Employee (employee_id, team_id) values ('2' , '8' )insert into Employee (employee_id, team_id) values ('3' , '8' )insert into Employee (employee_id, team_id) values ('4' , '7' )insert into Employee (employee_id, team_id) values ('5' , '9' )insert into Employee (employee_id, team_id) values ('6' , '9' )
员工表:Employee
+---------------+---------+ | Column Name | Type | +---------------+---------+ | employee_id | int | | team_id | int | +---------------+---------+ employee_id 字段是这张表的主键,表中的每一行都包含每个员工的 ID 和他们所属的团队。
编写一个 SQL 查询,以求得每个员工所在团队的总人数。
查询结果中的顺序无特定要求。查询结果格式示例如下:
Employee Table: +-------------+------------+ | employee_id | team_id | +-------------+------------+ | 1 | 8 | | 2 | 8 | | 3 | 8 | | 4 | 7 | | 5 | 9 | | 6 | 9 | +-------------+------------+ Result table: +-------------+------------+ | employee_id | team_size | +-------------+------------+ | 1 | 3 | | 2 | 3 | | 3 | 3 | | 4 | 1 | | 5 | 2 | | 6 | 2 | +-------------+------------+ ID 为 1、2、3 的员工是 team_id 为 8 的团队的成员, ID 为 4 的员工是 team_id 为 7 的团队的成员, ID 为 5、6 的员工是 team_id 为 9 的团队的成员。
解答 select a.employee_id, b.team_sizefrom Employee ajoin (select team_id, count (employee_id) team_size from Employee group by team_id) bon a.team_id = b.team_id
SQL架构
Create table Sales (sale_id int , product_id int , year int , quantity int , price int )Create table Product (product_id int , product_name varchar (10 ))Truncate table Salesinsert into Sales (sale_id, product_id, year , quantity, price) values ('1' , '100' , '2008' , '10' , '5000' )insert into Sales (sale_id, product_id, year , quantity, price) values ('2' , '100' , '2009' , '12' , '5000' )insert into Sales (sale_id, product_id, year , quantity, price) values ('7' , '200' , '2011' , '15' , '9000' )Truncate table Productinsert into Product (product_id, product_name) values ('100' , 'Nokia' )insert into Product (product_id, product_name) values ('200' , 'Apple' )insert into Product (product_id, product_name) values ('300' , 'Samsung' )
销售表:Sales
+-------------+-------+ | Column Name | Type | +-------------+-------+ | sale_id | int | | product_id | int | | year | int | | quantity | int | | price | int | +-------------+-------+ sale_id 是这个表的主键。 product_id 是 Product 表的外键。 请注意价格是每单位的。
产品表:Product
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | +--------------+---------+ product_id 是这个表的主键。
编写一个 SQL 查询,按产品 id product_id 来统计每个产品的销售总量。
查询结果格式如下面例子所示:
Sales 表: +---------+------------+------+----------+-------+ | sale_id | product_id | year | quantity | price | +---------+------------+------+----------+-------+ | 1 | 100 | 2008 | 10 | 5000 | | 2 | 100 | 2009 | 12 | 5000 | | 7 | 200 | 2011 | 15 | 9000 | +---------+------------+------+----------+-------+ Product 表: +------------+--------------+ | product_id | product_name | +------------+--------------+ | 100 | Nokia | | 200 | Apple | | 300 | Samsung | +------------+--------------+ Result 表: +--------------+----------------+ | product_id | total_quantity | +--------------+----------------+ | 100 | 22 | | 200 | 15 | +--------------+----------------+
解答 select product_id, sum (quantity) total_quantityfrom Salesgroup by product_idselect product_id, product_name, sum (quantity) total_quantityfrom Salesjoin Product using (product_id)group by product_id
SQL架构
CREATE TABLE If Not Exists point (x INT NOT NULL , UNIQUE INDEX x_UNIQUE (x ASC ))Truncate table pointinsert into point (x) values ('-1' )insert into point (x) values ('0' )insert into point (x) values ('2' )
表 point 保存了一些点在 x 轴上的坐标,这些坐标都是整数。
写一个查询语句,找到这些点中最近两个点之间的距离。
| x | |-----| | -1 | | 0 | | 2 |
最近距离显然是 ‘1’ ,是点 ‘-1’ 和 ‘0’ 之间的距离。所以输出应该如下:
| shortest| |---------| | 1 |
注意: 每个点都与其他点坐标不同,表 table 不会有重复坐标出现。
进阶: 如果这些点在 x 轴上从左到右都有一个编号,输出结果时需要输出最近点对的编号呢?
解答 select min (abs (p1.x - p2.x)) shortestfrom point p1, point p2where p1.x != p2.x
SQL架构
Create table If Not Exists Person (Id int , Email varchar (255 ))Truncate table Personinsert into Person (Id , Email) values ('1' , 'a@b.com' )insert into Person (Id , Email) values ('2' , 'c@d.com' )insert into Person (Id , Email) values ('3' , 'a@b.com' )
编写一个 SQL 查询,查找 Person 表中所有重复的电子邮箱。
示例:
+----+---------+ | Id | Email | +----+---------+ | 1 | a@b.com | | 2 | c@d.com | | 3 | a@b.com | +----+---------+
根据以上输入,你的查询应返回以下结果:
+---------+ | Email | +---------+ | a@b.com | +---------+
说明: 所有电子邮箱都是小写字母。
解答 select Emailfrom Persongroup by Emailhaving count (Email) > 1 ;
SQL架构
Create table If Not Exists World (name varchar (255 ), continent varchar (255 ), area int , population int , gdp int )Truncate table Worldinsert into World (name , continent, area, population, gdp) values ('Afghanistan' , 'Asia' , '652230' , '25500100' , '20343000000' )insert into World (name , continent, area, population, gdp) values ('Albania' , 'Europe' , '28748' , '2831741' , '12960000000' )insert into World (name , continent, area, population, gdp) values ('Algeria' , 'Africa' , '2381741' , '37100000' , '188681000000' )insert into World (name , continent, area, population, gdp) values ('Andorra' , 'Europe' , '468' , '78115' , '3712000000' )insert into World (name , continent, area, population, gdp) values ('Angola' , 'Africa' , '1246700' , '20609294' , '100990000000' )
这里有张 World 表
+-----------------+------------+------------+--------------+---------------+ | name | continent | area | population | gdp | +-----------------+------------+------------+--------------+---------------+ | Afghanistan | Asia | 652230 | 25500100 | 20343000 | | Albania | Europe | 28748 | 2831741 | 12960000 | | Algeria | Africa | 2381741 | 37100000 | 188681000 | | Andorra | Europe | 468 | 78115 | 3712000 | | Angola | Africa | 1246700 | 20609294 | 100990000 | +-----------------+------------+------------+--------------+---------------+
如果一个国家的面积超过300万平方公里,或者人口超过2500万,那么这个国家就是大国家。
编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
例如,根据上表,我们应该输出:
+--------------+-------------+--------------+ | name | population | area | +--------------+-------------+--------------+ | Afghanistan | 25500100 | 652230 | | Algeria | 37100000 | 2381741 | +--------------+-------------+--------------+
解答 select `name` , population, `area` from Worldwhere population > 25000000 or `area` > 3000000 ;
SQL架构
Create table If Not Exists Prices (product_id int , start_date date , end_date date , price int )Create table If Not Exists UnitsSold (product_id int , purchase_date date , units int )Truncate table Pricesinsert into Prices (product_id, start_date, end_date, price) values ('1' , '2019-02-17' , '2019-02-28' , '5' )insert into Prices (product_id, start_date, end_date, price) values ('1' , '2019-03-01' , '2019-03-22' , '20' )insert into Prices (product_id, start_date, end_date, price) values ('2' , '2019-02-01' , '2019-02-20' , '15' )insert into Prices (product_id, start_date, end_date, price) values ('2' , '2019-02-21' , '2019-03-31' , '30' )Truncate table UnitsSoldinsert into UnitsSold (product_id, purchase_date, units) values ('1' , '2019-02-25' , '100' )insert into UnitsSold (product_id, purchase_date, units) values ('1' , '2019-03-01' , '15' )insert into UnitsSold (product_id, purchase_date, units) values ('2' , '2019-02-10' , '200' )insert into UnitsSold (product_id, purchase_date, units) values ('2' , '2019-03-22' , '30' )
Table: Prices
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | start_date | date | | end_date | date | | price | int | +---------------+---------+ (product_id,start_date,end_date) 是 Prices 表的主键。 Prices 表的每一行表示的是某个产品在一段时期内的价格。 每个产品的对应时间段是不会重叠的,这也意味着同一个产品的价格时段不会出现交叉。
Table: UnitsSold
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | purchase_date | date | | units | int | +---------------+---------+ UnitsSold 表没有主键,它可能包含重复项。 UnitsSold 表的每一行表示的是每种产品的出售日期,单位和产品 id。
编写SQL查询以查找每种产品的平均售价。 average_price 应该四舍五入到小数点后两位。
查询结果格式如下例所示:
Prices table: +------------+------------+------------+--------+ | product_id | start_date | end_date | price | +------------+------------+------------+--------+ | 1 | 2019-02-17 | 2019-02-28 | 5 | | 1 | 2019-03-01 | 2019-03-22 | 20 | | 2 | 2019-02-01 | 2019-02-20 | 15 | | 2 | 2019-02-21 | 2019-03-31 | 30 | +------------+------------+------------+--------+ UnitsSold table: +------------+---------------+-------+ | product_id | purchase_date | units | +------------+---------------+-------+ | 1 | 2019-02-25 | 100 | | 1 | 2019-03-01 | 15 | | 2 | 2019-02-10 | 200 | | 2 | 2019-03-22 | 30 | +------------+---------------+-------+ Result table: +------------+---------------+ | product_id | average_price | +------------+---------------+ | 1 | 6.96 | | 2 | 16.96 | +------------+---------------+ 平均售价 = 产品总价 / 销售的产品数量。 产品 1 的平均售价 = ((100 * 5)+(15 * 20) )/ 115 = 6.96 产品 2 的平均售价 = ((200 * 15)+(30 * 30) )/ 230 = 16.96
解答 先查出当时候的价格,再总的进行处理。
select product_id, round (sum (price*units)/sum (units), 2 ) average_price from ( select u.product_id product_id, price, units from UnitsSold u left join Prices p on p.product_id=u.product_id and u.purchase_date >= p.start_date and u.purchase_date <= p.end_date ) res group by product_id;
SQL架构
CREATE TABLE IF NOT EXISTS customer (id INT ,name VARCHAR (25 ),referee_id INT );Truncate table customerinsert into customer (id , name , referee_id) values ('1' , 'Will' , 'None' )insert into customer (id , name , referee_id) values ('2' , 'Jane' , 'None' )insert into customer (id , name , referee_id) values ('3' , 'Alex' , '2' )insert into customer (id , name , referee_id) values ('4' , 'Bill' , 'None' )insert into customer (id , name , referee_id) values ('5' , 'Zack' , '1' )insert into customer (id , name , referee_id) values ('6' , 'Mark' , '2' )
给定表 customer ,里面保存了所有客户信息和他们的推荐人。
+------+------+-----------+ | id | name | referee_id| +------+------+-----------+ | 1 | Will | NULL | | 2 | Jane | NULL | | 3 | Alex | 2 | | 4 | Bill | NULL | | 5 | Zack | 1 | | 6 | Mark | 2 | +------+------+-----------+
写一个查询语句,返回一个编号列表,列表中编号的推荐人的编号都 不是 2。
对于上面的示例数据,结果为:
+------+ | name | +------+ | Will | | Jane | | Bill | | Zack | +------+
解答 select name from customerwhere referee_id != 2 or referee_id is null ;
SQL架构
create table if not exists salary(id int , name varchar (100 ), sex char (1 ), salary int )Truncate table salaryinsert into salary (id , name , sex, salary) values ('1' , 'A' , 'm' , '2500' )insert into salary (id , name , sex, salary) values ('2' , 'B' , 'f' , '1500' )insert into salary (id , name , sex, salary) values ('3' , 'C' , 'm' , '5500' )insert into salary (id , name , sex, salary) values ('4' , 'D' , 'f' , '500' )
给定一个 salary 表,如下所示,有 m = 男性 和 f = 女性 的值。交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求只使用一个更新(Update)语句,并且没有中间的临时表。
注意,您必只能写一个 Update 语句,请不要编写任何 Select 语句。
例如:
| id | name | sex | salary | |----|------|-----|--------| | 1 | A | m | 2500 | | 2 | B | f | 1500 | | 3 | C | m | 5500 | | 4 | D | f | 500 |
运行你所编写的更新语句之后,将会得到以下表:
| id | name | sex | salary | |----|------|-----|--------| | 1 | A | f | 2500 | | 2 | B | m | 1500 | | 3 | C | f | 5500 | | 4 | D | m | 500 |
解答 update salary set sex = if (sex='m' , 'f' , 'm' );
SQL架构
Create table If Not Exists Delivery (delivery_id int , customer_id int , order_date date , customer_pref_delivery_date date )Truncate table Deliveryinsert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('1' , '1' , '2019-08-01' , '2019-08-02' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('2' , '5' , '2019-08-02' , '2019-08-02' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('3' , '1' , '2019-08-11' , '2019-08-11' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('4' , '3' , '2019-08-24' , '2019-08-26' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('5' , '4' , '2019-08-21' , '2019-08-22' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('6' , '2' , '2019-08-11' , '2019-08-13' )
配送表: Delivery
+-----------------------------+---------+ | Column Name | Type | +-----------------------------+---------+ | delivery_id | int | | customer_id | int | | order_date | date | | customer_pref_delivery_date | date | +-----------------------------+---------+ delivery_id 是表的主键。 该表保存着顾客的食物配送信息,顾客在某个日期下了订单,并指定了一个期望的配送日期(和下单日期相同或者在那之后)。
如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。
写一条 SQL 查询语句获取即时订单所占的比例, 保留两位小数。
查询结果如下所示:
Delivery 表: +-------------+-------------+------------+-----------------------------+ | delivery_id | customer_id | order_date | customer_pref_delivery_date | +-------------+-------------+------------+-----------------------------+ | 1 | 1 | 2019-08-01 | 2019-08-02 | | 2 | 5 | 2019-08-02 | 2019-08-02 | | 3 | 1 | 2019-08-11 | 2019-08-11 | | 4 | 3 | 2019-08-24 | 2019-08-26 | | 5 | 4 | 2019-08-21 | 2019-08-22 | | 6 | 2 | 2019-08-11 | 2019-08-13 | +-------------+-------------+------------+-----------------------------+ Result 表: +----------------------+ | immediate_percentage | +----------------------+ | 33.33 | +----------------------+ 2 和 3 号订单为即时订单,其他的为计划订单。
解答 select round (sum (if (order_date = customer_pref_delivery_date, 1 , 0 ))/count (delivery_id)*100 , 2 ) immediate_percentagefrom Delivery
SQL架构
Create table If Not Exists cinema (id int , movie varchar (255 ), description varchar (255 ), rating float (2 , 1 ))Truncate table cinemainsert into cinema (id , movie, description, rating) values ('1' , 'War' , 'great 3D' , '8.9' )insert into cinema (id , movie, description, rating) values ('2' , 'Science' , 'fiction' , '8.5' )insert into cinema (id , movie, description, rating) values ('3' , 'irish' , 'boring' , '6.2' )insert into cinema (id , movie, description, rating) values ('4' , 'Ice song' , 'Fantacy' , '8.6' )insert into cinema (id , movie, description, rating) values ('5' , 'House card' , 'Interesting' , '9.1' )
某城市开了一家新的电影院,吸引了很多人过来看电影。该电影院特别注意用户体验,专门有个 LED显示板做电影推荐,上面公布着影评和相关电影描述。
作为该电影院的信息部主管,您需要编写一个 SQL查询,找出所有影片描述为非 boring (不无聊) 的并且 id 为奇数 的影片,结果请按等级 rating 排列。
例如,下表 cinema:
+---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 1 | War | great 3D | 8.9 | | 2 | Science | fiction | 8.5 | | 3 | irish | boring | 6.2 | | 4 | Ice song | Fantacy | 8.6 | | 5 | House card| Interesting| 9.1 | +---------+-----------+--------------+-----------+
对于上面的例子,则正确的输出是为:
+---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 5 | House card| Interesting| 9.1 | | 1 | War | great 3D | 8.9 | +---------+-----------+--------------+-----------+
解答 select *from cinemawhere description != 'boring' and mod (id , 2 ) = 1 order by rating desc
SQL架构
Create table If Not Exists Views (article_id int , author_id int , viewer_id int , view_date date )Truncate table Viewsinsert into Views (article_id, author_id, viewer_id, view_date) values ('1' , '3' , '5' , '2019-08-01' )insert into Views (article_id, author_id, viewer_id, view_date) values ('1' , '3' , '6' , '2019-08-02' )insert into Views (article_id, author_id, viewer_id, view_date) values ('2' , '7' , '7' , '2019-08-01' )insert into Views (article_id, author_id, viewer_id, view_date) values ('2' , '7' , '6' , '2019-08-02' )insert into Views (article_id, author_id, viewer_id, view_date) values ('4' , '7' , '1' , '2019-07-22' )insert into Views (article_id, author_id, viewer_id, view_date) values ('3' , '4' , '4' , '2019-07-21' )insert into Views (article_id, author_id, viewer_id, view_date) values ('3' , '4' , '4' , '2019-07-21' )
Views 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | article_id | int | | author_id | int | | viewer_id | int | | view_date | date | +---------------+---------+ 此表无主键,因此可能会存在重复行。 此表的每一行都表示某人在某天浏览了某位作者的某篇文章。 请注意,同一人的 author_id 和 viewer_id 是相同的。
请编写一条 SQL 查询以找出所有浏览过自己文章的作者,结果按照 id 升序排列。查询结果的格式如下所示:
Views 表: +------------+-----------+-----------+------------+ | article_id | author_id | viewer_id | view_date | +------------+-----------+-----------+------------+ | 1 | 3 | 5 | 2019-08-01 | | 1 | 3 | 6 | 2019-08-02 | | 2 | 7 | 7 | 2019-08-01 | | 2 | 7 | 6 | 2019-08-02 | | 4 | 7 | 1 | 2019-07-22 | | 3 | 4 | 4 | 2019-07-21 | | 3 | 4 | 4 | 2019-07-21 | +------------+-----------+-----------+------------+ 结果表: +------+ | id | +------+ | 4 | | 7 | +------+
解答 select distinct author_id id from Viewswhere author_id = viewer_idorder by id
SQL架构
Create table If Not Exists Product (product_id int , product_name varchar (10 ), unit_price int )Create table If Not Exists Sales (seller_id int , product_id int , buyer_id int , sale_date date , quantity int , price int )Truncate table Productinsert into Product (product_id, product_name, unit_price) values ('1' , 'S8' , '1000' )insert into Product (product_id, product_name, unit_price) values ('2' , 'G4' , '800' )insert into Product (product_id, product_name, unit_price) values ('3' , 'iPhone' , '1400' )Truncate table Salesinsert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('1' , '1' , '1' , '2019-01-21' , '2' , '2000' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('1' , '2' , '2' , '2019-02-17' , '1' , '800' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('2' , '2' , '3' , '2019-06-02' , '1' , '800' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('3' , '3' , '4' , '2019-05-13' , '2' , '2800' )
产品表:Product
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | | unit_price | int | +--------------+---------+ product_id 是这个表的主键.
销售表:Sales
+-------------+---------+ | Column Name | Type | +-------------+---------+ | seller_id | int | | product_id | int | | buyer_id | int | | sale_date | date | | quantity | int | | price | int | +------ ------+---------+ 这个表没有主键,它可以有重复的行. product_id 是 Product 表的外键.
编写一个 SQL 查询,查询总销售额最高的销售者,如果有并列的,就都展示出来。
查询结果格式如下所示:
Product 表: +------------+--------------+------------+ | product_id | product_name | unit_price | +------------+--------------+------------+ | 1 | S8 | 1000 | | 2 | G4 | 800 | | 3 | iPhone | 1400 | +------------+--------------+------------+ Sales 表: +-----------+------------+----------+------------+----------+-------+ | seller_id | product_id | buyer_id | sale_date | quantity | price | +-----------+------------+----------+------------+----------+-------+ | 1 | 1 | 1 | 2019-01-21 | 2 | 2000 | | 1 | 2 | 2 | 2019-02-17 | 1 | 800 | | 2 | 2 | 3 | 2019-06-02 | 1 | 800 | | 3 | 3 | 4 | 2019-05-13 | 2 | 2800 | +-----------+------------+----------+------------+----------+-------+ Result 表: +-------------+ | seller_id | +-------------+ | 1 | | 3 | +-------------+ Id 为 1 和 3 的销售者,销售总金额都为最高的 2800。
解答 select seller_idfrom Salesgroup by seller_idhaving sum (price) >= all (select sum (price) from sales group by seller_id)
SQL架构
Create table If Not Exists ActorDirector (actor_id int , director_id int , timestamp int )Truncate table ActorDirectorinsert into ActorDirector (actor_id, director_id, timestamp ) values ('1' , '1' , '0' )insert into ActorDirector (actor_id, director_id, timestamp ) values ('1' , '1' , '1' )insert into ActorDirector (actor_id, director_id, timestamp ) values ('1' , '1' , '2' )insert into ActorDirector (actor_id, director_id, timestamp ) values ('1' , '2' , '3' )insert into ActorDirector (actor_id, director_id, timestamp ) values ('1' , '2' , '4' )insert into ActorDirector (actor_id, director_id, timestamp ) values ('2' , '1' , '5' )insert into ActorDirector (actor_id, director_id, timestamp ) values ('2' , '1' , '6' )
ActorDirector 表:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | actor_id | int | | director_id | int | | timestamp | int | +-------------+---------+ timestamp 是这张表的主键.
写一条SQL查询语句获取合作过至少三次的演员和导演的 id 对 (actor_id, director_id)
示例:
ActorDirector 表: +-------------+-------------+-------------+ | actor_id | director_id | timestamp | +-------------+-------------+-------------+ | 1 | 1 | 0 | | 1 | 1 | 1 | | 1 | 1 | 2 | | 1 | 2 | 3 | | 1 | 2 | 4 | | 2 | 1 | 5 | | 2 | 1 | 6 | +-------------+-------------+-------------+ Result 表: +-------------+-------------+ | actor_id | director_id | +-------------+-------------+ | 1 | 1 | +-------------+-------------+ 唯一的 id 对是 (1, 1),他们恰好合作了 3 次。
解答 select actor_id, director_idfrom ActorDirectorgroup by actor_id, director_idhaving count (*) >= 3
SQL架构
Create table If Not Exists orders (order_number int , customer_number int , order_date date , required_date date , shipped_date date , status char (15 ), comment char (200 ), key (order_number))Truncate table ordersinsert into orders (order_number, customer_number) values ('1' , '1' )insert into orders (order_number, customer_number) values ('2' , '2' )insert into orders (order_number, customer_number) values ('3' , '3' )insert into orders (order_number, customer_number) values ('4' , '3' )
在表 orders 中找到订单数最多客户对应的 customer_number 。
数据保证订单数最多的顾客恰好只有一位。
表 orders 定义如下:
| Column | Type | |-------------------|-----------| | order_number (PK) | int | | customer_number | int | | order_date | date | | required_date | date | | shipped_date | date | | status | char(15) | | comment | char(200) |
样例输入
| order_number | customer_number | order_date | required_date | shipped_date | status | comment | |--------------|-----------------|------------|---------------|--------------|--------|---------| | 1 | 1 | 2017-04-09 | 2017-04-13 | 2017-04-12 | Closed | | | 2 | 2 | 2017-04-15 | 2017-04-20 | 2017-04-18 | Closed | | | 3 | 3 | 2017-04-16 | 2017-04-25 | 2017-04-20 | Closed | | | 4 | 3 | 2017-04-18 | 2017-04-28 | 2017-04-25 | Closed | |
样例输出
| customer_number | |-----------------| | 3 |
解释
customer_number 为 '3' 的顾客有两个订单,比顾客 '1' 或者 '2' 都要多,因为他们只有一个订单 所以结果是该顾客的 customer_number ,也就是 3 。
进阶: 如果有多位顾客订单数并列最多,你能找到他们所有的 customer_number 吗?
解答 select customer_numberfrom ordersgroup by customer_numberorder by count (*) desc limit 1 select customer_numberfrom ordersgroup by customer_numberhaving count (*) >= all (select count (*) from orders group by customer_number)
SQL架构
Create table If Not Exists Activity (player_id int , device_id int , event_date date , games_played int )Truncate table Activityinsert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-03-01' , '5' )insert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-05-02' , '6' )insert into Activity (player_id, device_id, event_date, games_played) values ('2' , '3' , '2017-06-25' , '1' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '1' , '2016-03-02' , '0' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '4' , '2018-07-03' , '5' )
活动表 Activity:
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ 表的主键是 (player_id, event_date)。 这张表展示了一些游戏玩家在游戏平台上的行为活动。 每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。
写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期 。
查询结果的格式如下所示:
Activity 表: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-05-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ Result 表: +-----------+-------------+ | player_id | first_login | +-----------+-------------+ | 1 | 2016-03-01 | | 2 | 2017-06-25 | | 3 | 2016-03-02 | +-----------+-------------+
解答 select player_id, min (event_date) first_loginfrom Activitygroup by player_id
SQL架构
Create table Person (PersonId int , FirstName varchar (255 ), LastName varchar (255 ))Create table Address (AddressId int , PersonId int , City varchar (255 ), State varchar (255 ))Truncate table Personinsert into Person (PersonId, LastName, FirstName) values ('1' , 'Wang' , 'Allen' )Truncate table Addressinsert into Address (AddressId, PersonId, City, State) values ('1' , '2' , 'New York City' , 'New York' )
表1: Person
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | PersonId | int | | FirstName | varchar | | LastName | varchar | +-------------+---------+ PersonId 是上表主键
表2: Address
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | AddressId | int | | PersonId | int | | City | varchar | | State | varchar | +-------------+---------+ AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:
FirstName, LastName, City, State
解答 select FirstName, LastName, City, Statefrom Person pleft join Address aon p.PersonId = a. PersonId
SQL架构
Create table If Not Exists Products (product_id int , product_name varchar (40 ), product_category varchar (40 ))Create table If Not Exists Orders (product_id int , order_date date , unit int )Truncate table Productsinsert into Products (product_id, product_name, product_category) values ('1' , 'Leetcode Solutions' , 'Book' )insert into Products (product_id, product_name, product_category) values ('2' , 'Jewels of Stringology' , 'Book' )insert into Products (product_id, product_name, product_category) values ('3' , 'HP' , 'Laptop' )insert into Products (product_id, product_name, product_category) values ('4' , 'Lenovo' , 'Laptop' )insert into Products (product_id, product_name, product_category) values ('5' , 'Leetcode Kit' , 'T-shirt' )Truncate table Ordersinsert into Orders (product_id, order_date, unit) values ('1' , '2020-02-05' , '60' )insert into Orders (product_id, order_date, unit) values ('1' , '2020-02-10' , '70' )insert into Orders (product_id, order_date, unit) values ('2' , '2020-01-18' , '30' )insert into Orders (product_id, order_date, unit) values ('2' , '2020-02-11' , '80' )insert into Orders (product_id, order_date, unit) values ('3' , '2020-02-17' , '2' )insert into Orders (product_id, order_date, unit) values ('3' , '2020-02-24' , '3' )insert into Orders (product_id, order_date, unit) values ('4' , '2020-03-01' , '20' )insert into Orders (product_id, order_date, unit) values ('4' , '2020-03-04' , '30' )insert into Orders (product_id, order_date, unit) values ('4' , '2020-03-04' , '60' )insert into Orders (product_id, order_date, unit) values ('5' , '2020-02-25' , '50' )insert into Orders (product_id, order_date, unit) values ('5' , '2020-02-27' , '50' )insert into Orders (product_id, order_date, unit) values ('5' , '2020-03-01' , '50' )
表: Products
+------------------+---------+ | Column Name | Type | +------------------+---------+ | product_id | int | | product_name | varchar | | product_category | varchar | +------------------+---------+ product_id 是该表主键。 该表包含该公司产品的数据。
表: Orders
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | order_date | date | | unit | int | +---------------+---------+ 该表无主键,可能包含重复行。 product_id 是表单 Products 的外键。 unit 是在日期 order_date 内下单产品的数目。
写一个 SQL 语句,要求获取在 2020 年 2 月份下单的数量不少于 100 的产品的名字和数目。
返回结果表单的顺序无要求。
查询结果的格式如下:
Products 表: +-------------+-----------------------+------------------+ | product_id | product_name | product_category | +-------------+-----------------------+------------------+ | 1 | Leetcode Solutions | Book | | 2 | Jewels of Stringology | Book | | 3 | HP | Laptop | | 4 | Lenovo | Laptop | | 5 | Leetcode Kit | T-shirt | +-------------+-----------------------+------------------+ Orders 表: +--------------+--------------+----------+ | product_id | order_date | unit | +--------------+--------------+----------+ | 1 | 2020-02-05 | 60 | | 1 | 2020-02-10 | 70 | | 2 | 2020-01-18 | 30 | | 2 | 2020-02-11 | 80 | | 3 | 2020-02-17 | 2 | | 3 | 2020-02-24 | 3 | | 4 | 2020-03-01 | 20 | | 4 | 2020-03-04 | 30 | | 4 | 2020-03-04 | 60 | | 5 | 2020-02-25 | 50 | | 5 | 2020-02-27 | 50 | | 5 | 2020-03-01 | 50 | +--------------+--------------+----------+ Result 表: +--------------------+---------+ | product_name | unit | +--------------------+---------+ | Leetcode Solutions | 130 | | Leetcode Kit | 100 | +--------------------+---------+ 2020 年 2 月份下单 product_id = 1 的产品的数目总和为 (60 + 70) = 130 。 2020 年 2 月份下单 product_id = 2 的产品的数目总和为 80 。 2020 年 2 月份下单 product_id = 3 的产品的数目总和为 (2 + 3) = 5 。 2020 年 2 月份 product_id = 4 的产品并没有下单。 2020 年 2 月份下单 product_id = 5 的产品的数目总和为 (50 + 50) = 100 。
解答 select product_name, sum (unit) unitfrom Orders ojoin Products pon o.product_id = p.product_idwhere order_date between '2020-02-01' and '2020-02-29' group by o.product_idhaving sum (o.unit) >= 100
SQL架构
Create table If Not Exists Employee (EmpId int , Name varchar (255 ), Supervisor int , Salary int )Create table If Not Exists Bonus (EmpId int , Bonus int )Truncate table Employeeinsert into Employee (EmpId, Name , Supervisor, Salary) values ('3' , 'Brad' , 'None' , '4000' )insert into Employee (EmpId, Name , Supervisor, Salary) values ('1' , 'John' , '3' , '1000' )insert into Employee (EmpId, Name , Supervisor, Salary) values ('2' , 'Dan' , '3' , '2000' )insert into Employee (EmpId, Name , Supervisor, Salary) values ('4' , 'Thomas' , '3' , '4000' )Truncate table Bonusinsert into Bonus (EmpId, Bonus) values ('2' , '500' )insert into Bonus (EmpId, Bonus) values ('4' , '2000' )
选出所有 bonus < 1000 的员工的 name 及其 bonus。
Employee 表单
+-------+--------+-----------+--------+ | empId | name | supervisor| salary | +-------+--------+-----------+--------+ | 1 | John | 3 | 1000 | | 2 | Dan | 3 | 2000 | | 3 | Brad | null | 4000 | | 4 | Thomas | 3 | 4000 | +-------+--------+-----------+--------+ empId 是这张表单的主关键字
Bonus 表单
+-------+-------+ | empId | bonus | +-------+-------+ | 2 | 500 | | 4 | 2000 | +-------+-------+ empId 是这张表单的主关键字
输出示例:
+-------+-------+ | name | bonus | +-------+-------+ | John | null | | Dan | 500 | | Brad | null | +-------+-------+
解答 select `name` , bonusfrom Employee e left join Bonus bon e.empId = b.empIdwhere b.bonus < 1000 or b.bonus is null
SQL架构
Create table If Not Exists Employee (Id int , Name varchar (255 ), Salary int , ManagerId int )Truncate table Employeeinsert into Employee (Id , Name , Salary, ManagerId) values ('1' , 'Joe' , '70000' , '3' )insert into Employee (Id , Name , Salary, ManagerId) values ('2' , 'Henry' , '80000' , '4' )insert into Employee (Id , Name , Salary, ManagerId) values ('3' , 'Sam' , '60000' , 'None' )insert into Employee (Id , Name , Salary, ManagerId) values ('4' , 'Max' , '90000' , 'None' )
Employee 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。
+----+-------+--------+-----------+ | Id | Name | Salary | ManagerId | +----+-------+--------+-----------+ | 1 | Joe | 70000 | 3 | | 2 | Henry | 80000 | 4 | | 3 | Sam | 60000 | NULL | | 4 | Max | 90000 | NULL | +----+-------+--------+-----------+
给定 Employee 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。
+----------+ | Employee | +----------+ | Joe | +----------+
解答 select e1.`Name` Employeefrom Employee e1, Employee e2where e1.ManagerId = e2.id and e1.Salary > e2.Salary
SQL架构
Create table If Not Exists cinema (seat_id int primary key auto_increment, free bool )Truncate table cinemainsert into cinema (seat_id, free) values ('1' , '1' )insert into cinema (seat_id, free) values ('2' , '0' )insert into cinema (seat_id, free) values ('3' , '1' )insert into cinema (seat_id, free) values ('4' , '1' )insert into cinema (seat_id, free) values ('5' , '1' )
几个朋友来到电影院的售票处,准备预约连续空余座位。
你能利用表 cinema ,帮他们写一个查询语句,获取所有空余座位,并将它们按照 seat_id 排序后返回吗?
| seat_id | free | |---------|------| | 1 | 1 | | 2 | 0 | | 3 | 1 | | 4 | 1 | | 5 | 1 |
对于如上样例,你的查询语句应该返回如下结果。
| seat_id | |---------| | 3 | | 4 | | 5 |
注意:
seat_id 字段是一个自增的整数,free 字段是布尔类型(’1’ 表示空余, ‘0’ 表示已被占据)。
连续空余座位的定义是大于等于 2 个连续空余的座位。
解答 直接自连接,形成的是一个笛卡尔积。
seat_id free seat_id free 1 1 1 1 2 0 1 1 3 1 1 1 4 1 1 1 5 1 1 1 1 1 2 0 2 0 2 0 3 1 2 0 4 1 2 0 5 1 2 0 1 1 3 1 2 0 3 1 3 1 3 1 4 1 3 1 5 1 3 1 1 1 4 1 2 0 4 1 3 1 4 1 4 1 4 1 5 1 4 1 1 1 5 1 2 0 5 1 3 1 5 1 4 1 5 1 5 1 5 1
根据题意,连续空余座位的定义是大于等于 2 个连续空余的座位,那么只需要两座位的 seat_id 差的绝对值小于等于 1 就可以了,并且同时为 free。
select distinct c1.seat_idfrom cinema c1, cinema c2where c1.seat_id != c2.seat_id and abs (c1.seat_id - c2.seat_id) <= 1 and c1.free and c2.freeorder by seat_id
SQL架构
Create table If Not Exists Customers (Id int , Name varchar (255 ))Create table If Not Exists Orders (Id int , CustomerId int )Truncate table Customersinsert into Customers (Id , Name ) values ('1' , 'Joe' )insert into Customers (Id , Name ) values ('2' , 'Henry' )insert into Customers (Id , Name ) values ('3' , 'Sam' )insert into Customers (Id , Name ) values ('4' , 'Max' )Truncate table Ordersinsert into Orders (Id , CustomerId) values ('1' , '3' )insert into Orders (Id , CustomerId) values ('2' , '1' )
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers 表:
+----+-------+ | Id | Name | +----+-------+ | 1 | Joe | | 2 | Henry | | 3 | Sam | | 4 | Max | +----+-------+
Orders 表:
+----+------------+ | Id | CustomerId | +----+------------+ | 1 | 3 | | 2 | 1 | +----+------------+
例如给定上述表格,你的查询应返回:
+-----------+ | Customers | +-----------+ | Henry | | Max | +-----------+
解答 select `Name` Customersfrom Customerswhere Id not in (select CustomerId from Orders)select c.`Name` Customersfrom Customers cleft join Orders o on c.Id = o.CustomerIdwhere o.CustomerId is null
SQL架构
Create table If Not Exists Department (id int , revenue int , month varchar (5 ))Truncate table Departmentinsert into Department (id , revenue, month ) values ('1' , '8000' , 'Jan' )insert into Department (id , revenue, month ) values ('2' , '9000' , 'Jan' )insert into Department (id , revenue, month ) values ('3' , '10000' , 'Feb' )insert into Department (id , revenue, month ) values ('1' , '7000' , 'Feb' )insert into Department (id , revenue, month ) values ('1' , '6000' , 'Mar' )
部门表 Department:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | revenue | int | | month | varchar | +---------------+---------+ (id, month) 是表的联合主键。 这个表格有关于每个部门每月收入的信息。 月份(month)可以取下列值 ["Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"]。
编写一个 SQL 查询来重新格式化表,使得新的表中有一个部门 id 列和一些对应 每个月 的收入(revenue)列。
查询结果格式如下面的示例所示:
Department 表: +------+---------+-------+ | id | revenue | month | +------+---------+-------+ | 1 | 8000 | Jan | | 2 | 9000 | Jan | | 3 | 10000 | Feb | | 1 | 7000 | Feb | | 1 | 6000 | Mar | +------+---------+-------+ 查询得到的结果表: +------+-------------+-------------+-------------+-----+-------------+ | id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue | +------+-------------+-------------+-------------+-----+-------------+ | 1 | 8000 | 7000 | 6000 | ... | null | | 2 | 9000 | null | null | ... | null | | 3 | null | 10000 | null | ... | null | +------+-------------+-------------+-------------+-----+-------------+ 注意,结果表有 13 列 (1个部门 id 列 + 12个月份的收入列)。
解答 体力活
select id , sum (case when month = 'Jan' then revenue end ) as Jan_Revenue, sum (case when month = 'Feb' then revenue end ) as Feb_Revenue, sum (case when month = 'Mar' then revenue end ) as Mar_Revenue, sum (case when month = 'Apr' then revenue end ) as Apr_Revenue, sum (case when month = 'May' then revenue end ) as May_Revenue, sum (case when month = 'Jun' then revenue end ) as Jun_Revenue, sum (case when month = 'Jul' then revenue end ) as Jul_Revenue, sum (case when month = 'Aug' then revenue end ) as Aug_Revenue, sum (case when month = 'Sep' then revenue end ) as Sep_Revenue, sum (case when month = 'Oct' then revenue end ) as Oct_Revenue, sum (case when month = 'Nov' then revenue end ) as Nov_Revenue, sum (case when month = 'Dec' then revenue end ) as Dec_Revenue from departmentgroup by id ;
SQL架构
Create table If Not Exists salesperson (sales_id int , name varchar (255 ), salary int ,commission_rate int , hire_date varchar (255 ))Create table If Not Exists company (com_id int , name varchar (255 ), city varchar (255 ))Create table If Not Exists orders (order_id int , order_date varchar (255 ), com_id int , sales_id int , amount int )Truncate table salespersoninsert into salesperson (sales_id, name , salary, commission_rate, hire_date) values ('1' , 'John' , '100000' , '6' , '4/1/2006' )insert into salesperson (sales_id, name , salary, commission_rate, hire_date) values ('2' , 'Amy' , '12000' , '5' , '5/1/2010' )insert into salesperson (sales_id, name , salary, commission_rate, hire_date) values ('3' , 'Mark' , '65000' , '12' , '12/25/2008' )insert into salesperson (sales_id, name , salary, commission_rate, hire_date) values ('4' , 'Pam' , '25000' , '25' , '1/1/2005' )insert into salesperson (sales_id, name , salary, commission_rate, hire_date) values ('5' , 'Alex' , '5000' , '10' , '2/3/2007' )Truncate table companyinsert into company (com_id, name , city) values ('1' , 'RED' , 'Boston' )insert into company (com_id, name , city) values ('2' , 'ORANGE' , 'New York' )insert into company (com_id, name , city) values ('3' , 'YELLOW' , 'Boston' )insert into company (com_id, name , city) values ('4' , 'GREEN' , 'Austin' )Truncate table ordersinsert into orders (order_id, order_date, com_id, sales_id, amount) values ('1' , '1/1/2014' , '3' , '4' , '10000' )insert into orders (order_id, order_date, com_id, sales_id, amount) values ('2' , '2/1/2014' , '4' , '5' , '5000' )insert into orders (order_id, order_date, com_id, sales_id, amount) values ('3' , '3/1/2014' , '1' , '1' , '50000' )insert into orders (order_id, order_date, com_id, sales_id, amount) values ('4' , '4/1/2014' , '1' , '4' , '25000' )
描述
给定 3 个表: salesperson, company, orders。
输出所有表 salesperson 中,没有向公司 ‘RED’ 销售任何东西的销售员。
输入
表: salesperson
+----------+------+--------+-----------------+-----------+ | sales_id | name | salary | commission_rate | hire_date | +----------+------+--------+-----------------+-----------+ | 1 | John | 100000 | 6 | 4/1/2006 | | 2 | Amy | 120000 | 5 | 5/1/2010 | | 3 | Mark | 65000 | 12 | 12/25/2008| | 4 | Pam | 25000 | 25 | 1/1/2005 | | 5 | Alex | 50000 | 10 | 2/3/2007 | +----------+------+--------+-----------------+-----------+
表 salesperson 存储了所有销售员的信息。每个销售员都有一个销售员编号 sales_id 和他的名字 name 。
表: company
+---------+--------+------------+ | com_id | name | city | +---------+--------+------------+ | 1 | RED | Boston | | 2 | ORANGE | New York | | 3 | YELLOW | Boston | | 4 | GREEN | Austin | +---------+--------+------------+
表 company 存储了所有公司的信息。每个公司都有一个公司编号 com_id 和它的名字 name 。
表: orders
+----------+------------+---------+----------+--------+ | order_id | order_date | com_id | sales_id | amount | +----------+------------+---------+----------+--------+ | 1 | 1/1/2014 | 3 | 4 | 100000 | | 2 | 2/1/2014 | 4 | 5 | 5000 | | 3 | 3/1/2014 | 1 | 1 | 50000 | | 4 | 4/1/2014 | 1 | 4 | 25000 | +----------+----------+---------+----------+--------+
表 orders 存储了所有的销售数据,包括销售员编号 sales_id 和公司编号 com_id 。
输出
+------+ | name | +------+ | Amy | | Mark | | Alex | +------+
解释
根据表 orders 中的订单 ‘3’ 和 ‘4’ ,容易看出只有 ‘John’ 和 ‘Pam’ 两个销售员曾经向公司 ‘RED’ 销售过。
所以我们需要输出表 salesperson 中所有其他人的名字。
解答 select `name` from salesperson s where s.sales_id not in ( select sales_id from orders o left join company c on o.com_id = c.com_id where c.`name` = 'RED' )
SQL架构
Create table If Not Exists triangle (x int , y int , z int )Truncate table triangleinsert into triangle (x, y, z) values ('13' , '15' , '30' )insert into triangle (x, y, z) values ('10' , '20' , '15' )
一个小学生 Tim 的作业是判断三条线段是否能形成一个三角形。
然而,这个作业非常繁重,因为有几百组线段需要判断。
假设表 triangle 保存了所有三条线段的三元组 x, y, z ,你能帮 Tim 写一个查询语句,来判断每个三元组是否可以组成一个三角形吗?
x
y
z
13
15
30
10
20
15
对于如上样例数据,你的查询语句应该返回如下结果:
x
y
z
triangle
13
15
30
No
10
20
15
Yes
解答 select *, if ((x + y <= z or x + z <= y or y + z <= x), "No" , "Yes" ) as trianglefrom triangle;
SQL架构
Create table If Not Exists Countries (country_id int , country_name varchar (20 ))Create table If Not Exists Weather (country_id int , weather_state int , day date )Truncate table Countriesinsert into Countries (country_id, country_name) values ('2' , 'USA' )insert into Countries (country_id, country_name) values ('3' , 'Australia' )insert into Countries (country_id, country_name) values ('7' , 'Peru' )insert into Countries (country_id, country_name) values ('5' , 'China' )insert into Countries (country_id, country_name) values ('8' , 'Morocco' )insert into Countries (country_id, country_name) values ('9' , 'Spain' )Truncate table Weatherinsert into Weather (country_id, weather_state, day ) values ('2' , '15' , '2019-11-01' )insert into Weather (country_id, weather_state, day ) values ('2' , '12' , '2019-10-28' )insert into Weather (country_id, weather_state, day ) values ('2' , '12' , '2019-10-27' )insert into Weather (country_id, weather_state, day ) values ('3' , '-2' , '2019-11-10' )insert into Weather (country_id, weather_state, day ) values ('3' , '0' , '2019-11-11' )insert into Weather (country_id, weather_state, day ) values ('3' , '3' , '2019-11-12' )insert into Weather (country_id, weather_state, day ) values ('5' , '16' , '2019-11-07' )insert into Weather (country_id, weather_state, day ) values ('5' , '18' , '2019-11-09' )insert into Weather (country_id, weather_state, day ) values ('5' , '21' , '2019-11-23' )insert into Weather (country_id, weather_state, day ) values ('7' , '25' , '2019-11-28' )insert into Weather (country_id, weather_state, day ) values ('7' , '22' , '2019-12-01' )insert into Weather (country_id, weather_state, day ) values ('7' , '20' , '2019-12-02' )insert into Weather (country_id, weather_state, day ) values ('8' , '25' , '2019-11-05' )insert into Weather (country_id, weather_state, day ) values ('8' , '27' , '2019-11-15' )insert into Weather (country_id, weather_state, day ) values ('8' , '31' , '2019-11-25' )insert into Weather (country_id, weather_state, day ) values ('9' , '7' , '2019-10-23' )insert into Weather (country_id, weather_state, day ) values ('9' , '3' , '2019-12-23' )
国家表:Countries
+---------------+---------+ | Column Name | Type | +---------------+---------+ | country_id | int | | country_name | varchar | +---------------+---------+ country_id 是这张表的主键。 该表的每行有 country_id 和 country_name 两列。
天气表:Weather
+---------------+---------+ | Column Name | Type | +---------------+---------+ | country_id | int | | weather_state | varchar | | day | date | +---------------+---------+ (country_id, day) 是该表的复合主键。 该表的每一行记录了某个国家某一天的天气情况。
写一段 SQL 来找到表中每个国家在 2019 年 11 月的天气类型。
天气类型的定义如下:当 weather_state 的平均值小于或等于15返回 Cold ,当 weather_state 的平均值大于或等于 25 返回 Hot ,否则返回 Warm 。
你可以以任意顺序返回你的查询结果。
查询结果格式如下所示:
Countries table: +------------+--------------+ | country_id | country_name | +------------+--------------+ | 2 | USA | | 3 | Australia | | 7 | Peru | | 5 | China | | 8 | Morocco | | 9 | Spain | +------------+--------------+ Weather table: +------------+---------------+------------+ | country_id | weather_state | day | +------------+---------------+------------+ | 2 | 15 | 2019-11-01 | | 2 | 12 | 2019-10-28 | | 2 | 12 | 2019-10-27 | | 3 | -2 | 2019-11-10 | | 3 | 0 | 2019-11-11 | | 3 | 3 | 2019-11-12 | | 5 | 16 | 2019-11-07 | | 5 | 18 | 2019-11-09 | | 5 | 21 | 2019-11-23 | | 7 | 25 | 2019-11-28 | | 7 | 22 | 2019-12-01 | | 7 | 20 | 2019-12-02 | | 8 | 25 | 2019-11-05 | | 8 | 27 | 2019-11-15 | | 8 | 31 | 2019-11-25 | | 9 | 7 | 2019-10-23 | | 9 | 3 | 2019-12-23 | +------------+---------------+------------+ Result table: +--------------+--------------+ | country_name | weather_type | +--------------+--------------+ | USA | Cold | | Austraila | Cold | | Peru | Hot | | China | Warm | | Morocco | Hot | +--------------+--------------+ USA 11 月的平均 weather_state 为 (15) / 1 = 15 所以天气类型为 Cold。 Australia 11 月的平均 weather_state 为 (-2 + 0 + 3) / 3 = 0.333 所以天气类型为 Cold。 Peru 11 月的平均 weather_state 为 (25) / 1 = 25 所以天气类型为 Hot。 China 11 月的平均 weather_state 为 (16 + 18 + 21) / 3 = 18.333 所以天气类型为 Warm。 Morocco 11 月的平均 weather_state 为 (25 + 27 + 31) / 3 = 27.667 所以天气类型为 Hot。 我们并不知道 Spain 在 11 月的 weather_state 情况所以无需将他包含在结果中。
解答 select country_name, case when avg (weather_state) <= 15 then 'Cold' when avg (weather_state) >= 25 then 'Hot' else 'Warm' end as weather_type from Weather wjoin Countries c on w.country_id = c.country_idwhere day between '2019-11-01' and '2019-11-30' group by w.country_id
SQL架构
Create table If Not Exists Queries (query_name varchar (30 ), result varchar (50 ), position int , rating int )Truncate table Queriesinsert into Queries (query_name, result , position , rating) values ('Dog' , 'Golden Retriever' , '1' , '5' )insert into Queries (query_name, result , position , rating) values ('Dog' , 'German Shepherd' , '2' , '5' )insert into Queries (query_name, result , position , rating) values ('Dog' , 'Mule' , '200' , '1' )insert into Queries (query_name, result , position , rating) values ('Cat' , 'Shirazi' , '5' , '2' )insert into Queries (query_name, result , position , rating) values ('Cat' , 'Siamese' , '3' , '3' )insert into Queries (query_name, result , position , rating) values ('Cat' , 'Sphynx' , '7' , '4' )
查询表 Queries:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | query_name | varchar | | result | varchar | | position | int | | rating | int | +-------------+---------+ 此表没有主键,并可能有重复的行。 此表包含了一些从数据库中收集的查询信息。 “位置”(position)列的值为 1 到 500 。 “评分”(rating)列的值为 1 到 5 。评分小于 3 的查询被定义为质量很差的查询。
将查询结果的质量 quality 定义为:
各查询结果的评分与其位置之间比率的平均值。
将劣质查询百分比 poor_query_percentage 为:
评分小于 3 的查询结果占全部查询结果的百分比。
编写一组 SQL 来查找每次查询的名称(query_name)、质量(quality) 和 劣质查询百分比(poor_query_percentage)。
质量(quality) 和劣质查询百分比(poor_query_percentage) 都应四舍五入到小数点后两位。
查询结果格式如下所示:
Queries table: +------------+-------------------+----------+--------+ | query_name | result | position | rating | +------------+-------------------+----------+--------+ | Dog | Golden Retriever | 1 | 5 | | Dog | German Shepherd | 2 | 5 | | Dog | Mule | 200 | 1 | | Cat | Shirazi | 5 | 2 | | Cat | Siamese | 3 | 3 | | Cat | Sphynx | 7 | 4 | +------------+-------------------+----------+--------+ Result table: +------------+---------+-----------------------+ | query_name | quality | poor_query_percentage | +------------+---------+-----------------------+ | Dog | 2.50 | 33.33 | | Cat | 0.66 | 33.33 | +------------+---------+-----------------------+ Dog 查询结果的质量为 ((5 / 1) + (5 / 2) + (1 / 200)) / 3 = 2.50 Dog 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33 Cat 查询结果的质量为 ((2 / 5) + (3 / 3) + (4 / 7)) / 3 = 0.66 Cat 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33
解答 select query_name, round (avg (rp), 2 ) quality, round (avg (poor_query) * 100 , 2 ) poor_query_percentagefrom ( select query_name, (rating / `position` ) rp , if (rating >= 3 , 0 , 1 ) poor_query from Queries ) t group by query_name;
编写一个 SQL 查询,来删除 Person 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
+----+------------------+ | Id | Email | +----+------------------+ | 1 | john@example.com | | 2 | bob@example.com | | 3 | john@example.com | +----+------------------+ Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Person 表应返回以下几行:
+----+------------------+ | Id | Email | +----+------------------+ | 1 | john@example.com | | 2 | bob@example.com | +----+------------------+
提示:
执行 SQL 之后,输出是整个 Person 表。 使用 delete 语句。
解答 delete p1 from Person p1, Person p2where p1.Email = p2.Email and p1.Id > p2.Id;
SQL架构
Create table If Not Exists Submissions (sub_id int , parent_id int )Truncate table Submissionsinsert into Submissions (sub_id, parent_id) values ('1' , 'None' )insert into Submissions (sub_id, parent_id) values ('2' , 'None' )insert into Submissions (sub_id, parent_id) values ('1' , 'None' )insert into Submissions (sub_id, parent_id) values ('12' , 'None' )insert into Submissions (sub_id, parent_id) values ('3' , '1' )insert into Submissions (sub_id, parent_id) values ('5' , '2' )insert into Submissions (sub_id, parent_id) values ('3' , '1' )insert into Submissions (sub_id, parent_id) values ('4' , '1' )insert into Submissions (sub_id, parent_id) values ('9' , '1' )insert into Submissions (sub_id, parent_id) values ('10' , '2' )insert into Submissions (sub_id, parent_id) values ('6' , '7' )
表 Submissions 结构如下:
+---------------+----------+ | 列名 | 类型 | +---------------+----------+ | sub_id | int | | parent_id | int | +---------------+----------+ 上表没有主键, 所以可能会出现重复的行。 每行可以是一个帖子或对该帖子的评论。 如果是帖子的话,parent_id 就是 null。 对于评论来说,parent_id 就是表中对应帖子的 sub_id。
编写 SQL 语句以查找每个帖子的评论数。
结果表应包含帖子的 post_id 和对应的评论数 number_of_comments 并且按 post_id 升序排列。
Submissions 可能包含重复的评论。您应该计算每个帖子的唯一评论数。
Submissions 可能包含重复的帖子。您应该将它们视为一个帖子。
查询结果格式如下例所示:
Submissions table: +---------+------------+ | sub_id | parent_id | +---------+------------+ | 1 | Null | | 2 | Null | | 1 | Null | | 12 | Null | | 3 | 1 | | 5 | 2 | | 3 | 1 | | 4 | 1 | | 9 | 1 | | 10 | 2 | | 6 | 7 | +---------+------------+ 结果表: +---------+--------------------+ | post_id | number_of_comments | +---------+--------------------+ | 1 | 3 | | 2 | 2 | | 12 | 0 | +---------+--------------------+ 表中 ID 为 1 的帖子有 ID 为 3、4 和 9 的三个评论。表中 ID 为 3 的评论重复出现了,所以我们只对它进行了一次计数。 表中 ID 为 2 的帖子有 ID 为 5 和 10 的两个评论。 ID 为 12 的帖子在表中没有评论。 表中 ID 为 6 的评论是对 ID 为 7 的已删除帖子的评论,因此我们将其忽略。
解答 select post_id, count (distinct S2.sub_id) as number_of_comments from (select distinct sub_id as post_id from Submissions where parent_id is null ) S1left join Submissions S2 on S1.post_id = S2.parent_id group by S1.post_id
SQL架构
Create table If Not Exists Project (project_id int , employee_id int )Create table If Not Exists Employee (employee_id int , name varchar (10 ), experience_years int )Truncate table Project insert into Project (project_id, employee_id) values ('1' , '1' )insert into Project (project_id, employee_id) values ('1' , '2' )insert into Project (project_id, employee_id) values ('1' , '3' )insert into Project (project_id, employee_id) values ('2' , '1' )insert into Project (project_id, employee_id) values ('2' , '4' )Truncate table Employeeinsert into Employee (employee_id, name , experience_years) values ('1' , 'Khaled' , '3' )insert into Employee (employee_id, name , experience_years) values ('2' , 'Ali' , '2' )insert into Employee (employee_id, name , experience_years) values ('3' , 'John' , '1' )insert into Employee (employee_id, name , experience_years) values ('4' , 'Doe' , '2' )
项目表 Project:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | project_id | int | | employee_id | int | +-------------+---------+ 主键为 (project_id, employee_id)。 employee_id 是员工表 Employee 表的外键。
员工表 Employee:
+------------------+---------+ | Column Name | Type | +------------------+---------+ | employee_id | int | | name | varchar | | experience_years | int | +------------------+---------+ 主键是 employee_id。
请写一个 SQL 语句,查询每一个项目中员工的 平均 工作年限,精确到小数点后两位 。
查询结果的格式如下:
Project 表: +-------------+-------------+ | project_id | employee_id | +-------------+-------------+ | 1 | 1 | | 1 | 2 | | 1 | 3 | | 2 | 1 | | 2 | 4 | +-------------+-------------+ Employee 表: +-------------+--------+------------------+ | employee_id | name | experience_years | +-------------+--------+------------------+ | 1 | Khaled | 3 | | 2 | Ali | 2 | | 3 | John | 1 | | 4 | Doe | 2 | +-------------+--------+------------------+ Result 表: +-------------+---------------+ | project_id | average_years | +-------------+---------------+ | 1 | 2.00 | | 2 | 2.50 | +-------------+---------------+ 第一个项目中,员工的平均工作年限是 (3 + 2 + 1) / 3 = 2.00;第二个项目中,员工的平均工作年限是 (3 + 2) / 2 = 2.50
解答 select project_id, round (avg (experience_years), 2 ) average_yearsfrom Project pjoin Employee e on p.employee_id = e.employee_idgroup by project_id
SQL架构
Create table If Not Exists Students (student_id int , student_name varchar (20 ))Create table If Not Exists Subjects (subject_name varchar (20 ))Create table If Not Exists Examinations (student_id int , subject_name varchar (20 ))Truncate table Studentsinsert into Students (student_id, student_name) values ('1' , 'Alice' )insert into Students (student_id, student_name) values ('2' , 'Bob' )insert into Students (student_id, student_name) values ('13' , 'John' )insert into Students (student_id, student_name) values ('6' , 'Alex' )Truncate table Subjectsinsert into Subjects (subject_name) values ('Math' )insert into Subjects (subject_name) values ('Physics' )insert into Subjects (subject_name) values ('Programming' )Truncate table Examinationsinsert into Examinations (student_id, subject_name) values ('1' , 'Math' )insert into Examinations (student_id, subject_name) values ('1' , 'Physics' )insert into Examinations (student_id, subject_name) values ('1' , 'Programming' )insert into Examinations (student_id, subject_name) values ('2' , 'Programming' )insert into Examinations (student_id, subject_name) values ('1' , 'Physics' )insert into Examinations (student_id, subject_name) values ('1' , 'Math' )insert into Examinations (student_id, subject_name) values ('13' , 'Math' )insert into Examinations (student_id, subject_name) values ('13' , 'Programming' )insert into Examinations (student_id, subject_name) values ('13' , 'Physics' )insert into Examinations (student_id, subject_name) values ('2' , 'Math' )insert into Examinations (student_id, subject_name) values ('1' , 'Math' )
学生表: Students
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ 主键为 student_id(学生ID),该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects
+--------------+---------+ | Column Name | Type | +--------------+---------+ | subject_name | varchar | +--------------+---------+ 主键为 subject_name(科目名称),每一行记录学校的一门科目名称。
考试表: Examinations
+--------------+---------+ | Column Name | Type | +--------------+---------+ | student_id | int | | subject_name | varchar | +--------------+---------+ 这张表压根没有主键,可能会有重复行。 学生表里的一个学生修读科目表里的每一门科目,而这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
要求写一段 SQL 语句,查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示:
Students table: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | | 13 | John | | 6 | Alex | +------------+--------------+ Subjects table: +--------------+ | subject_name | +--------------+ | Math | | Physics | | Programming | +--------------+ Examinations table: +------------+--------------+ | student_id | subject_name | +------------+--------------+ | 1 | Math | | 1 | Physics | | 1 | Programming | | 2 | Programming | | 1 | Physics | | 1 | Math | | 13 | Math | | 13 | Programming | | 13 | Physics | | 2 | Math | | 1 | Math | +------------+--------------+ Result table: +------------+--------------+--------------+----------------+ | student_id | student_name | subject_name | attended_exams | +------------+--------------+--------------+----------------+ | 1 | Alice | Math | 3 | | 1 | Alice | Physics | 2 | | 1 | Alice | Programming | 1 | | 2 | Bob | Math | 1 | | 2 | Bob | Physics | 0 | | 2 | Bob | Programming | 1 | | 6 | Alex | Math | 0 | | 6 | Alex | Physics | 0 | | 6 | Alex | Programming | 0 | | 13 | John | Math | 1 | | 13 | John | Physics | 1 | | 13 | John | Programming | 1 | +------------+--------------+--------------+----------------+ 结果表需包含所有学生和所有科目(即便测试次数为0): Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试; Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试; Alex 啥测试都没参加; John 参加了数学、物理、编程测试各 1 次。
解答 SELECT a.student_id, a.student_name, b.subject_name, COUNT (e.subject_name) AS attended_examsFROM Students a JOIN Subjects b LEFT JOIN Examinations e ON a.student_id = e.student_id AND b.subject_name = e.subject_name GROUP BY a.student_id, b.subject_nameORDER BY a.student_id, b.subject_name
SQL架构
Create table If Not Exists Actions (user_id int , post_id int , action_date date , action ENUM('view' , 'like' , 'reaction' , 'comment' , 'report' , 'share' ), extra varchar (10 ))Truncate table Actionsinsert into Actions (user_id, post_id, action_date, action , extra) values ('1' , '1' , '2019-07-01' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('1' , '1' , '2019-07-01' , 'like' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('1' , '1' , '2019-07-01' , 'share' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('2' , '4' , '2019-07-04' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('2' , '4' , '2019-07-04' , 'report' , 'spam' )insert into Actions (user_id, post_id, action_date, action , extra) values ('3' , '4' , '2019-07-04' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('3' , '4' , '2019-07-04' , 'report' , 'spam' )insert into Actions (user_id, post_id, action_date, action , extra) values ('4' , '3' , '2019-07-02' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('4' , '3' , '2019-07-02' , 'report' , 'spam' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '2' , '2019-07-04' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '2' , '2019-07-04' , 'report' , 'racism' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '5' , '2019-07-04' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '5' , '2019-07-04' , 'report' , 'racism' )
动作表:Actions
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | post_id | int | | action_date | date | | action | enum | | extra | varchar | +---------------+---------+ 此表没有主键,所以可能会有重复的行。 action 字段是 ENUM 类型的,包含:('view', 'like', 'reaction', 'comment', 'report', 'share') extra 字段是可选的信息(可能为 null),其中的信息例如有:1.报告理由(a reason for report) 2.反应类型(a type of reaction)
编写一条SQL,查询每种 报告理由 2019-07-05 。
查询及结果的格式示例:
Actions table: +---------+---------+-------------+--------+--------+ | user_id | post_id | action_date | action | extra | +---------+---------+-------------+--------+--------+ | 1 | 1 | 2019-07-01 | view | null | | 1 | 1 | 2019-07-01 | like | null | | 1 | 1 | 2019-07-01 | share | null | | 2 | 4 | 2019-07-04 | view | null | | 2 | 4 | 2019-07-04 | report | spam | | 3 | 4 | 2019-07-04 | view | null | | 3 | 4 | 2019-07-04 | report | spam | | 4 | 3 | 2019-07-02 | view | null | | 4 | 3 | 2019-07-02 | report | spam | | 5 | 2 | 2019-07-04 | view | null | | 5 | 2 | 2019-07-04 | report | racism | | 5 | 5 | 2019-07-04 | view | null | | 5 | 5 | 2019-07-04 | report | racism | +---------+---------+-------------+--------+--------+ Result table: +---------------+--------------+ | report_reason | report_count | +---------------+--------------+ | spam | 1 | | racism | 2 | +---------------+--------------+ 注意,我们只关心报告数量非零的结果。
解答 select extra as report_reason, count (distinct post_id) as report_countfrom actionswhere datediff ('2019-07-05' , action_date) = 1 and extra is not null and action ='report' group by report_reason;
SQL架构
Create table If Not Exists Activity (user_id int , session_id int , activity_date date , activity_type ENUM('open_session' , 'end_session' , 'scroll_down' , 'send_message' ))Truncate table Activityinsert into Activity (user_id, session_id, activity_date, activity_type) values ('1' , '1' , '2019-07-20' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('1' , '1' , '2019-07-20' , 'scroll_down' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('1' , '1' , '2019-07-20' , 'end_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('2' , '4' , '2019-07-20' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('2' , '4' , '2019-07-21' , 'send_message' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('2' , '4' , '2019-07-21' , 'end_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '2' , '2019-07-21' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '2' , '2019-07-21' , 'send_message' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '2' , '2019-07-21' , 'end_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('4' , '3' , '2019-06-25' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('4' , '3' , '2019-06-25' , 'end_session' )
活动纪录表:Activity
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | session_id | int | | activity_date | date | | activity_type | enum | +---------------+---------+ 该表是用户在社交网站的活动记录。 该表没有主键,可能包含重复数据。 activity_type 字段为以下四种值 ('open_session', 'end_session', 'scroll_down', 'send_message')。 每个 session_id 只属于一个用户。
请写SQL查询出截至 2019-07-27 (包含2019-07-27),近 30天的每日活跃用户(当天只要有一条活跃记录,即为活跃用户),
查询结果示例如下:
Activity table: +---------+------------+---------------+---------------+ | user_id | session_id | activity_date | activity_type | +---------+------------+---------------+---------------+ | 1 | 1 | 2019-07-20 | open_session | | 1 | 1 | 2019-07-20 | scroll_down | | 1 | 1 | 2019-07-20 | end_session | | 2 | 4 | 2019-07-20 | open_session | | 2 | 4 | 2019-07-21 | send_message | | 2 | 4 | 2019-07-21 | end_session | | 3 | 2 | 2019-07-21 | open_session | | 3 | 2 | 2019-07-21 | send_message | | 3 | 2 | 2019-07-21 | end_session | | 4 | 3 | 2019-06-25 | open_session | | 4 | 3 | 2019-06-25 | end_session | +---------+------------+---------------+---------------+ Result table: +------------+--------------+ | day | active_users | +------------+--------------+ | 2019-07-20 | 2 | | 2019-07-21 | 2 | +------------+--------------+ 非活跃用户的记录不需要展示。
解答 select activity_date as `day` , count (distinct user_id) as active_usersfrom Activitywhere datediff ('2019-07-27' , activity_date) < 30 group by activity_date
SQL架构
Create table If Not Exists Ads (ad_id int , user_id int , action ENUM('Clicked' , 'Viewed' , 'Ignored' ))Truncate table Adsinsert into Ads (ad_id, user_id, action ) values ('1' , '1' , 'Clicked' )insert into Ads (ad_id, user_id, action ) values ('2' , '2' , 'Clicked' )insert into Ads (ad_id, user_id, action ) values ('3' , '3' , 'Viewed' )insert into Ads (ad_id, user_id, action ) values ('5' , '5' , 'Ignored' )insert into Ads (ad_id, user_id, action ) values ('1' , '7' , 'Ignored' )insert into Ads (ad_id, user_id, action ) values ('2' , '7' , 'Viewed' )insert into Ads (ad_id, user_id, action ) values ('3' , '5' , 'Clicked' )insert into Ads (ad_id, user_id, action ) values ('1' , '4' , 'Viewed' )insert into Ads (ad_id, user_id, action ) values ('2' , '11' , 'Viewed' )insert into Ads (ad_id, user_id, action ) values ('1' , '2' , 'Clicked' )
表: Ads
+---------------+---------+ | Column Name | Type | +---------------+---------+ | ad_id | int | | user_id | int | | action | enum | +---------------+---------+ (ad_id, user_id) 是该表的主键 该表的每一行包含一条广告的 ID(ad_id),用户的 ID(user_id) 和用户对广告采取的行为 (action) action 列是一个枚举类型 ('Clicked', 'Viewed', 'Ignored') 。
一家公司正在运营这些广告并想计算每条广告的效果。
广告效果用点击通过率(Click-Through Rate:CTR)来衡量,公式如下:
写一条SQL语句来查询每一条广告的 ctr ,
ctr 要保留两位小数。结果需要按 ctr 降序 、按 ad_id 升序 进行排序。
查询结果示例如下:
Ads 表: +-------+---------+---------+ | ad_id | user_id | action | +-------+---------+---------+ | 1 | 1 | Clicked | | 2 | 2 | Clicked | | 3 | 3 | Viewed | | 5 | 5 | Ignored | | 1 | 7 | Ignored | | 2 | 7 | Viewed | | 3 | 5 | Clicked | | 1 | 4 | Viewed | | 2 | 11 | Viewed | | 1 | 2 | Clicked | +-------+---------+---------+ 结果表: +-------+-------+ | ad_id | ctr | +-------+-------+ | 1 | 66.67 | | 3 | 50.00 | | 2 | 33.33 | | 5 | 0.00 | +-------+-------+ 对于 ad_id = 1, ctr = (2/(2+1)) * 100 = 66.67 对于 ad_id = 2, ctr = (1/(1+2)) * 100 = 33.33 对于 ad_id = 3, ctr = (1/(1+1)) * 100 = 50.00 对于 ad_id = 5, ctr = 0.00, 注意 ad_id = 5 没有被点击 (Clicked) 或查看 (Viewed) 过 注意我们不关心 action 为 Ingnored 的广告 结果按 ctr(降序),ad_id(升序)排序
解答 SQL架构
Create table If Not Exists Activity (player_id int , device_id int , event_date date , games_played int )Truncate table Activityinsert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-03-01' , '5' )insert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-05-02' , '6' )insert into Activity (player_id, device_id, event_date, games_played) values ('2' , '3' , '2017-06-25' , '1' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '1' , '2016-03-02' , '0' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '4' , '2018-07-03' , '5' )
Table: Activity
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ (player_id, event_date) 是这个表的两个主键 这个表显示的是某些游戏玩家的游戏活动情况 每一行是在某天使用某个设备登出之前登录并玩多个游戏(可能为0)的玩家的记录
请编写一个 SQL 查询,描述每一个玩家首次登陆的设备名称
查询结果格式在以下示例中:
Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-05-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ Result table: +-----------+-----------+ | player_id | device_id | +-----------+-----------+ | 1 | 2 | | 2 | 3 | | 3 | 1 | +-----------+-----------+
解答 SQL架构
Create table If Not Exists Product (product_id int , product_name varchar (10 ), unit_price int )Create table If Not Exists Sales (seller_id int , product_id int , buyer_id int , sale_date date , quantity int , price int )Truncate table Productinsert into Product (product_id, product_name, unit_price) values ('1' , 'S8' , '1000' )insert into Product (product_id, product_name, unit_price) values ('2' , 'G4' , '800' )insert into Product (product_id, product_name, unit_price) values ('3' , 'iPhone' , '1400' )Truncate table Salesinsert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('1' , '1' , '1' , '2019-01-21' , '2' , '2000' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('1' , '2' , '2' , '2019-02-17' , '1' , '800' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('2' , '1' , '3' , '2019-06-02' , '1' , '800' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('3' , '3' , '3' , '2019-05-13' , '2' , '2800' )
Table: Product
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | | unit_price | int | +--------------+---------+ product_id 是这张表的主键
Table: Sales
+-------------+---------+ | Column Name | Type | +-------------+---------+ | seller_id | int | | product_id | int | | buyer_id | int | | sale_date | date | | quantity | int | | price | int | +------ ------+---------+ 这个表没有主键,它可以有重复的行. product_id 是 Product 表的外键.
编写一个 SQL 查询,查询购买了 S8 手机却没有购买 iPhone 的买家。注意这里 S8 和 iPhone 是 Product 表中的产品。
查询结果格式如下图表示:
Product table: +------------+--------------+------------+ | product_id | product_name | unit_price | +------------+--------------+------------+ | 1 | S8 | 1000 | | 2 | G4 | 800 | | 3 | iPhone | 1400 | +------------+--------------+------------+ Sales table: +-----------+------------+----------+------------+----------+-------+ | seller_id | product_id | buyer_id | sale_date | quantity | price | +-----------+------------+----------+------------+----------+-------+ | 1 | 1 | 1 | 2019-01-21 | 2 | 2000 | | 1 | 2 | 2 | 2019-02-17 | 1 | 800 | | 2 | 1 | 3 | 2019-06-02 | 1 | 800 | | 3 | 3 | 3 | 2019-05-13 | 2 | 2800 | +-----------+------------+----------+------------+----------+-------+ Result table: +-------------+ | buyer_id | +-------------+ | 1 | +-------------+ id 为 1 的买家购买了一部 S8,但是却没有购买 iPhone,而 id 为 3 的买家却同时购买了这 2 部手机。
解答 SQL架构
Create table If Not Exists Product (product_id int , product_name varchar (10 ), unit_price int )Create table If Not Exists Sales (seller_id int , product_id int , buyer_id int , sale_date date , quantity int , price int )Truncate table Productinsert into Product (product_id, product_name, unit_price) values ('1' , 'S8' , '1000' )insert into Product (product_id, product_name, unit_price) values ('2' , 'G4' , '800' )insert into Product (product_id, product_name, unit_price) values ('3' , 'iPhone' , '1400' )Truncate table Salesinsert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('1' , '1' , '1' , '2019-01-21' , '2' , '2000' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('1' , '2' , '2' , '2019-02-17' , '1' , '800' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('2' , '2' , '3' , '2019-06-02' , '1' , '800' )insert into Sales (seller_id, product_id, buyer_id, sale_date, quantity, price) values ('3' , '3' , '4' , '2019-05-13' , '2' , '2800' )
Table: Product
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | | unit_price | int | +--------------+---------+ product_id 是这个表的主键
Table: Sales
+-------------+---------+ | Column Name | Type | +-------------+---------+ | seller_id | int | | product_id | int | | buyer_id | int | | sale_date | date | | quantity | int | | price | int | +------ ------+---------+ 这个表没有主键,它可以有重复的行. product_id 是 Product 表的外键.
编写一个SQL查询,报告2019年春季才售出的产品。即仅 在2019-01-01 至2019-03-31 (含)之间出售的商品。
查询结果格式如下所示:
Product table: +------------+--------------+------------+ | product_id | product_name | unit_price | +------------+--------------+------------+ | 1 | S8 | 1000 | | 2 | G4 | 800 | | 3 | iPhone | 1400 | +------------+--------------+------------+ Sales table: +-----------+------------+----------+------------+----------+-------+ | seller_id | product_id | buyer_id | sale_date | quantity | price | +-----------+------------+----------+------------+----------+-------+ | 1 | 1 | 1 | 2019-01-21 | 2 | 2000 | | 1 | 2 | 2 | 2019-02-17 | 1 | 800 | | 2 | 2 | 3 | 2019-06-02 | 1 | 800 | | 3 | 3 | 4 | 2019-05-13 | 2 | 2800 | +-----------+------------+----------+------------+----------+-------+ Result table: +-------------+--------------+ | product_id | product_name | +-------------+--------------+ | 1 | S8 | +-------------+--------------+ id为1的产品仅在2019年春季销售,其他两个产品在之后销售。
解答 SQL架构
Create table If Not Exists Weather (Id int , RecordDate date , Temperature int )Truncate table Weatherinsert into Weather (Id , RecordDate, Temperature) values ('1' , '2015-01-01' , '10' )insert into Weather (Id , RecordDate, Temperature) values ('2' , '2015-01-02' , '25' )insert into Weather (Id , RecordDate, Temperature) values ('3' , '2015-01-03' , '20' )insert into Weather (Id , RecordDate, Temperature) values ('4' , '2015-01-04' , '30' )
给定一个 Weather 表,编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 Id。
+---------+------------------+------------------+ | Id(INT) | RecordDate(DATE) | Temperature(INT) | +---------+------------------+------------------+ | 1 | 2015-01-01 | 10 | | 2 | 2015-01-02 | 25 | | 3 | 2015-01-03 | 20 | | 4 | 2015-01-04 | 30 | +---------+------------------+------------------+
例如,根据上述给定的 Weather 表格,返回如下 Id:
+----+ | Id | +----+ | 2 | | 4 | +----+
解答 SQL架构
Create table If Not Exists Project (project_id int , employee_id int )Create table If Not Exists Employee (employee_id int , name varchar (10 ), experience_years int )Truncate table Project insert into Project (project_id, employee_id) values ('1' , '1' )insert into Project (project_id, employee_id) values ('1' , '2' )insert into Project (project_id, employee_id) values ('1' , '3' )insert into Project (project_id, employee_id) values ('2' , '1' )insert into Project (project_id, employee_id) values ('2' , '4' )Truncate table Employeeinsert into Employee (employee_id, name , experience_years) values ('1' , 'Khaled' , '3' )insert into Employee (employee_id, name , experience_years) values ('2' , 'Ali' , '2' )insert into Employee (employee_id, name , experience_years) values ('3' , 'John' , '1' )insert into Employee (employee_id, name , experience_years) values ('4' , 'Doe' , '2' )
Table: Project
+-------------+---------+ | Column Name | Type | +-------------+---------+ | project_id | int | | employee_id | int | +-------------+---------+ 主键为 (project_id, employee_id)。 employee_id 是员工表 Employee 表的外键。
Table: Employee
+------------------+---------+ | Column Name | Type | +------------------+---------+ | employee_id | int | | name | varchar | | experience_years | int | +------------------+---------+ 主键是 employee_id。
编写一个SQL查询,报告所有雇员最多的项目。
查询结果格式如下所示:
Project table: +-------------+-------------+ | project_id | employee_id | +-------------+-------------+ | 1 | 1 | | 1 | 2 | | 1 | 3 | | 2 | 1 | | 2 | 4 | +-------------+-------------+ Employee table: +-------------+--------+------------------+ | employee_id | name | experience_years | +-------------+--------+------------------+ | 1 | Khaled | 3 | | 2 | Ali | 2 | | 3 | John | 1 | | 4 | Doe | 2 | +-------------+--------+------------------+ Result table: +-------------+ | project_id | +-------------+ | 1 | +-------------+ 第一个项目有3名员工,第二个项目有2名员工。
解答 SQL架构
Create table If Not Exists my_numbers (num int )Truncate table my_numbersinsert into my_numbers (num ) values ('8' )insert into my_numbers (num ) values ('8' )insert into my_numbers (num ) values ('3' )insert into my_numbers (num ) values ('3' )insert into my_numbers (num ) values ('1' )insert into my_numbers (num ) values ('4' )insert into my_numbers (num ) values ('5' )insert into my_numbers (num ) values ('6' )
表 my_numbers 的 num 字段包含很多数字,其中包括很多重复的数字。
你能写一个 SQL 查询语句,找到只出现过一次的数字中,最大的一个数字吗?
+---+ |num| +---+ | 8 | | 8 | | 3 | | 3 | | 1 | | 4 | | 5 | | 6 |
对于上面给出的样例数据,你的查询语句应该返回如下结果:
注意:
如果没有只出现一次的数字,输出 null 。
解答 SQL架构
Create table If Not Exists friend_request ( sender_id INT NOT NULL , send_to_id INT NULL , request_date DATE NULL )Create table If Not Exists request_accepted ( requester_id INT NOT NULL , accepter_id INT NULL , accept_date DATE NULL )Truncate table friend_requestinsert into friend_request (sender_id, send_to_id, request_date) values ('1' , '2' , '2016/06/01' )insert into friend_request (sender_id, send_to_id, request_date) values ('1' , '3' , '2016/06/01' )insert into friend_request (sender_id, send_to_id, request_date) values ('1' , '4' , '2016/06/01' )insert into friend_request (sender_id, send_to_id, request_date) values ('2' , '3' , '2016/06/02' )insert into friend_request (sender_id, send_to_id, request_date) values ('3' , '4' , '2016/06/09' )Truncate table request_acceptedinsert into request_accepted (requester_id, accepter_id, accept_date) values ('1' , '2' , '2016/06/03' )insert into request_accepted (requester_id, accepter_id, accept_date) values ('1' , '3' , '2016/06/08' )insert into request_accepted (requester_id, accepter_id, accept_date) values ('2' , '3' , '2016/06/08' )insert into request_accepted (requester_id, accepter_id, accept_date) values ('3' , '4' , '2016/06/09' )insert into request_accepted (requester_id, accepter_id, accept_date) values ('3' , '4' , '2016/06/10' )
在 Facebook 或者 Twitter 这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。现在给如下两个表:
表: friend_request
| sender_id | send_to_id |request_date| |-----------|------------|------------| | 1 | 2 | 2016_06-01 | | 1 | 3 | 2016_06-01 | | 1 | 4 | 2016_06-01 | | 2 | 3 | 2016_06-02 | | 3 | 4 | 2016-06-09 |
表: request_accepted
| requester_id | accepter_id |accept_date | |--------------|-------------|------------| | 1 | 2 | 2016_06-03 | | 1 | 3 | 2016-06-08 | | 2 | 3 | 2016-06-08 | | 3 | 4 | 2016-06-09 | | 3 | 4 | 2016-06-10 |
写一个查询语句,求出好友申请的通过率,用 2 位小数表示。通过率由接受好友申请的数目除以申请总数。
对于上面的样例数据,你的查询语句应该返回如下结果。
|accept_rate| |-----------| | 0.80|
注意:
通过的好友申请不一定都在表 friend_request 中。在这种情况下,你只需要统计总的被通过的申请数(不管它们在不在原来的申请中),并将它除以申请总数,得到通过率
一个好友申请发送者有可能会给接受者发几条好友申请,也有可能一个好友申请会被通过好几次。这种情况下,重复的好友申请只统计一次。
如果一个好友申请都没有,通过率为 0.00 。
解释: 总共有 5 个申请,其中 4 个是不重复且被通过的好友申请,所以成功率是 0.80 。
进阶:
你能写一个查询语句得到每个月的通过率吗?
你能求出每一天的累计通过率吗?
解答 SQL架构
Create table If Not Exists courses (student varchar (255 ), class varchar (255 ))Truncate table coursesinsert into courses (student, class ) values ('A' , 'Math' )insert into courses (student, class ) values ('B' , 'English' )insert into courses (student, class ) values ('C' , 'Math' )insert into courses (student, class ) values ('D' , 'Biology' )insert into courses (student, class ) values ('E' , 'Math' )insert into courses (student, class ) values ('F' , 'Computer' )insert into courses (student, class ) values ('G' , 'Math' )insert into courses (student, class ) values ('H' , 'Math' )insert into courses (student, class ) values ('I' , 'Math' )
有一个courses 表 ,有: student (学生) 和 class (课程) 。
请列出所有超过或等于5名学生的课。
例如,表:
+---------+------------+ | student | class | +---------+------------+ | A | Math | | B | English | | C | Math | | D | Biology | | E | Math | | F | Computer | | G | Math | | H | Math | | I | Math | +---------+------------+
应该输出:
+---------+ | class | +---------+ | Math | +---------+
Note:
解答 SQL架构
Create table If Not Exists Activity (user_id int , session_id int , activity_date date , activity_type ENUM('open_session' , 'end_session' , 'scroll_down' , 'send_message' ))Truncate table Activityinsert into Activity (user_id, session_id, activity_date, activity_type) values ('1' , '1' , '2019-07-20' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('1' , '1' , '2019-07-20' , 'scroll_down' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('1' , '1' , '2019-07-20' , 'end_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('2' , '4' , '2019-07-20' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('2' , '4' , '2019-07-21' , 'send_message' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('2' , '4' , '2019-07-21' , 'end_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '2' , '2019-07-21' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '2' , '2019-07-21' , 'send_message' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '2' , '2019-07-21' , 'end_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '5' , '2019-07-21' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '5' , '2019-07-21' , 'scroll_down' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('3' , '5' , '2019-07-21' , 'end_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('4' , '3' , '2019-06-25' , 'open_session' )insert into Activity (user_id, session_id, activity_date, activity_type) values ('4' , '3' , '2019-06-25' , 'end_session' )
Table: Activity
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | session_id | int | | activity_date | date | | activity_type | enum | +---------------+---------+ 该表没有主键,它可能有重复的行。 activity_type列是一种类型的ENUM(“ open_session”,“ end_session”,“ scroll_down”,“ send_message”)。 该表显示了社交媒体网站的用户活动。 请注意,每个会话完全属于一个用户。
编写SQL查询以查找截至2019年7月27日(含)的30天内每个用户的平均会话数,四舍五入到小数点后两位。我们要为用户计算的会话是在该时间段内至少进行了一项活动的会话。
查询结果格式如下例所示:
Activity table: +---------+------------+---------------+---------------+ | user_id | session_id | activity_date | activity_type | +---------+------------+---------------+---------------+ | 1 | 1 | 2019-07-20 | open_session | | 1 | 1 | 2019-07-20 | scroll_down | | 1 | 1 | 2019-07-20 | end_session | | 2 | 4 | 2019-07-20 | open_session | | 2 | 4 | 2019-07-21 | send_message | | 2 | 4 | 2019-07-21 | end_session | | 3 | 2 | 2019-07-21 | open_session | | 3 | 2 | 2019-07-21 | send_message | | 3 | 2 | 2019-07-21 | end_session | | 3 | 5 | 2019-07-21 | open_session | | 3 | 5 | 2019-07-21 | scroll_down | | 3 | 5 | 2019-07-21 | end_session | | 4 | 3 | 2019-06-25 | open_session | | 4 | 3 | 2019-06-25 | end_session | +---------+------------+---------------+---------------+ Result table: +---------------------------+ | average_sessions_per_user | +---------------------------+ | 1.33 | +---------------------------+ User 1 和 2 在过去30天内各自进行了1次会话,而用户3进行了2次会话,因此平均值为(1 +1 + 2)/ 3 = 1.33。
解答 SQL架构
Create table If Not Exists Employee (Id int , Salary int )Truncate table Employeeinsert into Employee (Id , Salary) values ('1' , '100' )insert into Employee (Id , Salary) values ('2' , '200' )insert into Employee (Id , Salary) values ('3' , '300' )
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
+----+--------+ | Id | Salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
+---------------------+ | SecondHighestSalary | +---------------------+ | 200 | +---------------------+
解答 SQL架构
Create table If Not Exists Queries (query_name varchar (30 ), result varchar (50 ), position int , rating int )Truncate table Queriesinsert into Queries (query_name, result , position , rating) values ('Dog' , 'Golden Retriever' , '1' , '5' )insert into Queries (query_name, result , position , rating) values ('Dog' , 'German Shepherd' , '2' , '5' )insert into Queries (query_name, result , position , rating) values ('Dog' , 'Mule' , '200' , '1' )insert into Queries (query_name, result , position , rating) values ('Cat' , 'Shirazi' , '5' , '2' )insert into Queries (query_name, result , position , rating) values ('Cat' , 'Siamese' , '3' , '3' )insert into Queries (query_name, result , position , rating) values ('Cat' , 'Sphynx' , '7' , '4' )
查询表 Queries:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | query_name | varchar | | result | varchar | | position | int | | rating | int | +-------------+---------+ 此表没有主键,并可能有重复的行。 此表包含了一些从数据库中收集的查询信息。 “位置”(position)列的值为 1 到 500 。 “评分”(rating)列的值为 1 到 5 。评分小于 3 的查询被定义为质量很差的查询。
将查询结果的质量 quality 定义为:
各查询结果的评分与其位置之间比率的平均值。
将劣质查询百分比 poor_query_percentage 为:
评分小于 3 的查询结果占全部查询结果的百分比。
编写一组 SQL 来查找每次查询的名称(query_name)、质量(quality) 和 劣质查询百分比(poor_query_percentage)。
质量(quality) 和劣质查询百分比(poor_query_percentage) 都应四舍五入到小数点后两位。
查询结果格式如下所示:
Queries table: +------------+-------------------+----------+--------+ | query_name | result | position | rating | +------------+-------------------+----------+--------+ | Dog | Golden Retriever | 1 | 5 | | Dog | German Shepherd | 2 | 5 | | Dog | Mule | 200 | 1 | | Cat | Shirazi | 5 | 2 | | Cat | Siamese | 3 | 3 | | Cat | Sphynx | 7 | 4 | +------------+-------------------+----------+--------+ Result table: +------------+---------+-----------------------+ | query_name | quality | poor_query_percentage | +------------+---------+-----------------------+ | Dog | 2.50 | 33.33 | | Cat | 0.66 | 33.33 | +------------+---------+-----------------------+ Dog 查询结果的质量为 ((5 / 1) + (5 / 2) + (1 / 200)) / 3 = 2.50 Dog 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33 Cat 查询结果的质量为 ((2 / 5) + (3 / 3) + (4 / 7)) / 3 = 0.66 Cat 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33
解答 中等 SQL架构
Create table If Not Exists Employees (employee_id int , employee_name varchar (30 ), manager_id int )Truncate table Employeesinsert into Employees (employee_id, employee_name, manager_id) values ('1' , 'Boss' , '1' )insert into Employees (employee_id, employee_name, manager_id) values ('3' , 'Alice' , '3' )insert into Employees (employee_id, employee_name, manager_id) values ('2' , 'Bob' , '1' )insert into Employees (employee_id, employee_name, manager_id) values ('4' , 'Daniel' , '2' )insert into Employees (employee_id, employee_name, manager_id) values ('7' , 'Luis' , '4' )insert into Employees (employee_id, employee_name, manager_id) values ('8' , 'John' , '3' )insert into Employees (employee_id, employee_name, manager_id) values ('9' , 'Angela' , '8' )insert into Employees (employee_id, employee_name, manager_id) values ('77' , 'Robert' , '1' )
员工表:Employees
+---------------+---------+ | Column Name | Type | +---------------+---------+ | employee_id | int | | employee_name | varchar | | manager_id | int | +---------------+---------+ employee_id 是这个表的主键。 这个表中每一行中,employee_id 表示职工的 ID,employee_name 表示职工的名字,manager_id 表示该职工汇报工作的直线经理。 这个公司 CEO 是 employee_id = 1 的人。
用 SQL 查询出所有直接或间接向公司 CEO 汇报工作的职工的 employee_id 。
由于公司规模较小,经理之间的间接关系不超过 3 个经理。
可以以任何顺序返回的结果,不需要去重。
查询结果示例如下:
Employees table: +-------------+---------------+------------+ | employee_id | employee_name | manager_id | +-------------+---------------+------------+ | 1 | Boss | 1 | | 3 | Alice | 3 | | 2 | Bob | 1 | | 4 | Daniel | 2 | | 7 | Luis | 4 | | 8 | Jhon | 3 | | 9 | Angela | 8 | | 77 | Robert | 1 | +-------------+---------------+------------+ Result table: +-------------+ | employee_id | +-------------+ | 2 | | 77 | | 4 | | 7 | +-------------+ 公司 CEO 的 employee_id 是 1. employee_id 是 2 和 77 的职员直接汇报给公司 CEO。 employee_id 是 4 的职员间接汇报给公司 CEO 4 --> 2 --> 1 。 employee_id 是 7 的职员间接汇报给公司 CEO 7 --> 4 --> 2 --> 1 。 employee_id 是 3, 8 ,9 的职员不会直接或间接的汇报给公司 CEO。
解答 SQL架构
Create table If Not Exists Logs (log_id int )Truncate table Logs insert into Logs (log_id) values ('1' )insert into Logs (log_id) values ('2' )insert into Logs (log_id) values ('3' )insert into Logs (log_id) values ('7' )insert into Logs (log_id) values ('8' )insert into Logs (log_id) values ('10' )
表:Logs
+---------------+---------+ | Column Name | Type | +---------------+---------+ | log_id | int | +---------------+---------+ id 是上表的主键。 上表的每一行包含日志表中的一个 ID。
后来一些 ID 从 Logs 表中删除。编写一个 SQL 查询得到 Logs 表中的连续区间的开始数字和结束数字。
将查询表按照 start_id 排序。
查询结果格式如下面的例子:
Logs 表: +------------+ | log_id | +------------+ | 1 | | 2 | | 3 | | 7 | | 8 | | 10 | +------------+ 结果表: +------------+--------------+ | start_id | end_id | +------------+--------------+ | 1 | 3 | | 7 | 8 | | 10 | 10 | +------------+--------------+ 结果表应包含 Logs 表中的所有区间。 从 1 到 3 在表中。 从 4 到 6 不在表中。 从 7 到 8 在表中。 9 不在表中。 10 在表中。
解答 SQL架构
Create table If Not Exists Scores (player_name varchar (20 ), gender varchar (1 ), day date , score_points int )Truncate table Scoresinsert into Scores (player_name, gender, day , score_points) values ('Aron' , 'F' , '2020-01-01' , '17' )insert into Scores (player_name, gender, day , score_points) values ('Alice' , 'F' , '2020-01-07' , '23' )insert into Scores (player_name, gender, day , score_points) values ('Bajrang' , 'M' , '2020-01-07' , '7' )insert into Scores (player_name, gender, day , score_points) values ('Khali' , 'M' , '2019-12-25' , '11' )insert into Scores (player_name, gender, day , score_points) values ('Slaman' , 'M' , '2019-12-30' , '13' )insert into Scores (player_name, gender, day , score_points) values ('Joe' , 'M' , '2019-12-31' , '3' )insert into Scores (player_name, gender, day , score_points) values ('Jose' , 'M' , '2019-12-18' , '2' )insert into Scores (player_name, gender, day , score_points) values ('Priya' , 'F' , '2019-12-31' , '23' )insert into Scores (player_name, gender, day , score_points) values ('Priyanka' , 'F' , '2019-12-30' , '17' )
表: Scores
+---------------+---------+ | Column Name | Type | +---------------+---------+ | player_name | varchar | | gender | varchar | | day | date | | score_points | int | +---------------+---------+ (gender, day)是该表的主键 一场比赛是在女队和男队之间举行的 该表的每一行表示一个名叫 (player_name) 性别为 (gender) 的参赛者在某一天获得了 (score_points) 的分数 如果参赛者是女性,那么 gender 列为 'F',如果参赛者是男性,那么 gender 列为 'M'
写一条SQL语句查询每种性别在每一天的总分,并按性别和日期对查询结果排序
下面是查询结果格式的例子:
Scores表: +-------------+--------+------------+--------------+ | player_name | gender | day | score_points | +-------------+--------+------------+--------------+ | Aron | F | 2020-01-01 | 17 | | Alice | F | 2020-01-07 | 23 | | Bajrang | M | 2020-01-07 | 7 | | Khali | M | 2019-12-25 | 11 | | Slaman | M | 2019-12-30 | 13 | | Joe | M | 2019-12-31 | 3 | | Jose | M | 2019-12-18 | 2 | | Priya | F | 2019-12-31 | 23 | | Priyanka | F | 2019-12-30 | 17 | +-------------+--------+------------+--------------+ 结果表: +--------+------------+-------+ | gender | day | total | +--------+------------+-------+ | F | 2019-12-30 | 17 | | F | 2019-12-31 | 40 | | F | 2020-01-01 | 57 | | F | 2020-01-07 | 80 | | M | 2019-12-18 | 2 | | M | 2019-12-25 | 13 | | M | 2019-12-30 | 26 | | M | 2019-12-31 | 29 | | M | 2020-01-07 | 36 | +--------+------------+-------+ 女性队伍: 第一天是 2019-12-30,Priyanka 获得 17 分,队伍的总分是 17 分 第二天是 2019-12-31, Priya 获得 23 分,队伍的总分是 40 分 第三天是 2020-01-01, Aron 获得 17 分,队伍的总分是 57 分 第四天是 2020-01-07, Alice 获得 23 分,队伍的总分是 80 分 男性队伍: 第一天是 2019-12-18, Jose 获得 2 分,队伍的总分是 2 分 第二天是 2019-12-25, Khali 获得 11 分,队伍的总分是 13 分 第三天是 2019-12-30, Slaman 获得 13 分,队伍的总分是 26 分 第四天是 2019-12-31, Joe 获得 3 分,队伍的总分是 29 分 第五天是 2020-01-07, Bajrang 获得 7 分,队伍的总分是 36 分
解答 SQL架构
Create table If Not Exists Customers (customer_id int , customer_name varchar (20 ), email varchar (30 ))Create table If Not Exists Contacts (user_id int , contact_name varchar (20 ), contact_email varchar (30 ))Create table If Not Exists Invoices (invoice_id int , price int , user_id int )Truncate table Customersinsert into Customers (customer_id, customer_name, email) values ('1' , 'Alice' , 'alice@leetcode.com' )insert into Customers (customer_id, customer_name, email) values ('2' , 'Bob' , 'bob@leetcode.com' )insert into Customers (customer_id, customer_name, email) values ('13' , 'John' , 'john@leetcode.com' )insert into Customers (customer_id, customer_name, email) values ('6' , 'Alex' , 'alex@leetcode.com' )Truncate table Contactsinsert into Contacts (user_id, contact_name, contact_email) values ('1' , 'Bob' , 'bob@leetcode.com' )insert into Contacts (user_id, contact_name, contact_email) values ('1' , 'John' , 'john@leetcode.com' )insert into Contacts (user_id, contact_name, contact_email) values ('1' , 'Jal' , 'jal@leetcode.com' )insert into Contacts (user_id, contact_name, contact_email) values ('2' , 'Omar' , 'omar@leetcode.com' )insert into Contacts (user_id, contact_name, contact_email) values ('2' , 'Meir' , 'meir@leetcode.com' )insert into Contacts (user_id, contact_name, contact_email) values ('6' , 'Alice' , 'alice@leetcode.com' )Truncate table Invoicesinsert into Invoices (invoice_id, price, user_id) values ('77' , '100' , '1' )insert into Invoices (invoice_id, price, user_id) values ('88' , '200' , '1' )insert into Invoices (invoice_id, price, user_id) values ('99' , '300' , '2' )insert into Invoices (invoice_id, price, user_id) values ('66' , '400' , '2' )insert into Invoices (invoice_id, price, user_id) values ('55' , '500' , '13' )insert into Invoices (invoice_id, price, user_id) values ('44' , '60' , '6' )
顾客表:Customers
+---------------+---------+ | Column Name | Type | +---------------+---------+ | customer_id | int | | customer_name | varchar | | email | varchar | +---------------+---------+ customer_id 是这张表的主键。 此表的每一行包含了某在线商店顾客的姓名和电子邮件。
联系方式表:Contacts
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | id | | contact_name | varchar | | contact_email | varchar | +---------------+---------+ (user_id, contact_email) 是这张表的主键。 此表的每一行表示编号为 use_id 的顾客的某位联系人的姓名和电子邮件。 此表包含每位顾客的联系人信息,但顾客的联系人不一定存在于顾客表中。
发票表:Invoices
+--------------+---------+ | Column Name | Type | +--------------+---------+ | invoice_id | int | | price | int | | user_id | int | +--------------+---------+ invoice_id 是这张表的主键。 此表的每一行分别表示编号为 use_id 的顾客拥有有一张编号为 invoice_id、价格为 price 的发票。
为每张发票 invoice_id 编写一个SQL查询以查找以下内容:
customer_name:与发票相关的顾客名称。price:发票的价格。contacts_cnt:该顾客的联系人数量。trusted_contacts_cnt:可信联系人的数量:既是该顾客的联系人又是商店顾客的联系人数量(即:可信联系人的电子邮件存在于客户表中)。
将查询的结果按照 invoice_id 排序。
查询结果的格式如下例所示:
Customers table: +-------------+---------------+--------------------+ | customer_id | customer_name | email | +-------------+---------------+--------------------+ | 1 | Alice | alice@leetcode.com | | 2 | Bob | bob@leetcode.com | | 13 | John | john@leetcode.com | | 6 | Alex | alex@leetcode.com | +-------------+---------------+--------------------+ Contacts table: +-------------+--------------+--------------------+ | user_id | contact_name | contact_email | +-------------+--------------+--------------------+ | 1 | Bob | bob@leetcode.com | | 1 | John | john@leetcode.com | | 1 | Jal | jal@leetcode.com | | 2 | Omar | omar@leetcode.com | | 2 | Meir | meir@leetcode.com | | 6 | Alice | alice@leetcode.com | +-------------+--------------+--------------------+ Invoices table: +------------+-------+---------+ | invoice_id | price | user_id | +------------+-------+---------+ | 77 | 100 | 1 | | 88 | 200 | 1 | | 99 | 300 | 2 | | 66 | 400 | 2 | | 55 | 500 | 13 | | 44 | 60 | 6 | +------------+-------+---------+ Result table: +------------+---------------+-------+--------------+----------------------+ | invoice_id | customer_name | price | contacts_cnt | trusted_contacts_cnt | +------------+---------------+-------+--------------+----------------------+ | 44 | Alex | 60 | 1 | 1 | | 55 | John | 500 | 0 | 0 | | 66 | Bob | 400 | 2 | 0 | | 77 | Alice | 100 | 3 | 2 | | 88 | Alice | 200 | 3 | 2 | | 99 | Bob | 300 | 2 | 0 | +------------+---------------+-------+--------------+----------------------+ Alice 有三位联系人,其中两位(Bob 和 John)是可信联系人。 Bob 有两位联系人, 他们中的任何一位都不是可信联系人。 Alex 只有一位联系人(Alice),并是一位可信联系人。 John 没有任何联系人。
解答 SQL架构
Create table If Not Exists tree (id int , p_id int )Truncate table treeinsert into tree (id , p_id) values ('1' , 'None' )insert into tree (id , p_id) values ('2' , '1' )insert into tree (id , p_id) values ('3' , '1' )insert into tree (id , p_id) values ('4' , '2' )insert into tree (id , p_id) values ('5' , '2' )
给定一个表 tree,id 是树节点的编号, p_id 是它父节点的 id 。
+----+------+ | id | p_id | +----+------+ | 1 | null | | 2 | 1 | | 3 | 1 | | 4 | 2 | | 5 | 2 | +----+------+
树中每个节点属于以下三种类型之一:
叶子:如果这个节点没有任何孩子节点。
根:如果这个节点是整棵树的根,即没有父节点。
内部节点:如果这个节点既不是叶子节点也不是根节点。
写一个查询语句,输出所有节点的编号和节点的类型,并将结果按照节点编号排序。上面样例的结果为:
+----+------+ | id | Type | +----+------+ | 1 | Root | | 2 | Inner| | 3 | Leaf | | 4 | Leaf | | 5 | Leaf | +----+------+
解释
节点 ‘1’ 是根节点,因为它的父节点是 NULL ,同时它有孩子节点 ‘2’ 和 ‘3’ 。
节点 ‘2’ 是内部节点,因为它有父节点 ‘1’ ,也有孩子节点 ‘4’ 和 ‘5’ 。
节点 ‘3’, ‘4’ 和 ‘5’ 都是叶子节点,因为它们都有父节点同时没有孩子节点。
样例中树的形态如下:
注意
如果树中只有一个节点,你只需要输出它的根属性。
解答 SQL架构
Create table If Not Exists Project (project_id int , employee_id int )Create table If Not Exists Employee (employee_id int , name varchar (10 ), experience_years int )Truncate table Project insert into Project (project_id, employee_id) values ('1' , '1' )insert into Project (project_id, employee_id) values ('1' , '2' )insert into Project (project_id, employee_id) values ('1' , '3' )insert into Project (project_id, employee_id) values ('2' , '1' )insert into Project (project_id, employee_id) values ('2' , '4' )Truncate table Employeeinsert into Employee (employee_id, name , experience_years) values ('1' , 'Khaled' , '3' )insert into Employee (employee_id, name , experience_years) values ('2' , 'Ali' , '2' )insert into Employee (employee_id, name , experience_years) values ('3' , 'John' , '3' )insert into Employee (employee_id, name , experience_years) values ('4' , 'Doe' , '2' )
项目表 Project:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | project_id | int | | employee_id | int | +-------------+---------+ (project_id, employee_id) 是这个表的主键 employee_id 是员工表 Employee 的外键
员工表 Employee:
+------------------+---------+ | Column Name | Type | +------------------+---------+ | employee_id | int | | name | varchar | | experience_years | int | +------------------+---------+ employee_id 是这个表的主键
写 一个 SQL 查询语句,报告在每一个项目中经验最丰富的雇员是谁。如果出现经验年数相同的情况,请报告所有具有最大经验年数的员工。
查询结果格式在以下示例中:
Project 表: +-------------+-------------+ | project_id | employee_id | +-------------+-------------+ | 1 | 1 | | 1 | 2 | | 1 | 3 | | 2 | 1 | | 2 | 4 | +-------------+-------------+ Employee 表: +-------------+--------+------------------+ | employee_id | name | experience_years | +-------------+--------+------------------+ | 1 | Khaled | 3 | | 2 | Ali | 2 | | 3 | John | 3 | | 4 | Doe | 2 | +-------------+--------+------------------+ Result 表: +-------------+---------------+ | project_id | employee_id | +-------------+---------------+ | 1 | 1 | | 1 | 3 | | 2 | 1 | +-------------+---------------+ employee_id 为 1 和 3 的员工在 project_id 为 1 的项目中拥有最丰富的经验。在 project_id 为 2 的项目中,employee_id 为 1 的员工拥有最丰富的经验。
解答 SQL架构
Create table If Not Exists seat(id int , student varchar (255 ))Truncate table seatinsert into seat (id , student) values ('1' , 'Abbot' )insert into seat (id , student) values ('2' , 'Doris' )insert into seat (id , student) values ('3' , 'Emerson' )insert into seat (id , student) values ('4' , 'Green' )insert into seat (id , student) values ('5' , 'Jeames' )
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的
小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
示例:
+---------+---------+ | id | student | +---------+---------+ | 1 | Abbot | | 2 | Doris | | 3 | Emerson | | 4 | Green | | 5 | Jeames | +---------+---------+
假如数据输入的是上表,则输出结果如下:
+---------+---------+ | id | student | +---------+---------+ | 1 | Doris | | 2 | Abbot | | 3 | Green | | 4 | Emerson | | 5 | Jeames | +---------+---------+
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
解答 SQL架构
Create table If Not Exists Employee (Id int , Name varchar (255 ), Department varchar (255 ), ManagerId int )Truncate table Employeeinsert into Employee (Id , Name , Department, ManagerId) values ('101' , 'John' , 'A' , 'None' )insert into Employee (Id , Name , Department, ManagerId) values ('102' , 'Dan' , 'A' , '101' )insert into Employee (Id , Name , Department, ManagerId) values ('103' , 'James' , 'A' , '101' )insert into Employee (Id , Name , Department, ManagerId) values ('104' , 'Amy' , 'A' , '101' )insert into Employee (Id , Name , Department, ManagerId) values ('105' , 'Anne' , 'A' , '101' )insert into Employee (Id , Name , Department, ManagerId) values ('106' , 'Ron' , 'B' , '101' )
Employee 表包含所有员工和他们的经理。每个员工都有一个 Id,并且还有一列是经理的 Id。
+------+----------+-----------+----------+ |Id |Name |Department |ManagerId | +------+----------+-----------+----------+ |101 |John |A |null | |102 |Dan |A |101 | |103 |James |A |101 | |104 |Amy |A |101 | |105 |Anne |A |101 | |106 |Ron |B |101 | +------+----------+-----------+----------+
给定 Employee 表,请编写一个SQL查询来查找至少有5名直接下属的经理。对于上表,您的SQL查询应该返回:
+-------+ | Name | +-------+ | John | +-------+
注意:
解答 SQL架构
Create table If Not Exists Activity (player_id int , device_id int , event_date date , games_played int )Truncate table Activityinsert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-03-01' , '5' )insert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-05-02' , '6' )insert into Activity (player_id, device_id, event_date, games_played) values ('1' , '3' , '2017-06-25' , '1' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '1' , '2016-03-02' , '0' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '4' , '2018-07-03' , '5' )
Table: Activity
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ (player_id,event_date)是此表的主键。 这张表显示了某些游戏的玩家的活动情况。 每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0 )。
编写一个 SQL 查询,同时报告每组玩家和日期,以及玩家到目前为止玩了多少游戏。也就是说,在此日期之前玩家所玩的游戏总数。详细情况请查看示例。
查询结果格式如下所示:
Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-05-02 | 6 | | 1 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ Result table: +-----------+------------+---------------------+ | player_id | event_date | games_played_so_far | +-----------+------------+---------------------+ | 1 | 2016-03-01 | 5 | | 1 | 2016-05-02 | 11 | | 1 | 2017-06-25 | 12 | | 3 | 2016-03-02 | 0 | | 3 | 2018-07-03 | 5 | +-----------+------------+---------------------+ 对于 ID 为 1 的玩家,2016-05-02 共玩了 5+6=11 个游戏,2017-06-25 共玩了 5+6+1=12 个游戏。 对于 ID 为 3 的玩家,2018-07-03 共玩了 0+5=5 个游戏。 请注意,对于每个玩家,我们只关心玩家的登录日期。
解答 难度中等5收藏分享切换为英文关注反馈
SQL架构
Create table If Not Exists Customer (customer_id int, name varchar(20), visited_on date, amount int) Truncate table Customer insert into Customer (customer_id, name, visited_on, amount) values ('1', 'Jhon', '2019-01-01', '100') insert into Customer (customer_id, name, visited_on, amount) values ('2', 'Daniel', '2019-01-02', '110') insert into Customer (customer_id, name, visited_on, amount) values ('3', 'Jade', '2019-01-03', '120') insert into Customer (customer_id, name, visited_on, amount) values ('4', 'Khaled', '2019-01-04', '130') insert into Customer (customer_id, name, visited_on, amount) values ('5', 'Winston', '2019-01-05', '110') insert into Customer (customer_id, name, visited_on, amount) values ('6', 'Elvis', '2019-01-06', '140') insert into Customer (customer_id, name, visited_on, amount) values ('7', 'Anna', '2019-01-07', '150') insert into Customer (customer_id, name, visited_on, amount) values ('8', 'Maria', '2019-01-08', '80') insert into Customer (customer_id, name, visited_on, amount) values ('9', 'Jaze', '2019-01-09', '110') insert into Customer (customer_id, name, visited_on, amount) values ('1', 'Jhon', '2019-01-10', '130') insert into Customer (customer_id, name, visited_on, amount) values ('3', 'Jade', '2019-01-10', '150')
表: Customer
+---------------+---------+ | Column Name | Type | +---------------+---------+ | customer_id | int | | name | varchar | | visited_on | date | | amount | int | +---------------+---------+ (customer_id, visited_on) 是该表的主键 该表包含一家餐馆的顾客交易数据 visited_on 表示 (customer_id) 的顾客在 visited_on 那天访问了餐馆 amount 是一个顾客某一天的消费总额
你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)
写一条 SQL 查询计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值
查询结果格式的例子如下:
查询结果按 visited_on 排序
average_amount 要 保留两位小数 ,日期数据的格式为 (‘YYYY-MM-DD’)
Customer 表: +-------------+--------------+--------------+-------------+ | customer_id | name | visited_on | amount | +-------------+--------------+--------------+-------------+ | 1 | Jhon | 2019-01-01 | 100 | | 2 | Daniel | 2019-01-02 | 110 | | 3 | Jade | 2019-01-03 | 120 | | 4 | Khaled | 2019-01-04 | 130 | | 5 | Winston | 2019-01-05 | 110 | | 6 | Elvis | 2019-01-06 | 140 | | 7 | Anna | 2019-01-07 | 150 | | 8 | Maria | 2019-01-08 | 80 | | 9 | Jaze | 2019-01-09 | 110 | | 1 | Jhon | 2019-01-10 | 130 | | 3 | Jade | 2019-01-10 | 150 | +-------------+--------------+--------------+-------------+ 结果表: +--------------+--------------+----------------+ | visited_on | amount | average_amount | +--------------+--------------+----------------+ | 2019-01-07 | 860 | 122.86 | | 2019-01-08 | 840 | 120 | | 2019-01-09 | 840 | 120 | | 2019-01-10 | 1000 | 142.86 | +--------------+--------------+----------------+ 第一个七天消费平均值从 2019-01-01 到 2019-01-07 是 (100 + 110 + 120 + 130 + 110 + 140 + 150)/7 = 122.86 第二个七天消费平均值从 2019-01-02 到 2019-01-08 是 (110 + 120 + 130 + 110 + 140 + 150 + 80)/7 = 120 第三个七天消费平均值从 2019-01-03 到 2019-01-09 是 (120 + 130 + 110 + 140 + 150 + 80 + 110)/7 = 120 第四个七天消费平均值从 2019-01-04 到 2019-01-10 是 (130 + 110 + 140 + 150 + 80 + 110 + 130 + 150)/7 = 142.86
SQL架构
Create table If Not Exists Customer (customer_id int , product_key int )Create table Product (product_key int )Truncate table Customerinsert into Customer (customer_id, product_key) values ('1' , '5' )insert into Customer (customer_id, product_key) values ('2' , '6' )insert into Customer (customer_id, product_key) values ('3' , '5' )insert into Customer (customer_id, product_key) values ('3' , '6' )insert into Customer (customer_id, product_key) values ('1' , '6' )Truncate table Productinsert into Product (product_key) values ('5' )insert into Product (product_key) values ('6' )
Customer 表:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | customer_id | int | | product_key | int | +-------------+---------+ product_key 是 Product 表的外键。
Product 表:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | product_key | int | +-------------+---------+ product_key 是这张表的主键。
写一条 SQL 查询语句,从 Customer 表中查询购买了 Product 表中所有产品的客户的 id。
示例:
Customer 表: +-------------+-------------+ | customer_id | product_key | +-------------+-------------+ | 1 | 5 | | 2 | 6 | | 3 | 5 | | 3 | 6 | | 1 | 6 | +-------------+-------------+ Product 表: +-------------+ | product_key | +-------------+ | 5 | | 6 | +-------------+ Result 表: +-------------+ | customer_id | +-------------+ | 1 | | 3 | +-------------+ 购买了所有产品(5 和 6)的客户的 id 是 1 和 3 。
解答 SQL架构
Create table If Not Exists Queue (person_id int , person_name varchar (30 ), weight int , turn int )Truncate table Queueinsert into Queue (person_id, person_name, weight, turn) values ('5' , 'George Washington' , '250' , '1' )insert into Queue (person_id, person_name, weight, turn) values ('4' , 'Thomas Jefferson' , '175' , '5' )insert into Queue (person_id, person_name, weight, turn) values ('3' , 'John Adams' , '350' , '2' )insert into Queue (person_id, person_name, weight, turn) values ('6' , 'Thomas Jefferson' , '400' , '3' )insert into Queue (person_id, person_name, weight, turn) values ('1' , 'James Elephant' , '500' , '6' )insert into Queue (person_id, person_name, weight, turn) values ('2' , 'Will Johnliams' , '200' , '4' )
表: Queue
+-------------+---------+ | Column Name | Type | +-------------+---------+ | person_id | int | | person_name | varchar | | weight | int | | turn | int | +-------------+---------+ person_id 是这个表的主键。 该表展示了所有等待电梯的人的信息。 表中 person_id 和 turn 列将包含从 1 到 n 的所有数字,其中 n 是表中的行数。
电梯最大载重量为 1000 。
写一条 SQL 查询语句查找最后一个能进入电梯且不超过重量限制的 person_name 。题目确保队列中第一位的人可以进入电梯 。
查询结果如下所示 :
Queue 表 +-----------+-------------------+--------+------+ | person_id | person_name | weight | turn | +-----------+-------------------+--------+------+ | 5 | George Washington | 250 | 1 | | 3 | John Adams | 350 | 2 | | 6 | Thomas Jefferson | 400 | 3 | | 2 | Will Johnliams | 200 | 4 | | 4 | Thomas Jefferson | 175 | 5 | | 1 | James Elephant | 500 | 6 | +-----------+-------------------+--------+------+ Result 表 +-------------------+ | person_name | +-------------------+ | Thomas Jefferson | +-------------------+ 为了简化,Queue 表按 trun 列由小到大排序。 上例中 George Washington(id 5), John Adams(id 3) 和 Thomas Jefferson(id 6) 将可以进入电梯,因为他们的体重和为 250 + 350 + 400 = 1000。 Thomas Jefferson(id 6) 是最后一个体重合适并进入电梯的人。
解答 SQL架构
Create table If Not Exists Events (business_id int , event_type varchar (10 ), occurences int )Truncate table Events insert into Events (business_id, event_type, occurences) values ('1' , 'reviews' , '7' )insert into Events (business_id, event_type, occurences) values ('3' , 'reviews' , '3' )insert into Events (business_id, event_type, occurences) values ('1' , 'ads' , '11' )insert into Events (business_id, event_type, occurences) values ('2' , 'ads' , '7' )insert into Events (business_id, event_type, occurences) values ('3' , 'ads' , '6' )insert into Events (business_id, event_type, occurences) values ('1' , 'page views' , '3' )insert into Events (business_id, event_type, occurences) values ('2' , 'page views' , '12' )
事件表:Events
+---------------+---------+ | Column Name | Type | +---------------+---------+ | business_id | int | | event_type | varchar | | occurences | int | +---------------+---------+ 此表的主键是 (business_id, event_type)。 表中的每一行记录了某种类型的事件在某些业务中多次发生的信息。
写一段 SQL 来查询所有活跃的业务。
如果一个业务的某个事件类型的发生次数大于此事件类型在所有业务中的平均发生次数,并且该业务至少有两个这样的事件类型,那么该业务就可被看做是活跃业务。
查询结果格式如下所示:
Events table: +-------------+------------+------------+ | business_id | event_type | occurences | +-------------+------------+------------+ | 1 | reviews | 7 | | 3 | reviews | 3 | | 1 | ads | 11 | | 2 | ads | 7 | | 3 | ads | 6 | | 1 | page views | 3 | | 2 | page views | 12 | +-------------+------------+------------+ 结果表 +-------------+ | business_id | +-------------+ | 1 | +-------------+ 'reviews'、 'ads' 和 'page views' 的总平均发生次数分别是 (7+3)/2=5, (11+7+6)/3=8, (3+12)/2=7.5。 id 为 1 的业务有 7 个 'reviews' 事件(大于 5)和 11 个 'ads' 事件(大于 8),所以它是活跃业务。
解答 SQL架构
CREATE TABLE If Not Exists point_2d (x INT NOT NULL , y INT NOT NULL )Truncate table point_2dinsert into point_2d (x, y) values ('-1' , '-1' )insert into point_2d (x, y) values ('0' , '0' )insert into point_2d (x, y) values ('-1' , '-2' )
表 point_2d 保存了所有点(多于 2 个点)的坐标 (x,y) ,这些点在平面上两两不重合。
写一个查询语句找到两点之间的最近距离,保留 2 位小数。
| x | y | |----|----| | -1 | -1 | | 0 | 0 | | -1 | -2 |
最近距离在点 (-1,-1) 和(-1,2) 之间,距离为 1.00 。所以输出应该为:
| shortest | |----------| | 1.00 |
注意: 任意点之间的最远距离小于 10000 。
解答 SQL架构
create table if not exists Transactions (id int , country varchar (4 ), state enum('approved' , 'declined' ), amount int , trans_date date )Truncate table Transactionsinsert into Transactions (id , country, state, amount, trans_date) values ('121' , 'US' , 'approved' , '1000' , '2018-12-18' )insert into Transactions (id , country, state, amount, trans_date) values ('122' , 'US' , 'declined' , '2000' , '2018-12-19' )insert into Transactions (id , country, state, amount, trans_date) values ('123' , 'US' , 'approved' , '2000' , '2019-01-01' )insert into Transactions (id , country, state, amount, trans_date) values ('124' , 'DE' , 'approved' , '2000' , '2019-01-07' )
Table: Transactions
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | country | varchar | | state | enum | | amount | int | | trans_date | date | +---------------+---------+ id 是这个表的主键。 该表包含有关传入事务的信息。 state 列类型为 “[”批准“,”拒绝“] 之一。
编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。
查询结果格式如下所示:
Transactions table: +------+---------+----------+--------+------------+ | id | country | state | amount | trans_date | +------+---------+----------+--------+------------+ | 121 | US | approved | 1000 | 2018-12-18 | | 122 | US | declined | 2000 | 2018-12-19 | | 123 | US | approved | 2000 | 2019-01-01 | | 124 | DE | approved | 2000 | 2019-01-07 | +------+---------+----------+--------+------------+ Result table: +----------+---------+-------------+----------------+--------------------+-----------------------+ | month | country | trans_count | approved_count | trans_total_amount | approved_total_amount | +----------+---------+-------------+----------------+--------------------+-----------------------+ | 2018-12 | US | 2 | 1 | 3000 | 1000 | | 2019-01 | US | 1 | 1 | 2000 | 2000 | | 2019-01 | DE | 1 | 1 | 2000 | 2000 | +----------+---------+-------------+----------------+--------------------+-----------------------+
解答 SQL架构
Create table If Not Exists Enrollments (student_id int , course_id int , grade int )Truncate table Enrollmentsinsert into Enrollments (student_id, course_id, grade) values ('2' , '2' , '95' )insert into Enrollments (student_id, course_id, grade) values ('2' , '3' , '95' )insert into Enrollments (student_id, course_id, grade) values ('1' , '1' , '90' )insert into Enrollments (student_id, course_id, grade) values ('1' , '2' , '99' )insert into Enrollments (student_id, course_id, grade) values ('3' , '1' , '80' )insert into Enrollments (student_id, course_id, grade) values ('3' , '2' , '75' )insert into Enrollments (student_id, course_id, grade) values ('3' , '3' , '82' )
表:Enrollments
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | course_id | int | | grade | int | +---------------+---------+ (student_id, course_id) 是该表的主键。
编写一个 SQL 查询,查询每位学生获得的最高成绩和它所对应的科目,若科目成绩并列,取 course_id 最小的一门。查询结果需按 student_id 增序进行排序。
查询结果格式如下所示:
Enrollments 表: +------------+-------------------+ | student_id | course_id | grade | +------------+-----------+-------+ | 2 | 2 | 95 | | 2 | 3 | 95 | | 1 | 1 | 90 | | 1 | 2 | 99 | | 3 | 1 | 80 | | 3 | 2 | 75 | | 3 | 3 | 82 | +------------+-----------+-------+ Result 表: +------------+-------------------+ | student_id | course_id | grade | +------------+-----------+-------+ | 1 | 2 | 99 | | 2 | 2 | 95 | | 3 | 3 | 82 | +------------+-----------+-------+
解答 SQL架构
Create table If Not Exists Scores (Id int , Score DECIMAL (3 ,2 ))Truncate table Scoresinsert into Scores (Id , Score) values ('1' , '3.5' )insert into Scores (Id , Score) values ('2' , '3.65' )insert into Scores (Id , Score) values ('3' , '4.0' )insert into Scores (Id , Score) values ('4' , '3.85' )insert into Scores (Id , Score) values ('5' , '4.0' )insert into Scores (Id , Score) values ('6' , '3.65' )
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+----+-------+ | Id | Score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
+-------+------+ | Score | Rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | | 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+
解答 SQL架构
Create table If Not Exists Friendship (user1_id int , user2_id int )Create table If Not Exists Likes (user_id int , page_id int )Truncate table Friendshipinsert into Friendship (user1_id, user2_id) values ('1' , '2' )insert into Friendship (user1_id, user2_id) values ('1' , '3' )insert into Friendship (user1_id, user2_id) values ('1' , '4' )insert into Friendship (user1_id, user2_id) values ('2' , '3' )insert into Friendship (user1_id, user2_id) values ('2' , '4' )insert into Friendship (user1_id, user2_id) values ('2' , '5' )insert into Friendship (user1_id, user2_id) values ('6' , '1' )Truncate table Likesinsert into Likes (user_id, page_id) values ('1' , '88' )insert into Likes (user_id, page_id) values ('2' , '23' )insert into Likes (user_id, page_id) values ('3' , '24' )insert into Likes (user_id, page_id) values ('4' , '56' )insert into Likes (user_id, page_id) values ('5' , '11' )insert into Likes (user_id, page_id) values ('6' , '33' )insert into Likes (user_id, page_id) values ('2' , '77' )insert into Likes (user_id, page_id) values ('3' , '77' )insert into Likes (user_id, page_id) values ('6' , '88' )
朋友关系列表: Friendship
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user1_id | int | | user2_id | int | +---------------+---------+ 这张表的主键是 (user1_id, user2_id)。 这张表的每一行代表着 user1_id 和 user2_id 之间存在着朋友关系。
喜欢列表: Likes
+-------------+---------+ | Column Name | Type | +-------------+---------+ | user_id | int | | page_id | int | +-------------+---------+ 这张表的主键是 (user_id, page_id)。 这张表的每一行代表着 user_id 喜欢 page_id。
写一段 SQL 向user_id = 1 的用户,推荐其朋友们喜欢的页面。不要推荐该用户已经喜欢的页面。
你返回的结果中不应当包含重复项。
返回结果的格式如下例所示:
Friendship table: +----------+----------+ | user1_id | user2_id | +----------+----------+ | 1 | 2 | | 1 | 3 | | 1 | 4 | | 2 | 3 | | 2 | 4 | | 2 | 5 | | 6 | 1 | +----------+----------+ Likes table: +---------+---------+ | user_id | page_id | +---------+---------+ | 1 | 88 | | 2 | 23 | | 3 | 24 | | 4 | 56 | | 5 | 11 | | 6 | 33 | | 2 | 77 | | 3 | 77 | | 6 | 88 | +---------+---------+ Result table: +------------------+ | recommended_page | +------------------+ | 23 | | 24 | | 56 | | 33 | | 77 | +------------------+ 用户1 同 用户2, 3, 4, 6 是朋友关系。 推荐页面为: 页面23 来自于 用户2, 页面24 来自于 用户3, 页面56 来自于 用户3 以及 页面33 来自于 用户6。 页面77 同时被 用户2 和 用户3 推荐。 页面88 没有被推荐,因为 用户1 已经喜欢了它。
SQL架构
Create table If Not Exists Products (product_id int , new_price int , change_date date )Truncate table Productsinsert into Products (product_id, new_price, change_date) values ('1' , '20' , '2019-08-14' )insert into Products (product_id, new_price, change_date) values ('2' , '50' , '2019-08-14' )insert into Products (product_id, new_price, change_date) values ('1' , '30' , '2019-08-15' )insert into Products (product_id, new_price, change_date) values ('1' , '35' , '2019-08-16' )insert into Products (product_id, new_price, change_date) values ('2' , '65' , '2019-08-17' )insert into Products (product_id, new_price, change_date) values ('3' , '20' , '2019-08-18' )
产品数据表: Products
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | new_price | int | | change_date | date | +---------------+---------+ 这张表的主键是 (product_id, change_date)。 这张表的每一行分别记录了 某产品 在某个日期 更改后 的新价格。
写一段 SQL来查找在 2019-08-16 时全部产品的价格,假设所有产品在修改前的价格都是 10。
查询结果格式如下例所示:
Products table: +------------+-----------+-------------+ | product_id | new_price | change_date | +------------+-----------+-------------+ | 1 | 20 | 2019-08-14 | | 2 | 50 | 2019-08-14 | | 1 | 30 | 2019-08-15 | | 1 | 35 | 2019-08-16 | | 2 | 65 | 2019-08-17 | | 3 | 20 | 2019-08-18 | +------------+-----------+-------------+ Result table: +------------+-------+ | product_id | price | +------------+-------+ | 2 | 50 | | 1 | 35 | | 3 | 10 | +------------+-------+
解答 SQL架构
Create table If Not Exists request_accepted ( requester_id INT NOT NULL , accepter_id INT NULL , accept_date DATE NULL )Truncate table request_acceptedinsert into request_accepted (requester_id, accepter_id, accept_date) values ('1' , '2' , '2016/06/03' )insert into request_accepted (requester_id, accepter_id, accept_date) values ('1' , '3' , '2016/06/08' )insert into request_accepted (requester_id, accepter_id, accept_date) values ('2' , '3' , '2016/06/08' )insert into request_accepted (requester_id, accepter_id, accept_date) values ('3' , '4' , '2016/06/09' )
在 Facebook 或者 Twitter 这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。
表 request_accepted 存储了所有好友申请通过的数据记录,其中, requester_id 和 accepter_id 都是用户的编号。
| requester_id | accepter_id | accept_date| |--------------|-------------|------------| | 1 | 2 | 2016_06-03 | | 1 | 3 | 2016-06-08 | | 2 | 3 | 2016-06-08 | | 3 | 4 | 2016-06-09 |
写一个查询语句,求出谁拥有最多的好友和他拥有的好友数目。对于上面的样例数据,结果为:
| id | num | |----|-----| | 3 | 3 |
注意:
保证拥有最多好友数目的只有 1 个人。
好友申请只会被接受一次,所以不会有 requester_id 和 accepter_id 值都相同的重复记录。
解释:
编号为 ‘3’ 的人是编号为 ‘1’,’2’ 和 ‘4’ 的好友,所以他总共有 3 个好友,比其他人都多。
进阶:
在真实世界里,可能会有多个人拥有好友数相同且最多,你能找到所有这些人吗?
解答 SQL架构
Create table If Not Exists Friends (id int , name varchar (30 ), activity varchar (30 ))Create table If Not Exists Activities (id int , name varchar (30 ))Truncate table Friendsinsert into Friends (id , name , activity) values ('1' , 'Jonathan D.' , 'Eating' )insert into Friends (id , name , activity) values ('2' , 'Jade W.' , 'Singing' )insert into Friends (id , name , activity) values ('3' , 'Victor J.' , 'Singing' )insert into Friends (id , name , activity) values ('4' , 'Elvis Q.' , 'Eating' )insert into Friends (id , name , activity) values ('5' , 'Daniel A.' , 'Eating' )insert into Friends (id , name , activity) values ('6' , 'Bob B.' , 'Horse Riding' )Truncate table Activitiesinsert into Activities (id , name ) values ('1' , 'Eating' )insert into Activities (id , name ) values ('2' , 'Singing' )insert into Activities (id , name ) values ('3' , 'Horse Riding' )
表: Friends
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | | activity | varchar | +---------------+---------+ id 是朋友的 id 和该表的主键 name 是朋友的名字 activity 是朋友参加的活动的名字
表: Activities
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | +---------------+---------+ id 是该表的主键 name 是活动的名字
写一条 SQL 查询那些既没有最多,也没有最少参与者的活动的名字
可以以任何顺序返回结果,Activities 表的每项活动的参与者都来自 Friends 表
下面是查询结果格式的例子:
Friends 表: +------+--------------+---------------+ | id | name | activity | +------+--------------+---------------+ | 1 | Jonathan D. | Eating | | 2 | Jade W. | Singing | | 3 | Victor J. | Singing | | 4 | Elvis Q. | Eating | | 5 | Daniel A. | Eating | | 6 | Bob B. | Horse Riding | +------+--------------+---------------+ Activities 表: +------+--------------+ | id | name | +------+--------------+ | 1 | Eating | | 2 | Singing | | 3 | Horse Riding | +------+--------------+ Result 表: +--------------+ | activity | +--------------+ | Singing | +--------------+ Eating 活动有三个人参加, 是最多人参加的活动 (Jonathan D. , Elvis Q. and Daniel A.) Horse Riding 活动有一个人参加, 是最少人参加的活动 (Bob B.) Singing 活动有两个人参加 (Victor J. and Jade W.)
解答 SQL架构
Create table If Not Exists Users (user_id int , join_date date , favorite_brand varchar (10 ))create table if not exists Orders (order_id int , order_date date , item_id int , buyer_id int , seller_id int )create table if not exists Items (item_id int , item_brand varchar (10 ))Truncate table Users insert into Users (user_id, join_date, favorite_brand) values ('1' , '2018-01-01' , 'Lenovo' )insert into Users (user_id, join_date, favorite_brand) values ('2' , '2018-02-09' , 'Samsung' )insert into Users (user_id, join_date, favorite_brand) values ('3' , '2018-01-19' , 'LG' )insert into Users (user_id, join_date, favorite_brand) values ('4' , '2018-05-21' , 'HP' )Truncate table Ordersinsert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('1' , '2019-08-01' , '4' , '1' , '2' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('2' , '2018-08-02' , '2' , '1' , '3' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('3' , '2019-08-03' , '3' , '2' , '3' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('4' , '2018-08-04' , '1' , '4' , '2' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('5' , '2018-08-04' , '1' , '3' , '4' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('6' , '2019-08-05' , '2' , '2' , '4' )Truncate table Itemsinsert into Items (item_id, item_brand) values ('1' , 'Samsung' )insert into Items (item_id, item_brand) values ('2' , 'Lenovo' )insert into Items (item_id, item_brand) values ('3' , 'LG' )insert into Items (item_id, item_brand) values ('4' , 'HP' )
Table: Users
+----------------+---------+ | Column Name | Type | +----------------+---------+ | user_id | int | | join_date | date | | favorite_brand | varchar | +----------------+---------+ 此表主键是 user_id,表中描述了购物网站的用户信息,用户可以在此网站上进行商品买卖。
Table: Orders
+---------------+---------+ | Column Name | Type | +---------------+---------+ | order_id | int | | order_date | date | | item_id | int | | buyer_id | int | | seller_id | int | +---------------+---------+ 此表主键是 order_id,外键是 item_id 和(buyer_id,seller_id)。
Table: Item
+---------------+---------+ | Column Name | Type | +---------------+---------+ | item_id | int | | item_brand | varchar | +---------------+---------+ 此表主键是 item_id。
请写出一条SQL语句以查询每个用户的注册日期和在 2019 年作为买家的订单总数。
查询结果格式如下:
Users table: +---------+------------+----------------+ | user_id | join_date | favorite_brand | +---------+------------+----------------+ | 1 | 2018-01-01 | Lenovo | | 2 | 2018-02-09 | Samsung | | 3 | 2018-01-19 | LG | | 4 | 2018-05-21 | HP | +---------+------------+----------------+ Orders table: +----------+------------+---------+----------+-----------+ | order_id | order_date | item_id | buyer_id | seller_id | +----------+------------+---------+----------+-----------+ | 1 | 2019-08-01 | 4 | 1 | 2 | | 2 | 2018-08-02 | 2 | 1 | 3 | | 3 | 2019-08-03 | 3 | 2 | 3 | | 4 | 2018-08-04 | 1 | 4 | 2 | | 5 | 2018-08-04 | 1 | 3 | 4 | | 6 | 2019-08-05 | 2 | 2 | 4 | +----------+------------+---------+----------+-----------+ Items table: +---------+------------+ | item_id | item_brand | +---------+------------+ | 1 | Samsung | | 2 | Lenovo | | 3 | LG | | 4 | HP | +---------+------------+ Result table: +-----------+------------+----------------+ | buyer_id | join_date | orders_in_2019 | +-----------+------------+----------------+ | 1 | 2018-01-01 | 1 | | 2 | 2018-02-09 | 2 | | 3 | 2018-01-19 | 0 | | 4 | 2018-05-21 | 0 | +-----------+------------+----------------+
解答 SQL架构
Create table If Not Exists Delivery (delivery_id int , customer_id int , order_date date , customer_pref_delivery_date date )Truncate table Deliveryinsert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('1' , '1' , '2019-08-01' , '2019-08-02' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('2' , '2' , '2019-08-02' , '2019-08-02' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('3' , '1' , '2019-08-11' , '2019-08-12' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('4' , '3' , '2019-08-24' , '2019-08-24' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('5' , '3' , '2019-08-21' , '2019-08-22' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('6' , '2' , '2019-08-11' , '2019-08-13' )insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('7' , '4' , '2019-08-09' , '2019-08-09' )
配送表: Delivery
+-----------------------------+---------+ | Column Name | Type | +-----------------------------+---------+ | delivery_id | int | | customer_id | int | | order_date | date | | customer_pref_delivery_date | date | +-----------------------------+---------+ delivery_id 是表的主键。 该表保存着顾客的食物配送信息,顾客在某个日期下了订单,并指定了一个期望的配送日期(和下单日期相同或者在那之后)。
如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。
「首次订单」是顾客最早创建的订单。我们保证一个顾客只会有一个「首次订单」。
写一条 SQL 查询语句获取即时订单在所有用户的首次订单中的比例。保留两位小数。
查询结果如下所示:
Delivery 表: +-------------+-------------+------------+-----------------------------+ | delivery_id | customer_id | order_date | customer_pref_delivery_date | +-------------+-------------+------------+-----------------------------+ | 1 | 1 | 2019-08-01 | 2019-08-02 | | 2 | 2 | 2019-08-02 | 2019-08-02 | | 3 | 1 | 2019-08-11 | 2019-08-12 | | 4 | 3 | 2019-08-24 | 2019-08-24 | | 5 | 3 | 2019-08-21 | 2019-08-22 | | 6 | 2 | 2019-08-11 | 2019-08-13 | | 7 | 4 | 2019-08-09 | 2019-08-09 | +-------------+-------------+------------+-----------------------------+ Result 表: +----------------------+ | immediate_percentage | +----------------------+ | 50.00 | +----------------------+ 1 号顾客的 1 号订单是首次订单,并且是计划订单。 2 号顾客的 2 号订单是首次订单,并且是即时订单。 3 号顾客的 5 号订单是首次订单,并且是计划订单。 4 号顾客的 7 号订单是首次订单,并且是即时订单。 因此,一半顾客的首次订单是即时的。
解答 SQL架构
CREATE TABLE IF NOT EXISTS insurance (PID INTEGER (11 ), TIV_2015 NUMERIC (15 ,2 ), TIV_2016 NUMERIC (15 ,2 ), LAT NUMERIC (5 ,2 ), LON NUMERIC (5 ,2 ) )Truncate table insuranceinsert into insurance (PID, TIV_2015, TIV_2016, LAT, LON) values ('1' , '10' , '5' , '10' , '10' )insert into insurance (PID, TIV_2015, TIV_2016, LAT, LON) values ('2' , '20' , '20' , '20' , '20' )insert into insurance (PID, TIV_2015, TIV_2016, LAT, LON) values ('3' , '10' , '30' , '20' , '20' )insert into insurance (PID, TIV_2015, TIV_2016, LAT, LON) values ('4' , '10' , '40' , '40' , '40' )
写一个查询语句,将 2016 年 (TIV_2016 ) 所有成功投资的金额加起来,保留 2 位小数。
对于一个投保人,他在 2016 年成功投资的条件是:
他在 2015 年的投保额 (TIV_2015 ) 至少跟一个其他投保人在 2015 年的投保额相同。
他所在的城市必须与其他投保人都不同(也就是说维度和经度不能跟其他任何一个投保人完全相同)。
输入格式: insurance\
| Column Name | Type | |-------------|---------------| | PID | INTEGER(11) | | TIV_2015 | NUMERIC(15,2) | | TIV_2016 | NUMERIC(15,2) | | LAT | NUMERIC(5,2) | | LON | NUMERIC(5,2) |
PID 字段是投保人的投保编号, TIV_2015 是该投保人在2015年的总投保金额, TIV_2016 是该投保人在2016年的投保金额, LAT 是投保人所在城市的维度, LON 是投保人所在城市的经度。
样例输入
| PID | TIV_2015 | TIV_2016 | LAT | LON | |-----|----------|----------|-----|-----| | 1 | 10 | 5 | 10 | 10 | | 2 | 20 | 20 | 20 | 20 | | 3 | 10 | 30 | 20 | 20 | | 4 | 10 | 40 | 40 | 40 |
样例输出
| TIV_2016 | |----------| | 45.00 |
解释
就如最后一个投保人,第一个投保人同时满足两个条件: 1. 他在 2015 年的投保金额 TIV_2015 为 '10' ,与第三个和第四个投保人在 2015 年的投保金额相同。 2. 他所在城市的经纬度是独一无二的。 第二个投保人两个条件都不满足。他在 2015 年的投资 TIV_2015 与其他任何投保人都不相同。 且他所在城市的经纬度与第三个投保人相同。基于同样的原因,第三个投保人投资失败。 所以返回的结果是第一个投保人和最后一个投保人的 TIV_2016 之和,结果是 45 。
解答 SQL架构
Create table If Not Exists Candidate (id int , Name varchar (255 ))Create table If Not Exists Vote (id int , CandidateId int )Truncate table Candidateinsert into Candidate (id , Name ) values ('1' , 'A' )insert into Candidate (id , Name ) values ('2' , 'B' )insert into Candidate (id , Name ) values ('3' , 'C' )insert into Candidate (id , Name ) values ('4' , 'D' )insert into Candidate (id , Name ) values ('5' , 'E' )Truncate table Voteinsert into Vote (id , CandidateId) values ('1' , '2' )insert into Vote (id , CandidateId) values ('2' , '4' )insert into Vote (id , CandidateId) values ('3' , '3' )insert into Vote (id , CandidateId) values ('4' , '2' )insert into Vote (id , CandidateId) values ('5' , '5' )
表: Candidate
+-----+---------+ | id | Name | +-----+---------+ | 1 | A | | 2 | B | | 3 | C | | 4 | D | | 5 | E | +-----+---------+
表: Vote
+-----+--------------+ | id | CandidateId | +-----+--------------+ | 1 | 2 | | 2 | 4 | | 3 | 3 | | 4 | 2 | | 5 | 5 | +-----+--------------+ id 是自动递增的主键, CandidateId 是 Candidate 表中的 id.
请编写 sql 语句来找到当选者的名字,上面的例子将返回当选者 B.
+------+ | Name | +------+ | B | +------+
注意:
你可以假设没有平局 ,换言之,最多 只有一位当选者。
解答 SQL架构
Create table If Not Exists Teams (team_id int , team_name varchar (30 ))Create table If Not Exists Matches (match_id int , host_team int , guest_team int , host_goals int , guest_goals int )Truncate table Teamsinsert into Teams (team_id, team_name) values ('10' , 'Leetcode FC' )insert into Teams (team_id, team_name) values ('20' , 'NewYork FC' )insert into Teams (team_id, team_name) values ('30' , 'Atlanta FC' )insert into Teams (team_id, team_name) values ('40' , 'Chicago FC' )insert into Teams (team_id, team_name) values ('50' , 'Toronto FC' )Truncate table Matchesinsert into Matches (match_id, host_team, guest_team, host_goals, guest_goals) values ('1' , '10' , '20' , '30' , '0' )insert into Matches (match_id, host_team, guest_team, host_goals, guest_goals) values ('2' , '30' , '10' , '2' , '2' )insert into Matches (match_id, host_team, guest_team, host_goals, guest_goals) values ('3' , '10' , '50' , '5' , '1' )insert into Matches (match_id, host_team, guest_team, host_goals, guest_goals) values ('4' , '20' , '30' , '1' , '0' )insert into Matches (match_id, host_team, guest_team, host_goals, guest_goals) values ('5' , '50' , '30' , '1' , '0' )
Table: Teams
+---------------+----------+ | Column Name | Type | +---------------+----------+ | team_id | int | | team_name | varchar | +---------------+----------+ 此表的主键是 team_id,表中的每一行都代表一支独立足球队。
Table: Matches
+---------------+---------+ | Column Name | Type | +---------------+---------+ | match_id | int | | host_team | int | | guest_team | int | | host_goals | int | | guest_goals | int | +---------------+---------+ 此表的主键是 match_id,表中的每一行都代表一场已结束的比赛,比赛的主客队分别由它们自己的 id 表示,他们的进球由 host_goals 和 guest_goals 分别表示。
积分规则如下:
写出一条SQL语句以查询每个队的 team_id ,team_name 和 num_points 。结果根据 num_points 降序排序 ,如果有两队积分相同,那么这两队按 team_id 升序排序 。
查询结果格式如下:
Teams table: +-----------+--------------+ | team_id | team_name | +-----------+--------------+ | 10 | Leetcode FC | | 20 | NewYork FC | | 30 | Atlanta FC | | 40 | Chicago FC | | 50 | Toronto FC | +-----------+--------------+ Matches table: +------------+--------------+---------------+-------------+--------------+ | match_id | host_team | guest_team | host_goals | guest_goals | +------------+--------------+---------------+-------------+--------------+ | 1 | 10 | 20 | 3 | 0 | | 2 | 30 | 10 | 2 | 2 | | 3 | 10 | 50 | 5 | 1 | | 4 | 20 | 30 | 1 | 0 | | 5 | 50 | 30 | 1 | 0 | +------------+--------------+---------------+-------------+--------------+ Result table: +------------+--------------+---------------+ | team_id | team_name | num_points | +------------+--------------+---------------+ | 10 | Leetcode FC | 7 | | 20 | NewYork FC | 3 | | 50 | Toronto FC | 3 | | 30 | Atlanta FC | 1 | | 40 | Chicago FC | 0 | +------------+--------------+---------------+
解答 SQL架构
CREATE TABLE IF NOT EXISTS student (student_id INT ,student_name VARCHAR (45 ), gender VARCHAR (6 ), dept_id INT )CREATE TABLE IF NOT EXISTS department (dept_id INT , dept_name VARCHAR (255 ))Truncate table studentinsert into student (student_id, student_name, gender, dept_id) values ('1' , 'Jack' , 'M' , '1' )insert into student (student_id, student_name, gender, dept_id) values ('2' , 'Jane' , 'F' , '1' )insert into student (student_id, student_name, gender, dept_id) values ('3' , 'Mark' , 'M' , '2' )Truncate table departmentinsert into department (dept_id, dept_name) values ('1' , 'Engineering' )insert into department (dept_id, dept_name) values ('2' , 'Science' )insert into department (dept_id, dept_name) values ('3' , 'Law' )
一所大学有 2 个数据表,分别是 student department
写一个查询语句,查询 department
将你的查询结果按照学生人数降序排列。 如果有两个或两个以上专业有相同的学生数目,将这些部门按照部门名字的字典序从小到大排列。
student\
| Column Name | Type | |--------------|-----------| | student_id | Integer | | student_name | String | | gender | Character | | dept_id | Integer |
其中, student_id 是学生的学号, student_name 是学生的姓名, gender 是学生的性别, dept_id 是学生所属专业的专业编号。
department\
| Column Name | Type | |-------------|---------| | dept_id | Integer | | dept_name | String |
dept_id 是专业编号, dept_name 是专业名字。
这里是一个示例输入:student\
| student_id | student_name | gender | dept_id | |------------|--------------|--------|---------| | 1 | Jack | M | 1 | | 2 | Jane | F | 1 | | 3 | Mark | M | 2 |
department\
| dept_id | dept_name | |---------|-------------| | 1 | Engineering | | 2 | Science | | 3 | Law |
示例输出为:
| dept_name | student_number | |-------------|----------------| | Engineering | 2 | | Science | 1 | | Law | 0 |
SQL架构
Create table If Not Exists Logs (Id int , Num int )Truncate table Logs insert into Logs (Id , Num ) values ('1' , '1' )insert into Logs (Id , Num ) values ('2' , '1' )insert into Logs (Id , Num ) values ('3' , '1' )insert into Logs (Id , Num ) values ('4' , '2' )insert into Logs (Id , Num ) values ('5' , '1' )insert into Logs (Id , Num ) values ('6' , '2' )insert into Logs (Id , Num ) values ('7' , '2' )
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
+----+-----+ | Id | Num | +----+-----+ | 1 | 1 | | 2 | 1 | | 3 | 1 | | 4 | 2 | | 5 | 1 | | 6 | 2 | | 7 | 2 | +----+-----+
例如,给定上面的 Logs 表, 1 是唯一连续出现至少三次的数字。
+-----------------+ | ConsecutiveNums | +-----------------+ | 1 | +-----------------+
SQL架构
create table if not exists Transactions (id int , country varchar (4 ), state enum('approved' , 'declined' ), amount int , trans_date date )create table if not exists Chargebacks (trans_id int , trans_date date )Truncate table Transactionsinsert into Transactions (id , country, state, amount, trans_date) values ('101' , 'US' , 'approved' , '1000' , '2019-05-18' )insert into Transactions (id , country, state, amount, trans_date) values ('102' , 'US' , 'declined' , '2000' , '2019-05-19' )insert into Transactions (id , country, state, amount, trans_date) values ('103' , 'US' , 'approved' , '3000' , '2019-06-10' )insert into Transactions (id , country, state, amount, trans_date) values ('104' , 'US' , 'declined' , '4000' , '2019-06-13' )insert into Transactions (id , country, state, amount, trans_date) values ('105' , 'US' , 'approved' , '5000' , '2019-06-15' )Truncate table Chargebacksinsert into Chargebacks (trans_id, trans_date) values ('102' , '2019-05-29' )insert into Chargebacks (trans_id, trans_date) values ('101' , '2019-06-30' )insert into Chargebacks (trans_id, trans_date) values ('105' , '2019-09-18' )
Transactions 记录表
+----------------+---------+ | Column Name | Type | +----------------+---------+ | id | int | | country | varchar | | state | enum | | amount | int | | trans_date | date | +----------------+---------+ id 是这个表的主键。 该表包含有关传入事务的信息。 状态列是类型为 [approved(已批准)、declined(已拒绝)] 的枚举。
Chargebacks 表
+----------------+---------+ | Column Name | Type | +----------------+---------+ | trans_id | int | | charge_date | date | +----------------+---------+ 退单包含有关放置在事务表中的某些事务的传入退单的基本信息。 trans_id 是 transactions 表的 id 列的外键。 每项退单都对应于之前进行的交易,即使未经批准。
编写一个 SQL 查询,以查找每个月和每个国家/地区的已批准交易的数量及其总金额、退单的数量及其总金额。
注意:在您的查询中,给定月份和国家,忽略所有为零的行。
查询结果格式如下所示:
Transactions 表: +------+---------+----------+--------+------------+ | id | country | state | amount | trans_date | +------+---------+----------+--------+------------+ | 101 | US | approved | 1000 | 2019-05-18 | | 102 | US | declined | 2000 | 2019-05-19 | | 103 | US | approved | 3000 | 2019-06-10 | | 104 | US | approved | 4000 | 2019-06-13 | | 105 | US | approved | 5000 | 2019-06-15 | +------+---------+----------+--------+------------+ Chargebacks 表: +------------+------------+ | trans_id | trans_date | +------------+------------+ | 102 | 2019-05-29 | | 101 | 2019-06-30 | | 105 | 2019-09-18 | +------------+------------+ Result 表: +----------+---------+----------------+-----------------+-------------------+--------------------+ | month | country | approved_count | approved_amount | chargeback_count | chargeback_amount | +----------+---------+----------------+-----------------+-------------------+--------------------+ | 2019-05 | US | 1 | 1000 | 1 | 2000 | | 2019-06 | US | 3 | 12000 | 1 | 1000 | | 2019-09 | US | 0 | 0 | 1 | 5000 | +----------+---------+----------------+-----------------+-------------------+--------------------+
SQL架构
Create table Sales (sale_id int , product_id int , year int , quantity int , price int )Create table Product (product_id int , product_name varchar (10 ))Truncate table Salesinsert into Sales (sale_id, product_id, year , quantity, price) values ('1' , '100' , '2008' , '10' , '5000' )insert into Sales (sale_id, product_id, year , quantity, price) values ('2' , '100' , '2009' , '12' , '5000' )insert into Sales (sale_id, product_id, year , quantity, price) values ('7' , '200' , '2011' , '15' , '9000' )Truncate table Productinsert into Product (product_id, product_name) values ('100' , 'Nokia' )insert into Product (product_id, product_name) values ('200' , 'Apple' )insert into Product (product_id, product_name) values ('300' , 'Samsung' )
销售表 Sales:
+-------------+-------+ | Column Name | Type | +-------------+-------+ | sale_id | int | | product_id | int | | year | int | | quantity | int | | price | int | +-------------+-------+ sale_id 是此表的主键。 产品 ID 是产品表的外键。 请注意,价格是按每单位计的。
产品表 Product:
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | +--------------+---------+ 产品 ID 是此表的主键。
编写一个 SQL 查询,选出每个销售产品的 第一年 的 产品 id 、年份 、数量 和 价格 。
查询结果格式如下:
Sales table: +---------+------------+------+----------+-------+ | sale_id | product_id | year | quantity | price | +---------+------------+------+----------+-------+ | 1 | 100 | 2008 | 10 | 5000 | | 2 | 100 | 2009 | 12 | 5000 | | 7 | 200 | 2011 | 15 | 9000 | +---------+------------+------+----------+-------+ Product table: +------------+--------------+ | product_id | product_name | +------------+--------------+ | 100 | Nokia | | 200 | Apple | | 300 | Samsung | +------------+--------------+ Result table: +------------+------------+----------+-------+ | product_id | first_year | quantity | price | +------------+------------+----------+-------+ | 100 | 2008 | 10 | 5000 | | 200 | 2011 | 15 | 9000 | +------------+------------+----------+-------+
SQL架构
Create table If Not Exists survey_log (id int , action varchar (255 ), question_id int , answer_id int , q_num int , timestamp int )Truncate table survey_loginsert into survey_log (id , action , question_id, answer_id, q_num, timestamp ) values ('5' , 'show' , '285' , 'None' , '1' , '123' )insert into survey_log (id , action , question_id, answer_id, q_num, timestamp ) values ('5' , 'answer' , '285' , '124124' , '1' , '124' )insert into survey_log (id , action , question_id, answer_id, q_num, timestamp ) values ('5' , 'show' , '369' , 'None' , '2' , '125' )insert into survey_log (id , action , question_id, answer_id, q_num, timestamp ) values ('5' , 'skip' , '369' , 'None' , '2' , '126' )
从 survey_log 表中获得回答率最高的问题,survey_log 表包含这些列:uid , action , question_id , answer_id , q_num , timestamp 。
uid 表示用户 id;action 有以下几种值:”show”,”answer”,”skip”;当 action 值为 “answer” 时 answer_id 非空,而 action 值为 “show” 或者 “skip” 时 answer_id 为空;q_num 表示当前会话中问题的编号。
请编写SQL查询来找到具有最高回答率的问题。
示例:
输入: +------+-----------+--------------+------------+-----------+------------+ | uid | action | question_id | answer_id | q_num | timestamp | +------+-----------+--------------+------------+-----------+------------+ | 5 | show | 285 | null | 1 | 123 | | 5 | answer | 285 | 124124 | 1 | 124 | | 5 | show | 369 | null | 2 | 125 | | 5 | skip | 369 | null | 2 | 126 | +------+-----------+--------------+------------+-----------+------------+ 输出: +-------------+ | survey_log | +-------------+ | 285 | +-------------+ 解释: 问题285的回答率为 1/1,而问题369回答率为 0/1,因此输出285。
注意: 回答率最高的含义是:同一问题编号中回答数占显示数的比例。
SQL架构
Create table If Not Exists Movies (movie_id int , title varchar (30 ))Create table If Not Exists Users (user_id int , name varchar (30 ))Create table If Not Exists Movie_Rating (movie_id int , user_id int , rating int , created_at date )Truncate table Moviesinsert into Movies (movie_id, title) values ('1' , 'Avengers' )insert into Movies (movie_id, title) values ('2' , 'Frozen 2' )insert into Movies (movie_id, title) values ('3' , 'Joker' )Truncate table Users insert into Users (user_id, name ) values ('1' , 'Daniel' )insert into Users (user_id, name ) values ('2' , 'Monica' )insert into Users (user_id, name ) values ('3' , 'Maria' )insert into Users (user_id, name ) values ('4' , 'James' )Truncate table Movie_Ratinginsert into Movie_Rating (movie_id, user_id, rating, created_at) values ('1' , '1' , '3' , '2020-01-12' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('1' , '2' , '4' , '2020-02-11' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('1' , '3' , '2' , '2020-02-12' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('1' , '4' , '1' , '2020-01-01' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('2' , '1' , '5' , '2020-02-17' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('2' , '2' , '2' , '2020-02-01' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('2' , '3' , '2' , '2020-03-01' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('3' , '1' , '3' , '2020-02-22' )insert into Movie_Rating (movie_id, user_id, rating, created_at) values ('3' , '2' , '4' , '2020-02-25' )
表:Movies
+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | title | varchar | +---------------+---------+ movie_id 是这个表的主键。 title 是电影的名字。
表:Users
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | name | varchar | +---------------+---------+ user_id 是表的主键。
表:Movie_Rating
+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | user_id | int | | rating | int | | created_at | date | +---------------+---------+ (movie_id, user_id) 是这个表的主键。 这个表包含用户在其评论中对电影的评分 rating 。 created_at 是用户的点评日期。
请你编写一组 SQL 查询:
查询分两行返回,查询结果格式如下例所示:
Movies 表: +-------------+--------------+ | movie_id | title | +-------------+--------------+ | 1 | Avengers | | 2 | Frozen 2 | | 3 | Joker | +-------------+--------------+ Users 表: +-------------+--------------+ | user_id | name | +-------------+--------------+ | 1 | Daniel | | 2 | Monica | | 3 | Maria | | 4 | James | +-------------+--------------+ Movie_Rating 表: +-------------+--------------+--------------+-------------+ | movie_id | user_id | rating | created_at | +-------------+--------------+--------------+-------------+ | 1 | 1 | 3 | 2020-01-12 | | 1 | 2 | 4 | 2020-02-11 | | 1 | 3 | 2 | 2020-02-12 | | 1 | 4 | 1 | 2020-01-01 | | 2 | 1 | 5 | 2020-02-17 | | 2 | 2 | 2 | 2020-02-01 | | 2 | 3 | 2 | 2020-03-01 | | 3 | 1 | 3 | 2020-02-22 | | 3 | 2 | 4 | 2020-02-25 | +-------------+--------------+--------------+-------------+ Result 表: +--------------+ | results | +--------------+ | Daniel | | Frozen 2 | +--------------+ Daniel 和 Monica 都点评了 3 部电影("Avengers", "Frozen 2" 和 "Joker") 但是 Daniel 字典序比较小。 Frozen 2 和 Joker 在 2 月的评分都是 3.5,但是 Frozen 2 的字典序比较小。
SQL架构
Create table If Not Exists Activity (player_id int , device_id int , event_date date , games_played int )Truncate table Activityinsert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-03-01' , '5' )insert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-03-02' , '6' )insert into Activity (player_id, device_id, event_date, games_played) values ('2' , '3' , '2017-06-25' , '1' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '1' , '2016-03-02' , '0' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '4' , '2018-07-03' , '5' )
Table: Activity
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ (player_id,event_date)是此表的主键。 这张表显示了某些游戏的玩家的活动情况。 每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0)。
编写一个 SQL 查询,报告在首次登录的第二天再次登录的玩家的分数,四舍五入到小数点后两位。换句话说,您需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
查询结果格式如下所示:
Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-03-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ Result table: +-----------+ | fraction | +-----------+ | 0.33 | +-----------+ 只有 ID 为 1 的玩家在第一天登录后才重新登录,所以答案是 1/3 = 0.33
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+ | Id | Salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
+------------------------+ | getNthHighestSalary(2) | +------------------------+ | 200 | +------------------------+
SQL架构
Create table If Not Exists Employee (Id int , Name varchar (255 ), Salary int , DepartmentId int )Create table If Not Exists Department (Id int , Name varchar (255 ))Truncate table Employeeinsert into Employee (Id , Name , Salary, DepartmentId) values ('1' , 'Joe' , '70000' , '1' )insert into Employee (Id , Name , Salary, DepartmentId) values ('2' , 'Jim' , '90000' , '1' )insert into Employee (Id , Name , Salary, DepartmentId) values ('3' , 'Henry' , '80000' , '2' )insert into Employee (Id , Name , Salary, DepartmentId) values ('4' , 'Sam' , '60000' , '2' )insert into Employee (Id , Name , Salary, DepartmentId) values ('5' , 'Max' , '90000' , '1' )Truncate table Departmentinsert into Department (Id , Name ) values ('1' , 'IT' )insert into Department (Id , Name ) values ('2' , 'Sales' )
Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+ | Id | Name | Salary | DepartmentId | +----+-------+--------+--------------+ | 1 | Joe | 70000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | +----+-------+--------+--------------+
Department 表包含公司所有部门的信息。
+----+----------+ | Id | Name | +----+----------+ | 1 | IT | | 2 | Sales | +----+----------+
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
+------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | Sales | Henry | 80000 | +------------+----------+--------+
SQL架构
Create table If Not Exists Books (book_id int , name varchar (50 ), available_from date )Create table If Not Exists Orders (order_id int , book_id int , quantity int , dispatch_date date )Truncate table Booksinsert into Books (book_id, name , available_from) values ('1' , 'Kalila And Demna' , '2010-01-01' )insert into Books (book_id, name , available_from) values ('2' , '28 Letters' , '2012-05-12' )insert into Books (book_id, name , available_from) values ('3' , 'The Hobbit' , '2019-06-10' )insert into Books (book_id, name , available_from) values ('4' , '13 Reasons Why' , '2019-06-01' )insert into Books (book_id, name , available_from) values ('5' , 'The Hunger Games' , '2008-09-21' )Truncate table Ordersinsert into Orders (order_id, book_id, quantity, dispatch_date) values ('1' , '1' , '2' , '2018-07-26' )insert into Orders (order_id, book_id, quantity, dispatch_date) values ('2' , '1' , '1' , '2018-11-05' )insert into Orders (order_id, book_id, quantity, dispatch_date) values ('3' , '3' , '8' , '2019-06-11' )insert into Orders (order_id, book_id, quantity, dispatch_date) values ('4' , '4' , '6' , '2019-06-05' )insert into Orders (order_id, book_id, quantity, dispatch_date) values ('5' , '4' , '5' , '2019-06-20' )insert into Orders (order_id, book_id, quantity, dispatch_date) values ('6' , '5' , '9' , '2009-02-02' )insert into Orders (order_id, book_id, quantity, dispatch_date) values ('7' , '5' , '8' , '2010-04-13' )
书籍表 Books:
+----------------+---------+ | Column Name | Type | +----------------+---------+ | book_id | int | | name | varchar | | available_from | date | +----------------+---------+ book_id 是这个表的主键。
订单表 Orders:
+----------------+---------+ | Column Name | Type | +----------------+---------+ | order_id | int | | book_id | int | | quantity | int | | dispatch_date | date | +----------------+---------+ order_id 是这个表的主键。 book_id 是 Books 表的外键。
你需要写一段 SQL 命令,筛选出过去一年中订单总量 少于10本 的 书籍 。
注意:不考虑 上架(available from)距今 不满一个月 的书籍。并且 假设今天是 2019-06-23 。
下面是样例输出结果:
Books 表: +---------+--------------------+----------------+ | book_id | name | available_from | +---------+--------------------+----------------+ | 1 | "Kalila And Demna" | 2010-01-01 | | 2 | "28 Letters" | 2012-05-12 | | 3 | "The Hobbit" | 2019-06-10 | | 4 | "13 Reasons Why" | 2019-06-01 | | 5 | "The Hunger Games" | 2008-09-21 | +---------+--------------------+----------------+ Orders 表: +----------+---------+----------+---------------+ | order_id | book_id | quantity | dispatch_date | +----------+---------+----------+---------------+ | 1 | 1 | 2 | 2018-07-26 | | 2 | 1 | 1 | 2018-11-05 | | 3 | 3 | 8 | 2019-06-11 | | 4 | 4 | 6 | 2019-06-05 | | 5 | 4 | 5 | 2019-06-20 | | 6 | 5 | 9 | 2009-02-02 | | 7 | 5 | 8 | 2010-04-13 | +----------+---------+----------+---------------+ Result 表: +-----------+--------------------+ | book_id | name | +-----------+--------------------+ | 1 | "Kalila And Demna" | | 2 | "28 Letters" | | 5 | "The Hunger Games" | +-----------+--------------------+
SQL架构
Create table If Not Exists Traffic (user_id int , activity ENUM('login' , 'logout' , 'jobs' , 'groups' , 'homepage' ), activity_date date )Truncate table Trafficinsert into Traffic (user_id, activity, activity_date) values ('1' , 'login' , '2019-05-01' )insert into Traffic (user_id, activity, activity_date) values ('1' , 'homepage' , '2019-05-01' )insert into Traffic (user_id, activity, activity_date) values ('1' , 'logout' , '2019-05-01' )insert into Traffic (user_id, activity, activity_date) values ('2' , 'login' , '2019-06-21' )insert into Traffic (user_id, activity, activity_date) values ('2' , 'logout' , '2019-06-21' )insert into Traffic (user_id, activity, activity_date) values ('3' , 'login' , '2019-01-01' )insert into Traffic (user_id, activity, activity_date) values ('3' , 'jobs' , '2019-01-01' )insert into Traffic (user_id, activity, activity_date) values ('3' , 'logout' , '2019-01-01' )insert into Traffic (user_id, activity, activity_date) values ('4' , 'login' , '2019-06-21' )insert into Traffic (user_id, activity, activity_date) values ('4' , 'groups' , '2019-06-21' )insert into Traffic (user_id, activity, activity_date) values ('4' , 'logout' , '2019-06-21' )insert into Traffic (user_id, activity, activity_date) values ('5' , 'login' , '2019-03-01' )insert into Traffic (user_id, activity, activity_date) values ('5' , 'logout' , '2019-03-01' )insert into Traffic (user_id, activity, activity_date) values ('5' , 'login' , '2019-06-21' )insert into Traffic (user_id, activity, activity_date) values ('5' , 'logout' , '2019-06-21' )
Traffic 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | activity | enum | | activity_date | date | +---------------+---------+ 该表没有主键,它可能有重复的行。 activity 列是 ENUM 类型,可能取 ('login', 'logout', 'jobs', 'groups', 'homepage') 几个值之一。
编写一个 SQL 查询,以查询从今天起最多 90 天内,每个日期该日期首次登录的用户数。假设今天是 2019-06-30 .
查询结果格式如下例所示:
Traffic 表: +---------+----------+---------------+ | user_id | activity | activity_date | +---------+----------+---------------+ | 1 | login | 2019-05-01 | | 1 | homepage | 2019-05-01 | | 1 | logout | 2019-05-01 | | 2 | login | 2019-06-21 | | 2 | logout | 2019-06-21 | | 3 | login | 2019-01-01 | | 3 | jobs | 2019-01-01 | | 3 | logout | 2019-01-01 | | 4 | login | 2019-06-21 | | 4 | groups | 2019-06-21 | | 4 | logout | 2019-06-21 | | 5 | login | 2019-03-01 | | 5 | logout | 2019-03-01 | | 5 | login | 2019-06-21 | | 5 | logout | 2019-06-21 | +---------+----------+---------------+ Result 表: +------------+-------------+ | login_date | user_count | +------------+-------------+ | 2019-05-01 | 1 | | 2019-06-21 | 2 | +------------+-------------+ 请注意,我们只关心用户数非零的日期. ID 为 5 的用户第一次登陆于 2019-03-01,因此他不算在 2019-06-21 的的统计内。
SQL架构
Create table If Not Exists Actions (user_id int , post_id int , action_date date , action ENUM('view' , 'like' , 'reaction' , 'comment' , 'report' , 'share' ), extra varchar (10 ))create table if not exists Removals (post_id int , remove_date date )Truncate table Actionsinsert into Actions (user_id, post_id, action_date, action , extra) values ('1' , '1' , '2019-07-01' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('1' , '1' , '2019-07-01' , 'like' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('1' , '1' , '2019-07-01' , 'share' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('2' , '2' , '2019-07-04' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('2' , '2' , '2019-07-04' , 'report' , 'spam' )insert into Actions (user_id, post_id, action_date, action , extra) values ('3' , '4' , '2019-07-04' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('3' , '4' , '2019-07-04' , 'report' , 'spam' )insert into Actions (user_id, post_id, action_date, action , extra) values ('4' , '3' , '2019-07-02' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('4' , '3' , '2019-07-02' , 'report' , 'spam' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '2' , '2019-07-03' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '2' , '2019-07-03' , 'report' , 'racism' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '5' , '2019-07-03' , 'view' , 'None' )insert into Actions (user_id, post_id, action_date, action , extra) values ('5' , '5' , '2019-07-03' , 'report' , 'racism' )Truncate table Removalsinsert into Removals (post_id, remove_date) values ('2' , '2019-07-20' )insert into Removals (post_id, remove_date) values ('3' , '2019-07-18' )
动作表: Actions
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | post_id | int | | action_date | date | | action | enum | | extra | varchar | +---------------+---------+ 这张表没有主键,并有可能存在重复的行。 action 列的类型是 ENUM,可能的值为 ('view', 'like', 'reaction', 'comment', 'report', 'share')。 extra 列拥有一些可选信息,例如:报告理由(a reason for report)或反应类型(a type of reaction)等。
移除表: Removals
+---------------+---------+ | Column Name | Type | +---------------+---------+ | post_id | int | | remove_date | date | +---------------+---------+ 这张表的主键是 post_id。 这张表的每一行表示一个被移除的帖子,原因可能是由于被举报或被管理员审查。
编写一段 SQL 来查找:在被报告为垃圾广告的帖子中,被移除的帖子的每日平均占比,四舍五入到小数点后 2 位 。查询结果的格式如下:
Actions table: +---------+---------+-------------+--------+--------+ | user_id | post_id | action_date | action | extra | +---------+---------+-------------+--------+--------+ | 1 | 1 | 2019-07-01 | view | null | | 1 | 1 | 2019-07-01 | like | null | | 1 | 1 | 2019-07-01 | share | null | | 2 | 2 | 2019-07-04 | view | null | | 2 | 2 | 2019-07-04 | report | spam | | 3 | 4 | 2019-07-04 | view | null | | 3 | 4 | 2019-07-04 | report | spam | | 4 | 3 | 2019-07-02 | view | null | | 4 | 3 | 2019-07-02 | report | spam | | 5 | 2 | 2019-07-03 | view | null | | 5 | 2 | 2019-07-03 | report | racism | | 5 | 5 | 2019-07-03 | view | null | | 5 | 5 | 2019-07-03 | report | racism | +---------+---------+-------------+--------+--------+ Removals table: +---------+-------------+ | post_id | remove_date | +---------+-------------+ | 2 | 2019-07-20 | | 3 | 2019-07-18 | +---------+-------------+ Result table: +-----------------------+ | average_daily_percent | +-----------------------+ | 75.00 | +-----------------------+ 2019-07-04 的垃圾广告移除率是 50%,因为有两张帖子被报告为垃圾广告,但只有一个得到移除。 2019-07-02 的垃圾广告移除率是 100%,因为有一张帖子被举报为垃圾广告并得到移除。 其余几天没有收到垃圾广告的举报,因此平均值为:(50 + 100) / 2 = 75% 注意,输出仅需要一个平均值即可,我们并不关注移除操作的日期。
SQL架构
Create table If Not Exists follow (followee varchar (255 ), follower varchar (255 ))Truncate table followinsert into follow (followee, follower) values ('A' , 'B' )insert into follow (followee, follower) values ('B' , 'C' )insert into follow (followee, follower) values ('B' , 'D' )insert into follow (followee, follower) values ('D' , 'E' )
在 facebook 中,表 follow 会有 2 个字段: followee , follower ,分别表示被关注者和关注者。
请写一个 sql 查询语句,对每一个关注者,查询他的关注者数目。
比方说:
+-------------+------------+ | followee | follower | +-------------+------------+ | A | B | | B | C | | B | D | | D | E | +-------------+------------+
应该输出:
+-------------+------------+ | follower | num | +-------------+------------+ | B | 2 | | D | 1 | +-------------+------------+
解释:
B 和 D 都在在 follower 字段中出现,作为被关注者,B 被 C 和 D 关注,D 被 E 关注。A 不在 follower 字段内,所以A不在输出列表中。
注意:
困难 SQL架构
Create table If Not Exists Product (product_id int , product_name varchar (30 ))Create table If Not Exists Sales (product_id varchar (30 ), period_start date , period_end date , average_daily_sales int )Truncate table Productinsert into Product (product_id, product_name) values ('1' , 'LC Phone ' )insert into Product (product_id, product_name) values ('2' , 'LC T-Shirt' )insert into Product (product_id, product_name) values ('3' , 'LC Keychain' )Truncate table Salesinsert into Sales (product_id, period_start, period_end, average_daily_sales) values ('1' , '2019-01-25' , '2019-02-28' , '100' )insert into Sales (product_id, period_start, period_end, average_daily_sales) values ('2' , '2018-12-01' , '2020-01-01' , '10' )insert into Sales (product_id, period_start, period_end, average_daily_sales) values ('3' , '2019-12-01' , '2020-01-31' , '1' )
Product 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | product_name | varchar | +---------------+---------+ product_id 是这张表的主键。 product_name 是产品的名称。
Sales 表:
+---------------------+---------+ | Column Name | Type | +---------------------+---------+ | product_id | int | | period_start | varchar | | period_end | date | | average_daily_sales | int | +---------------------+---------+ product_id 是这张表的主键。 period_start 和 period_end 是该产品销售期的起始日期和结束日期,且这两个日期包含在销售期内。 average_daily_sales 列存储销售期内该产品的日平均销售额。
编写一段SQL查询每个产品每年的总销售额,并包含 product_id, product_name 以及 report_year 等信息。
销售年份的日期介于 2018 年到 2020 年之间。你返回的结果需要按 product_id 和 report_year 排序 。
查询结果格式如下例所示:
Product table: +------------+--------------+ | product_id | product_name | +------------+--------------+ | 1 | LC Phone | | 2 | LC T-Shirt | | 3 | LC Keychain | +------------+--------------+ Sales table: +------------+--------------+-------------+---------------------+ | product_id | period_start | period_end | average_daily_sales | +------------+--------------+-------------+---------------------+ | 1 | 2019-01-25 | 2019-02-28 | 100 | | 2 | 2018-12-01 | 2020-01-01 | 10 | | 3 | 2019-12-01 | 2020-01-31 | 1 | +------------+--------------+-------------+---------------------+ Result table: +------------+--------------+-------------+--------------+ | product_id | product_name | report_year | total_amount | +------------+--------------+-------------+--------------+ | 1 | LC Phone | 2019 | 3500 | | 2 | LC T-Shirt | 2018 | 310 | | 2 | LC T-Shirt | 2019 | 3650 | | 2 | LC T-Shirt | 2020 | 10 | | 3 | LC Keychain | 2019 | 31 | | 3 | LC Keychain | 2020 | 31 | +------------+--------------+-------------+--------------+ LC Phone 在 2019-01-25 至 2019-02-28 期间销售,该产品销售时间总计35天。销售总额 35*100 = 3500。 LC T-shirt 在 2018-12-01 至 2020-01-01 期间销售,该产品在2018年、2019年、2020年的销售时间分别是31天、365天、1天,2018年、2019年、2020年的销售总额分别是31*10=310、365*10=3650、1*10=10。 LC Keychain 在 2019-12-01 至 2020-01-31 期间销售,该产品在2019年、2020年的销售时间分别是:31天、31天,2019年、2020年的销售总额分别是31*1=31、31*1=31。
解答 SQL架构
Create table If Not Exists Failed (fail_date date )Create table If Not Exists Succeeded (success_date date )Truncate table Failed insert into Failed (fail_date) values ('2018-12-28' )insert into Failed (fail_date) values ('2018-12-29' )insert into Failed (fail_date) values ('2019-01-04' )insert into Failed (fail_date) values ('2019-01-05' )Truncate table Succeededinsert into Succeeded (success_date) values ('2018-12-30' )insert into Succeeded (success_date) values ('2018-12-31' )insert into Succeeded (success_date) values ('2019-01-01' )insert into Succeeded (success_date) values ('2019-01-02' )insert into Succeeded (success_date) values ('2019-01-03' )insert into Succeeded (success_date) values ('2019-01-06' )
Table: Failed
+--------------+---------+ | Column Name | Type | +--------------+---------+ | fail_date | date | +--------------+---------+ 该表主键为 fail_date。 该表包含失败任务的天数.
Table: Succeeded
+--------------+---------+ | Column Name | Type | +--------------+---------+ | success_date | date | +--------------+---------+ 该表主键为 success_date。 该表包含成功任务的天数.
系统 每天 运行一个任务。每个任务都独立于先前的任务。任务的状态可以是失败或是成功。
编写一个 SQL 查询 2019-01-01 到 2019-12-31 期间任务连续同状态 period_state 的起止日期(start_date 和 end_date)。即如果任务失败了,就是失败状态的起止日期,如果任务成功了,就是成功状态的起止日期。
最后结果按照起始日期 start_date 排序
查询结果样例如下所示:
Failed table: +-------------------+ | fail_date | +-------------------+ | 2018-12-28 | | 2018-12-29 | | 2019-01-04 | | 2019-01-05 | +-------------------+ Succeeded table: +-------------------+ | success_date | +-------------------+ | 2018-12-30 | | 2018-12-31 | | 2019-01-01 | | 2019-01-02 | | 2019-01-03 | | 2019-01-06 | +-------------------+ Result table: +--------------+--------------+--------------+ | period_state | start_date | end_date | +--------------+--------------+--------------+ | succeeded | 2019-01-01 | 2019-01-03 | | failed | 2019-01-04 | 2019-01-05 | | succeeded | 2019-01-06 | 2019-01-06 | +--------------+--------------+--------------+ 结果忽略了 2018 年的记录,因为我们只关心从 2019-01-01 到 2019-12-31 的记录 从 2019-01-01 到 2019-01-03 所有任务成功,系统状态为 "succeeded"。 从 2019-01-04 到 2019-01-05 所有任务失败,系统状态为 "failed"。 从 2019-01-06 到 2019-01-06 所有任务成功,系统状态为 "succeeded"。
解答 SQL架构
Create table If Not Exists UserActivity (username varchar (30 ), activity varchar (30 ), startDate date , endDate date )Truncate table UserActivityinsert into UserActivity (username, activity, startDate, endDate) values ('Alice' , 'Travel' , '2020-02-12' , '2020-02-20' )insert into UserActivity (username, activity, startDate, endDate) values ('Alice' , 'Dancing' , '2020-02-21' , '2020-02-23' )insert into UserActivity (username, activity, startDate, endDate) values ('Alice' , 'Travel' , '2020-02-24' , '2020-02-28' )insert into UserActivity (username, activity, startDate, endDate) values ('Bob' , 'Travel' , '2020-02-11' , '2020-02-18' )
表: UserActivity
+---------------+---------+ | Column Name | Type | +---------------+---------+ | username | varchar | | activity | varchar | | startDate | Date | | endDate | Date | +---------------+---------+ 该表不包含主键 该表包含每个用户在一段时间内进行的活动的信息 名为 username 的用户在 startDate 到 endDate 日内有一次活动
写一条SQL查询展示每一位用户 最近第二次 的活动
如果用户仅有一次活动,返回该活动
一个用户不能同时进行超过一项活动,以 任意 顺序返回结果
下面是查询结果格式的例子:
UserActivity 表: +------------+--------------+-------------+-------------+ | username | activity | startDate | endDate | +------------+--------------+-------------+-------------+ | Alice | Travel | 2020-02-12 | 2020-02-20 | | Alice | Dancing | 2020-02-21 | 2020-02-23 | | Alice | Travel | 2020-02-24 | 2020-02-28 | | Bob | Travel | 2020-02-11 | 2020-02-18 | +------------+--------------+-------------+-------------+ Result 表: +------------+--------------+-------------+-------------+ | username | activity | startDate | endDate | +------------+--------------+-------------+-------------+ | Alice | Dancing | 2020-02-21 | 2020-02-23 | | Bob | Travel | 2020-02-11 | 2020-02-18 | +------------+--------------+-------------+-------------+ Alice 最近第二次的活动是从 2020-02-24 到 2020-02-28 的旅行, 在此之前的 2020-02-21 到 2020-02-23 她进行了舞蹈 Bob 只有一条记录,我们就取这条记录
解答 SQL架构
Create table If Not Exists student (name varchar (50 ), continent varchar (7 ))Truncate table studentinsert into student (name , continent) values ('Jane' , 'America' )insert into student (name , continent) values ('Pascal' , 'Europe' )insert into student (name , continent) values ('Xi' , 'Asia' )insert into student (name , continent) values ('Jack' , 'America' )
一所美国大学有来自亚洲、欧洲和美洲的学生,他们的地理信息存放在如下 student 表中。
| name | continent | |--------|-----------| | Jack | America | | Pascal | Europe | | Xi | Asia | | Jane | America |
写一个查询语句实现对大洲(continent)列的 透视表 操作,使得每个学生按照姓名的字母顺序依次排列在对应的大洲下面。输出的标题应依次为美洲(America)、亚洲(Asia)和欧洲(Europe)。数据保证来自美洲的学生不少于来自亚洲或者欧洲的学生。
对于样例输入,它的对应输出是:
| America | Asia | Europe | |---------|------|--------| | Jack | Xi | Pascal | | Jane | | |
进阶: 如果不能确定哪个大洲的学生数最多,你可以写出一个查询去生成上述学生报告吗?
解答 SQL架构
Create table If Not Exists Employee (Id int , Company varchar (255 ), Salary int )Truncate table Employeeinsert into Employee (Id , Company, Salary) values ('1' , 'A' , '2341' )insert into Employee (Id , Company, Salary) values ('2' , 'A' , '341' )insert into Employee (Id , Company, Salary) values ('3' , 'A' , '15' )insert into Employee (Id , Company, Salary) values ('4' , 'A' , '15314' )insert into Employee (Id , Company, Salary) values ('5' , 'A' , '451' )insert into Employee (Id , Company, Salary) values ('6' , 'A' , '513' )insert into Employee (Id , Company, Salary) values ('7' , 'B' , '15' )insert into Employee (Id , Company, Salary) values ('8' , 'B' , '13' )insert into Employee (Id , Company, Salary) values ('9' , 'B' , '1154' )insert into Employee (Id , Company, Salary) values ('10' , 'B' , '1345' )insert into Employee (Id , Company, Salary) values ('11' , 'B' , '1221' )insert into Employee (Id , Company, Salary) values ('12' , 'B' , '234' )insert into Employee (Id , Company, Salary) values ('13' , 'C' , '2345' )insert into Employee (Id , Company, Salary) values ('14' , 'C' , '2645' )insert into Employee (Id , Company, Salary) values ('15' , 'C' , '2645' )insert into Employee (Id , Company, Salary) values ('16' , 'C' , '2652' )insert into Employee (Id , Company, Salary) values ('17' , 'C' , '65' )
Employee 表包含所有员工。Employee 表有三列:员工Id,公司名和薪水。
+-----+------------+--------+ |Id | Company | Salary | +-----+------------+--------+ |1 | A | 2341 | |2 | A | 341 | |3 | A | 15 | |4 | A | 15314 | |5 | A | 451 | |6 | A | 513 | |7 | B | 15 | |8 | B | 13 | |9 | B | 1154 | |10 | B | 1345 | |11 | B | 1221 | |12 | B | 234 | |13 | C | 2345 | |14 | C | 2645 | |15 | C | 2645 | |16 | C | 2652 | |17 | C | 65 | +-----+------------+--------+
请编写SQL查询来查找每个公司的薪水中位数。挑战点:你是否可以在不使用任何内置的SQL函数的情况下解决此问题。
+-----+------------+--------+ |Id | Company | Salary | +-----+------------+--------+ |5 | A | 451 | |6 | A | 513 | |12 | B | 234 | |9 | B | 1154 | |14 | C | 2645 | +-----+------------+--------+
解答 SQL架构
Create table If Not Exists Spending (user_id int , spend_date date , platform ENUM('desktop' , 'mobile' ), amount int )Truncate table Spendinginsert into Spending (user_id, spend_date, platform, amount) values ('1' , '2019-07-01' , 'mobile' , '100' )insert into Spending (user_id, spend_date, platform, amount) values ('1' , '2019-07-01' , 'desktop' , '100' )insert into Spending (user_id, spend_date, platform, amount) values ('2' , '2019-07-01' , 'mobile' , '100' )insert into Spending (user_id, spend_date, platform, amount) values ('2' , '2019-07-02' , 'mobile' , '100' )insert into Spending (user_id, spend_date, platform, amount) values ('3' , '2019-07-01' , 'desktop' , '100' )insert into Spending (user_id, spend_date, platform, amount) values ('3' , '2019-07-02' , 'desktop' , '100' )
支出表: Spending
+-------------+---------+ | Column Name | Type | +-------------+---------+ | user_id | int | | spend_date | date | | platform | enum | | amount | int | +-------------+---------+ 这张表记录了用户在一个在线购物网站的支出历史,该在线购物平台同时拥有桌面端('desktop')和手机端('mobile')的应用程序。 这张表的主键是 (user_id, spend_date, platform)。 平台列 platform 是一种 ENUM ,类型为('desktop', 'mobile')。
写一段 SQL 来查找每天 仅 使用手机端用户、仅 使用桌面端用户和 同时 使用桌面端和手机端的用户人数和总支出金额。
查询结果格式如下例所示:
Spending table: +---------+------------+----------+--------+ | user_id | spend_date | platform | amount | +---------+------------+----------+--------+ | 1 | 2019-07-01 | mobile | 100 | | 1 | 2019-07-01 | desktop | 100 | | 2 | 2019-07-01 | mobile | 100 | | 2 | 2019-07-02 | mobile | 100 | | 3 | 2019-07-01 | desktop | 100 | | 3 | 2019-07-02 | desktop | 100 | +---------+------------+----------+--------+ Result table: +------------+----------+--------------+-------------+ | spend_date | platform | total_amount | total_users | +------------+----------+--------------+-------------+ | 2019-07-01 | desktop | 100 | 1 | | 2019-07-01 | mobile | 100 | 1 | | 2019-07-01 | both | 200 | 1 | | 2019-07-02 | desktop | 100 | 1 | | 2019-07-02 | mobile | 100 | 1 | | 2019-07-02 | both | 0 | 0 | +------------+----------+--------------+-------------+ 在 2019-07-01, 用户1 同时 使用桌面端和手机端购买, 用户2 仅 使用了手机端购买,而用户3 仅 使用了桌面端购买。 在 2019-07-02, 用户2 仅 使用了手机端购买, 用户3 仅 使用了桌面端购买,且没有用户 同时 使用桌面端和手机端购买。
解答 SQL架构
Create table If Not Exists Users (user_id int , join_date date , favorite_brand varchar (10 ))create table if not exists Orders (order_id int , order_date date , item_id int , buyer_id int , seller_id int )create table if not exists Items (item_id int , item_brand varchar (10 ))Truncate table Users insert into Users (user_id, join_date, favorite_brand) values ('1' , '2019-01-01' , 'Lenovo' )insert into Users (user_id, join_date, favorite_brand) values ('2' , '2019-02-09' , 'Samsung' )insert into Users (user_id, join_date, favorite_brand) values ('3' , '2019-01-19' , 'LG' )insert into Users (user_id, join_date, favorite_brand) values ('4' , '2019-05-21' , 'HP' )Truncate table Ordersinsert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('1' , '2019-08-01' , '4' , '1' , '2' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('2' , '2019-08-02' , '2' , '1' , '3' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('3' , '2019-08-03' , '3' , '2' , '3' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('4' , '2019-08-04' , '1' , '4' , '2' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('5' , '2019-08-04' , '1' , '3' , '4' )insert into Orders (order_id, order_date, item_id, buyer_id, seller_id) values ('6' , '2019-08-05' , '2' , '2' , '4' )Truncate table Itemsinsert into Items (item_id, item_brand) values ('1' , 'Samsung' )insert into Items (item_id, item_brand) values ('2' , 'Lenovo' )insert into Items (item_id, item_brand) values ('3' , 'LG' )insert into Items (item_id, item_brand) values ('4' , 'HP' )
表: Users
+----------------+---------+ | Column Name | Type | +----------------+---------+ | user_id | int | | join_date | date | | favorite_brand | varchar | +----------------+---------+ user_id 是该表的主键 表中包含一位在线购物网站用户的个人信息,用户可以在该网站出售和购买商品。
表: Orders
+---------------+---------+ | Column Name | Type | +---------------+---------+ | order_id | int | | order_date | date | | item_id | int | | buyer_id | int | | seller_id | int | +---------------+---------+ order_id 是该表的主键 item_id 是 Items 表的外键 buyer_id 和 seller_id 是 Users 表的外键
表: Items
+---------------+---------+ | Column Name | Type | +---------------+---------+ | item_id | int | | item_brand | varchar | +---------------+---------+ item_id 是该表的主键
写一个 SQL 查询确定每一个用户按日期顺序卖出的第二件商品的品牌是否是他们最喜爱的品牌。如果一个用户卖出少于两件商品,查询的结果是 no 。
题目保证没有一个用户在一天中卖出超过一件商品
下面是查询结果格式的例子:
Users table: +---------+------------+----------------+ | user_id | join_date | favorite_brand | +---------+------------+----------------+ | 1 | 2019-01-01 | Lenovo | | 2 | 2019-02-09 | Samsung | | 3 | 2019-01-19 | LG | | 4 | 2019-05-21 | HP | +---------+------------+----------------+ Orders table: +----------+------------+---------+----------+-----------+ | order_id | order_date | item_id | buyer_id | seller_id | +----------+------------+---------+----------+-----------+ | 1 | 2019-08-01 | 4 | 1 | 2 | | 2 | 2019-08-02 | 2 | 1 | 3 | | 3 | 2019-08-03 | 3 | 2 | 3 | | 4 | 2019-08-04 | 1 | 4 | 2 | | 5 | 2019-08-04 | 1 | 3 | 4 | | 6 | 2019-08-05 | 2 | 2 | 4 | +----------+------------+---------+----------+-----------+ Items table: +---------+------------+ | item_id | item_brand | +---------+------------+ | 1 | Samsung | | 2 | Lenovo | | 3 | LG | | 4 | HP | +---------+------------+ Result table: +-----------+--------------------+ | seller_id | 2nd_item_fav_brand | +-----------+--------------------+ | 1 | no | | 2 | yes | | 3 | yes | | 4 | no | +-----------+--------------------+ id 为 1 的用户的查询结果是 no,因为他什么也没有卖出 id为 2 和 3 的用户的查询结果是 yes,因为他们卖出的第二件商品的品牌是他们自己最喜爱的品牌 id为 4 的用户的查询结果是 no,因为他卖出的第二件商品的品牌不是他最喜爱的品牌
解答 SQL架构
Create table If Not Exists Numbers (Number int , Frequency int )Truncate table Numbersinsert into Numbers (Number , Frequency) values ('0' , '7' )insert into Numbers (Number , Frequency) values ('1' , '1' )insert into Numbers (Number , Frequency) values ('2' , '3' )insert into Numbers (Number , Frequency) values ('3' , '1' )
Numbers 表保存数字的值及其频率。
+----------+-------------+ | Number | Frequency | +----------+-------------| | 0 | 7 | | 1 | 1 | | 2 | 3 | | 3 | 1 | +----------+-------------+
在此表中,数字为 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 3,所以中位数是 (0 + 0) / 2 = 0。
+--------+ | median | +--------| | 0.0000 | +--------+
请编写一个查询来查找所有数字的中位数并将结果命名为 median 。
解答 SQL架构
Create table If Not Exists Trips (Id int , Client_Id int , Driver_Id int , City_Id int , Status ENUM('completed' , 'cancelled_by_driver' , 'cancelled_by_client' ), Request_at varchar (50 ))Create table If Not Exists Users (Users_Id int , Banned varchar (50 ), Role ENUM('client' , 'driver' , 'partner' ))Truncate table Tripsinsert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('1' , '1' , '10' , '1' , 'completed' , '2013-10-01' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('2' , '2' , '11' , '1' , 'cancelled_by_driver' , '2013-10-01' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('3' , '3' , '12' , '6' , 'completed' , '2013-10-01' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('4' , '4' , '13' , '6' , 'cancelled_by_client' , '2013-10-01' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('5' , '1' , '10' , '1' , 'completed' , '2013-10-02' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('6' , '2' , '11' , '6' , 'completed' , '2013-10-02' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('7' , '3' , '12' , '6' , 'completed' , '2013-10-02' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('8' , '2' , '12' , '12' , 'completed' , '2013-10-03' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('9' , '3' , '10' , '12' , 'completed' , '2013-10-03' )insert into Trips (Id , Client_Id, Driver_Id, City_Id, Status , Request_at) values ('10' , '4' , '13' , '12' , 'cancelled_by_driver' , '2013-10-03' )Truncate table Users insert into Users (Users_Id, Banned, Role ) values ('1' , 'No' , 'client' )insert into Users (Users_Id, Banned, Role ) values ('2' , 'Yes' , 'client' )insert into Users (Users_Id, Banned, Role ) values ('3' , 'No' , 'client' )insert into Users (Users_Id, Banned, Role ) values ('4' , 'No' , 'client' )insert into Users (Users_Id, Banned, Role ) values ('10' , 'No' , 'driver' )insert into Users (Users_Id, Banned, Role ) values ('11' , 'No' , 'driver' )insert into Users (Users_Id, Banned, Role ) values ('12' , 'No' , 'driver' )insert into Users (Users_Id, Banned, Role ) values ('13' , 'No' , 'driver' )
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
+----+-----------+-----------+---------+--------------------+----------+ | Id | Client_Id | Driver_Id | City_Id | Status |Request_at| +----+-----------+-----------+---------+--------------------+----------+ | 1 | 1 | 10 | 1 | completed |2013-10-01| | 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01| | 3 | 3 | 12 | 6 | completed |2013-10-01| | 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01| | 5 | 1 | 10 | 1 | completed |2013-10-02| | 6 | 2 | 11 | 6 | completed |2013-10-02| | 7 | 3 | 12 | 6 | completed |2013-10-02| | 8 | 2 | 12 | 12 | completed |2013-10-03| | 9 | 3 | 10 | 12 | completed |2013-10-03| | 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03| +----+-----------+-----------+---------+--------------------+----------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+ | Users_Id | Banned | Role | +----------+--------+--------+ | 1 | No | client | | 2 | Yes | client | | 3 | No | client | | 4 | No | client | | 10 | No | driver | | 11 | No | driver | | 12 | No | driver | | 13 | No | driver | +----------+--------+--------+
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
取消率的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)
+------------+-------------------+ | Day | Cancellation Rate | +------------+-------------------+ | 2013-10-01 | 0.33 | | 2013-10-02 | 0.00 | | 2013-10-03 | 0.50 | +------------+-------------------+
致谢: @cak1erlizhou 详细的提供了这道题和相应的测试用例。
解答 SQL架构
Create table If Not Exists stadium (id int , visit_date DATE NULL , people int )Truncate table stadiuminsert into stadium (id , visit_date, people) values ('1' , '2017-01-01' , '10' )insert into stadium (id , visit_date, people) values ('2' , '2017-01-02' , '109' )insert into stadium (id , visit_date, people) values ('3' , '2017-01-03' , '150' )insert into stadium (id , visit_date, people) values ('4' , '2017-01-04' , '99' )insert into stadium (id , visit_date, people) values ('5' , '2017-01-05' , '145' )insert into stadium (id , visit_date, people) values ('6' , '2017-01-06' , '1455' )insert into stadium (id , visit_date, people) values ('7' , '2017-01-07' , '199' )insert into stadium (id , visit_date, people) values ('8' , '2017-01-08' , '188' )
X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)。
请编写一个查询语句,找出人流量的高峰期。高峰期时,至少连续三行记录中的人流量不少于100。
例如,表 stadium:
+------+------------+-----------+ | id | visit_date | people | +------+------------+-----------+ | 1 | 2017-01-01 | 10 | | 2 | 2017-01-02 | 109 | | 3 | 2017-01-03 | 150 | | 4 | 2017-01-04 | 99 | | 5 | 2017-01-05 | 145 | | 6 | 2017-01-06 | 1455 | | 7 | 2017-01-07 | 199 | | 8 | 2017-01-08 | 188 | +------+------------+-----------+
对于上面的示例数据,输出为:
+------+------------+-----------+ | id | visit_date | people | +------+------------+-----------+ | 5 | 2017-01-05 | 145 | | 6 | 2017-01-06 | 1455 | | 7 | 2017-01-07 | 199 | | 8 | 2017-01-08 | 188 | +------+------------+-----------+
提示:
解答 SQL架构
Create table If Not Exists Activity (player_id int , device_id int , event_date date , games_played int )Truncate table Activityinsert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-03-01' , '5' )insert into Activity (player_id, device_id, event_date, games_played) values ('1' , '2' , '2016-03-02' , '6' )insert into Activity (player_id, device_id, event_date, games_played) values ('2' , '3' , '2017-06-25' , '1' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '1' , '2016-03-01' , '0' )insert into Activity (player_id, device_id, event_date, games_played) values ('3' , '4' , '2018-07-03' , '5' )
Activity 活动记录表
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ (player_id,event_date)是此表的主键 这张表显示了某些游戏的玩家的活动情况 每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0)
我们将玩家的安装日期定义为该玩家的第一个登录日。
我们还将某个日期 X 的第 1 天保留时间定义为安装日期为 X 的玩家的数量,他们在 X 之后的一天重新登录,除以安装日期为 X 的玩家的数量,四舍五入到小数点后两位。
编写一个 SQL 查询,报告每个安装日期、当天安装游戏的玩家数量和第一天的保留时间。
查询结果格式如下所示:
Activity 表: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-03-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-01 | 0 | | 3 | 4 | 2016-07-03 | 5 | +-----------+-----------+------------+--------------+ Result 表: +------------+----------+----------------+ | install_dt | installs | Day1_retention | +------------+----------+----------------+ | 2016-03-01 | 2 | 0.50 | | 2017-06-25 | 1 | 0.00 | +------------+----------+----------------+ 玩家 1 和 3 在 2016-03-01 安装了游戏,但只有玩家 1 在 2016-03-02 重新登录,所以 2016-03-01 的第一天保留时间是 1/2=0.50 玩家 2 在 2017-06-25 安装了游戏,但在 2017-06-26 没有重新登录,因此 2017-06-25 的第一天保留为 0/1=0.00
解答 SQL架构
Create table If Not Exists Players (player_id int , group_id int )Create table If Not Exists Matches (match_id int , first_player int , second_player int , first_score int , second_score int )Truncate table Playersinsert into Players (player_id, group_id ) values ('10' , '2' )insert into Players (player_id, group_id ) values ('15' , '1' )insert into Players (player_id, group_id ) values ('20' , '3' )insert into Players (player_id, group_id ) values ('25' , '1' )insert into Players (player_id, group_id ) values ('30' , '1' )insert into Players (player_id, group_id ) values ('35' , '2' )insert into Players (player_id, group_id ) values ('40' , '3' )insert into Players (player_id, group_id ) values ('45' , '1' )insert into Players (player_id, group_id ) values ('50' , '2' )Truncate table Matchesinsert into Matches (match_id, first_player, second_player, first_score, second_score) values ('1' , '15' , '45' , '3' , '0' )insert into Matches (match_id, first_player, second_player, first_score, second_score) values ('2' , '30' , '25' , '1' , '2' )insert into Matches (match_id, first_player, second_player, first_score, second_score) values ('3' , '30' , '15' , '2' , '0' )insert into Matches (match_id, first_player, second_player, first_score, second_score) values ('4' , '40' , '20' , '5' , '2' )insert into Matches (match_id, first_player, second_player, first_score, second_score) values ('5' , '35' , '50' , '1' , '1' )
Players 玩家表
+-------------+-------+ | Column Name | Type | +-------------+-------+ | player_id | int | | group_id | int | +-------------+-------+ 玩家 ID 是此表的主键。 此表的每一行表示每个玩家的组。
Matches 赛事表
+---------------+---------+ | Column Name | Type | +---------------+---------+ | match_id | int | | first_player | int | | second_player | int | | first_score | int | | second_score | int | +---------------+---------+ match_id 是此表的主键。 每一行是一场比赛的记录,第一名和第二名球员包含每场比赛的球员 ID。 第一个玩家和第二个玩家的分数分别包含第一个玩家和第二个玩家的分数。 你可以假设,在每一场比赛中,球员都属于同一组。
每组的获胜者是在组内得分最高的选手。如果平局,player_id 最小 的选手获胜。
编写一个 SQL 查询来查找每组中的获胜者。
查询结果格式如下所示
Players 表: +-----------+------------+ | player_id | group_id | +-----------+------------+ | 15 | 1 | | 25 | 1 | | 30 | 1 | | 45 | 1 | | 10 | 2 | | 35 | 2 | | 50 | 2 | | 20 | 3 | | 40 | 3 | +-----------+------------+ Matches 表: +------------+--------------+---------------+-------------+--------------+ | match_id | first_player | second_player | first_score | second_score | +------------+--------------+---------------+-------------+--------------+ | 1 | 15 | 45 | 3 | 0 | | 2 | 30 | 25 | 1 | 2 | | 3 | 30 | 15 | 2 | 0 | | 4 | 40 | 20 | 5 | 2 | | 5 | 35 | 50 | 1 | 1 | +------------+--------------+---------------+-------------+--------------+ Result 表: +-----------+------------+ | group_id | player_id | +-----------+------------+ | 1 | 15 | | 2 | 35 | | 3 | 40 | +-----------+------------+
解答 SQL架构
Create table If Not Exists Visits (user_id int , visit_date date )Create table If Not Exists Transactions (user_id int , transaction_date date , amount int )Truncate table Visitsinsert into Visits (user_id, visit_date) values ('1' , '2020-01-01' )insert into Visits (user_id, visit_date) values ('2' , '2020-01-02' )insert into Visits (user_id, visit_date) values ('12' , '2020-01-01' )insert into Visits (user_id, visit_date) values ('19' , '2020-01-03' )insert into Visits (user_id, visit_date) values ('1' , '2020-01-02' )insert into Visits (user_id, visit_date) values ('2' , '2020-01-03' )insert into Visits (user_id, visit_date) values ('1' , '2020-01-04' )insert into Visits (user_id, visit_date) values ('7' , '2020-01-11' )insert into Visits (user_id, visit_date) values ('9' , '2020-01-25' )insert into Visits (user_id, visit_date) values ('8' , '2020-01-28' )Truncate table Transactionsinsert into Transactions (user_id, transaction_date, amount) values ('1' , '2020-01-02' , '120' )insert into Transactions (user_id, transaction_date, amount) values ('2' , '2020-01-03' , '22' )insert into Transactions (user_id, transaction_date, amount) values ('7' , '2020-01-11' , '232' )insert into Transactions (user_id, transaction_date, amount) values ('1' , '2020-01-04' , '7' )insert into Transactions (user_id, transaction_date, amount) values ('9' , '2020-01-25' , '33' )insert into Transactions (user_id, transaction_date, amount) values ('9' , '2020-01-25' , '66' )insert into Transactions (user_id, transaction_date, amount) values ('8' , '2020-01-28' , '1' )insert into Transactions (user_id, transaction_date, amount) values ('9' , '2020-01-25' , '99' )
表: Visits
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | visit_date | date | +---------------+---------+ (user_id, visit_date) 是该表的主键 该表的每行表示 user_id 在 visit_date 访问了银行
表: Transactions
+------------------+---------+ | Column Name | Type | +------------------+---------+ | user_id | int | | transaction_date | date | | amount | int | +------------------+---------+ 该表没有主键,所以可能有重复行 该表的每一行表示 user_id 在 transaction_date 完成了一笔 amount 数额的交易 可以保证用户 (user) 在 transaction_date 访问了银行 (也就是说 Visits 表包含 (user_id, transaction_date) 行)
银行想要得到银行客户在一次访问时的交易次数和相应的在一次访问时该交易次数的客户数量的图表
写一条 SQL 查询多少客户访问了银行但没有进行任何交易,多少客户访问了银行进行了一次交易等等
结果包含两列:
transactions_count: 客户在一次访问中的交易次数visits_count: 在 transactions_count 交易次数下相应的一次访问时的客户数量
transactions_count` 的值从 `0` 到所有用户一次访问中的 `max(transactions_count)
按 transactions_count 排序
下面是查询结果格式的例子:
Visits 表: +---------+------------+ | user_id | visit_date | +---------+------------+ | 1 | 2020-01-01 | | 2 | 2020-01-02 | | 12 | 2020-01-01 | | 19 | 2020-01-03 | | 1 | 2020-01-02 | | 2 | 2020-01-03 | | 1 | 2020-01-04 | | 7 | 2020-01-11 | | 9 | 2020-01-25 | | 8 | 2020-01-28 | +---------+------------+ Transactions 表: +---------+------------------+--------+ | user_id | transaction_date | amount | +---------+------------------+--------+ | 1 | 2020-01-02 | 120 | | 2 | 2020-01-03 | 22 | | 7 | 2020-01-11 | 232 | | 1 | 2020-01-04 | 7 | | 9 | 2020-01-25 | 33 | | 9 | 2020-01-25 | 66 | | 8 | 2020-01-28 | 1 | | 9 | 2020-01-25 | 99 | +---------+------------------+--------+ 结果表: +--------------------+--------------+ | transactions_count | visits_count | +--------------------+--------------+ | 0 | 4 | | 1 | 5 | | 2 | 0 | | 3 | 1 | +--------------------+--------------+ * 对于 transactions_count = 0, visits 中 (1, "2020-01-01"), (2, "2020-01-02"), (12, "2020-01-01") 和 (19, "2020-01-03") 没有进行交易,所以 visits_count = 4 。 * 对于 transactions_count = 1, visits 中 (2, "2020-01-03"), (7, "2020-01-11"), (8, "2020-01-28"), (1, "2020-01-02") 和 (1, "2020-01-04") 进行了一次交易,所以 visits_count = 5 。 * 对于 transactions_count = 2, 没有客户访问银行进行了两次交易,所以 visits_count = 0 。 * 对于 transactions_count = 3, visits 中 (9, "2020-01-25") 进行了三次交易,所以 visits_count = 1 。 * 对于 transactions_count >= 4, 没有客户访问银行进行了超过3次交易,所以我们停止在 transactions_count = 3 。
如下是这个例子的图表:
解答 SQL架构
Create table If Not Exists Employee (Id int , Name varchar (255 ), Salary int , DepartmentId int )Create table If Not Exists Department (Id int , Name varchar (255 ))Truncate table Employeeinsert into Employee (Id , Name , Salary, DepartmentId) values ('1' , 'Joe' , '85000' , '1' )insert into Employee (Id , Name , Salary, DepartmentId) values ('2' , 'Henry' , '80000' , '2' )insert into Employee (Id , Name , Salary, DepartmentId) values ('3' , 'Sam' , '60000' , '2' )insert into Employee (Id , Name , Salary, DepartmentId) values ('4' , 'Max' , '90000' , '1' )insert into Employee (Id , Name , Salary, DepartmentId) values ('5' , 'Janet' , '69000' , '1' )insert into Employee (Id , Name , Salary, DepartmentId) values ('6' , 'Randy' , '85000' , '1' )insert into Employee (Id , Name , Salary, DepartmentId) values ('7' , 'Will' , '70000' , '1' )Truncate table Departmentinsert into Department (Id , Name ) values ('1' , 'IT' )insert into Department (Id , Name ) values ('2' , 'Sales' )
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
+----+-------+--------+--------------+ | Id | Name | Salary | DepartmentId | +----+-------+--------+--------------+ | 1 | Joe | 85000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | | 5 | Janet | 69000 | 1 | | 6 | Randy | 85000 | 1 | | 7 | Will | 70000 | 1 | +----+-------+--------+--------------+
Department 表包含公司所有部门的信息。
+----+----------+ | Id | Name | +----+----------+ | 1 | IT | | 2 | Sales | +----+----------+
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
+------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | IT | Randy | 85000 | | IT | Joe | 85000 | | IT | Will | 70000 | | Sales | Henry | 80000 | | Sales | Sam | 60000 | +------------+----------+--------+
解释:
IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
解答 SQL架构
Create table If Not Exists salary (id int , employee_id int , amount int , pay_date date )Create table If Not Exists employee (employee_id int , department_id int )Truncate table salaryinsert into salary (id , employee_id, amount, pay_date) values ('1' , '1' , '9000' , '2017/03/31' )insert into salary (id , employee_id, amount, pay_date) values ('2' , '2' , '6000' , '2017/03/31' )insert into salary (id , employee_id, amount, pay_date) values ('3' , '3' , '10000' , '2017/03/31' )insert into salary (id , employee_id, amount, pay_date) values ('4' , '1' , '7000' , '2017/02/28' )insert into salary (id , employee_id, amount, pay_date) values ('5' , '2' , '6000' , '2017/02/28' )insert into salary (id , employee_id, amount, pay_date) values ('6' , '3' , '8000' , '2017/02/28' )Truncate table employeeinsert into employee (employee_id, department_id) values ('1' , '1' )insert into employee (employee_id, department_id) values ('2' , '2' )insert into employee (employee_id, department_id) values ('3' , '2' )
给如下两个表,写一个查询语句,求出在每一个工资发放日,每个部门的平均工资与公司的平均工资的比较结果 (高 / 低 / 相同)。
表: salary
| id | employee_id | amount | pay_date | |----|-------------|--------|------------| | 1 | 1 | 9000 | 2017-03-31 | | 2 | 2 | 6000 | 2017-03-31 | | 3 | 3 | 10000 | 2017-03-31 | | 4 | 1 | 7000 | 2017-02-28 | | 5 | 2 | 6000 | 2017-02-28 | | 6 | 3 | 8000 | 2017-02-28 |
employee_id 字段是表 employee 中 employee_id 字段的外键。
| employee_id | department_id | |-------------|---------------| | 1 | 1 | | 2 | 2 | | 3 | 2 |
对于如上样例数据,结果为:
| pay_month | department_id | comparison | |-----------|---------------|-------------| | 2017-03 | 1 | higher | | 2017-03 | 2 | lower | | 2017-02 | 1 | same | | 2017-02 | 2 | same |
解释
在三月,公司的平均工资是 (9000+6000+10000)/3 = 8333.33…
由于部门 ‘1’ 里只有一个 employee_id 为 ‘1’ 的员工,所以部门 ‘1’ 的平均工资就是此人的工资 9000 。因为 9000 > 8333.33 ,所以比较结果是 ‘higher’。
第二个部门的平均工资为 employee_id 为 ‘2’ 和 ‘3’ 两个人的平均工资,为 (6000+10000)/2=8000 。因为 8000 < 8333.33 ,所以比较结果是 ‘lower’ 。
在二月用同样的公式求平均工资并比较,比较结果为 ‘same’ ,因为部门 ‘1’ 和部门 ‘2’ 的平均工资与公司的平均工资相同,都是 7000 。
解答 SQL架构
Create table If Not Exists Employee (Id int , Month int , Salary int )Truncate table Employeeinsert into Employee (Id , Month , Salary) values ('1' , '1' , '20' )insert into Employee (Id , Month , Salary) values ('2' , '1' , '20' )insert into Employee (Id , Month , Salary) values ('1' , '2' , '30' )insert into Employee (Id , Month , Salary) values ('2' , '2' , '30' )insert into Employee (Id , Month , Salary) values ('3' , '2' , '40' )insert into Employee (Id , Month , Salary) values ('1' , '3' , '40' )insert into Employee (Id , Month , Salary) values ('3' , '3' , '60' )insert into Employee (Id , Month , Salary) values ('1' , '4' , '60' )insert into Employee (Id , Month , Salary) values ('3' , '4' , '70' )
Employee 表保存了一年内的薪水信息。
请你编写 SQL 语句,来查询每个员工每个月最近三个月的累计薪水(不包括当前统计月,不足三个月也要计算)。
结果请按 ‘Id’ 升序,然后按 ‘Month’ 降序显示。
示例: 输入:
| Id | Month | Salary | |----|-------|--------| | 1 | 1 | 20 | | 2 | 1 | 20 | | 1 | 2 | 30 | | 2 | 2 | 30 | | 3 | 2 | 40 | | 1 | 3 | 40 | | 3 | 3 | 60 | | 1 | 4 | 60 | | 3 | 4 | 70 |
输出:
| Id | Month | Salary | |----|-------|--------| | 1 | 3 | 90 | | 1 | 2 | 50 | | 1 | 1 | 20 | | 2 | 1 | 20 | | 3 | 3 | 100 | | 3 | 2 | 40 |
解释:
员工 ‘1’ 除去最近一个月(月份 ‘4’),有三个月的薪水记录:月份 ‘3’ 薪水为 40,月份 ‘2’ 薪水为 30,月份 ‘1’ 薪水为 20。
所以近 3 个月的薪水累计分别为 (40 + 30 + 20) = 90,(30 + 20) = 50 和 20。
| Id | Month | Salary | |----|-------|--------| | 1 | 3 | 90 | | 1 | 2 | 50 | | 1 | 1 | 20 |
员工 ‘2’ 除去最近的一个月(月份 ‘2’)的话,只有月份 ‘1’ 这一个月的薪水记录。
| Id | Month | Salary | |----|-------|--------| | 2 | 1 | 20 |
员工 ‘3’ 除去最近一个月(月份 ‘4’)后有两个月,分别为:月份 ‘4’ 薪水为 60 和 月份 ‘2’ 薪水为 40。所以各月的累计情况如下:
| Id | Month | Salary | |----|-------|--------| | 3 | 3 | 100 | | 3 | 2 | 40 |
解答