
每天学点新东西
exeinfo 可以看到壳信息 |
libc查询 http://libcdb.com/
查找到gadget
objdump -d babypwn4 | egrep "ret|pop" |
linux下shellcode的编写
- 在 shellcode 中不能出现 /x00也就是NULL字符,当出现NULL字符的时候将会导致shellcode被截断,从而无法完成其应有的功能
- 有一个int $0x80来执行系统调用
windows shellcode
|
pwn全景图

求余数运算反汇编,两者等价。
v5 = 3 * v0 - 0X30 * ((unsigned __int64)(0xAAAAAAAAAAAAAAABLL * (unsigned __int128)(3 * v0) >> 64) >> 5); |
Assembly
Intel vs AT&T
- 操作数顺序不同
- 寄存器记法有差异
- 立即数记法有差异
- 访存寻址计法不同
- 操作码助记符不同

程序模板
TITLE Program Template ; 标题可有可无 |
寄存器
; 16 bits 8 bits 8 bits |
数据类型
var db ? ; 声明一个字节,未初始化 |
寻址模式
直接内存寻址
寄存器间接寻址
mov eax, [ebx] ; 将 ebx 值指示的内存地址中的 4 个字节传送到 eax 中 |
常用指令
mov
mov <reg>, <reg> |
push
push <reg32> |
pop
lea
Load Effective Address
lea <reg32>, <mem> |
leave
在32位汇编下相当于: |
ret
push src ; 将 src 的数据存入栈中,不允许使用立即数寻址方式。 |
控制转移
jmp ;无条件 |
JE ;等于则跳转 |
Clang
C 语言的奇技淫巧 https://jin-yang.github.io/post/program-c-tips.html
常用函数
sprintf(); |
static
静态全局变量:自动初始化为 0,只在声明它的整个文件中可见。
静态函数:只能在声明它的文件当中可见,不能被其他文件使用,降低命名冲突。
Reverse
C++逆向学习三步走 https://bbs.pediy.com/thread-113689.htm
要求
- 熟悉如操作系统,汇编语言,加解密等相关知识
- 具有丰富的多种高级语言的编程经验
- 熟悉多种编译器的编译原理
- 较强的程序理解和逆向分析能力
常规逆向流程
- 使用
strings/file/binwalk/IDA等静态分析工具收集信息,并根据这些静态信息进行google/github搜索 - 研究程序的保护方法,如代码混淆,保护壳及反调试等技术,并设法破除或绕过保护
- 反汇编目标软件,快速定位到关键代码进行分析
- 结合动态调试,验证自己的初期猜想,在分析的过程中理清程序功能
- 针对程序功能,写出对应脚本,求解出 flag
定位关键代码 tips
分析控制流
控制流可以参见 IDA 生成的控制流程图(CFG),沿着分支循环和函数调用,逐块地阅读反汇编代码进行分析。
利用数据、代码交叉引用
比如输出的提示字符串,可以通过数据交叉引用找到对应的调用位置,进而找出关键代码。代码交叉引用比如图形界面程序获取用户输入,就可以使用对应的 windowsAPI 函数,我们就可以通过这些 API 函数调用位置找到关键代码。
逆向 tips
编码风格
每个程序员的编码风格都有所不同,熟悉开发设计模式的同学能更迅速地分析出函数模块功能
集中原则
程序员开发程序时,往往习惯将功能相关的代码或是数据写在同一个地方,而在反汇编代码中也能显示出这一情况,因此在分析时可以查看关键代码附近的函数和数据。
代码复用
代码复用情况非常普遍,而最大的源代码仓库 Github 则是最主要的来源。在分析时可以找一些特征(如字符串,代码风格等)在 Github 搜索,可能会发现类似的代码,并据此恢复出分析时缺失的符号信息等。
七分逆向三分猜
合理的猜测往往能事半功倍,遇到可疑函数却看不清里面的逻辑,不妨根据其中的蛛丝马迹猜测其功能,并依据猜测继续向下分析,在不断的猜测验证中,或许能帮助你更加接近代码的真相。
区分代码
拿到反汇编代码,必须能区分哪些代码是人为编写的,而哪些是编译器自动附加的代码。人为编写的代码中,又有哪些是库函数代码,哪些才是出题人自己写的代码,出题人的代码又经过编译器怎样的优化?我们无须花费时间在出题人以外的代码上,这很重要。如果当你分析半天还在库函数里乱转,那不仅体验极差,也没有丝毫效果。
耐心
无论如何,给予足够的时间,总是能将一个程序分析地透彻。但是也不应该过早地放弃分析。相信自己肯定能在抽茧剥丝的过程中突破问题。
动态分析
动态分析的目的在于定位关键代码后,在程序运行的过程中,借由输出信息(寄存器,内存变化,程序输出)等来验证自己的推断或是理解程序功能
主要方法有:调试,符号执行,污点分析
借用系统调用的跟踪工具看一下宏观动作?
- strace:trace all system call
- ltrace:trace all library call
- ptrace
- dtruss(Mac)
算法和数据结构识别
- 常用算法识别
如 Tea / XTea / XXTea / IDEA / RC4 / RC5 / RC6 / AES / DES / IDEA / MD5 / SHA256 / SHA1 等加密算法,大数加减乘除、最短路等传统算法
- 常用数据结构识别
如图、树、哈希表等高级数据结构在汇编代码中的识别。
代码混淆
比如使用OLLVM,movfuscator,花指令,虚拟化及SMC等工具技术对代码进行混淆,使得程序分析十分困难。
那么对应的也有反混淆技术,最主要的目的就是复原控制流。比如模拟执行和符号执行
保护壳
保护壳类型有许多,简单的压缩壳可以归类为如下几种
unpack -> execute
直接将程序代码全部解压到内存中再继续执行程序代码
unpack -> execute -> unpack -> execute …
解压部分代码,再边解压边执行
unpack -> [decoder | encoded code] -> decode -> execute
程序代码有过编码,在解压后再运行函数将真正的程序代码解码执行
对于脱壳也有相关的方法,比如单步调试法,ESP定律等等
反调试
反调试意在通过检测调试器等方法避免程序被调试分析。比如使用一些 API 函数如IsDebuggerPresent检测调试器,使用SEH异常处理,时间差检测等方法。也可以通过覆写调试端口、自调试等方法进行保护。
非常规逆向思路
非常规逆向题设计的题目范围非常之广,可以是任意架构的任意格式文件。
- lua / python / java / lua-jit / haskell / applescript / js / solidity / webassembly / etc..
- firmware / raw bin / etc..
- chip8 / avr / clemency / risc-v / etc.
但是逆向工程的方法学里不惧怕这些未知的平台格式,遇到这样的非常规题,我们也有一些基本的流程可以通用
前期准备
- 阅读文档。快速学习平台语言的方法就是去阅读官方文档。
- 官方工具。官方提供或建议的工具必然是最合适的工具
- 教程。在逆向方面,也许有许多前辈写出了专门针对该平台语言的逆向教程,因此也可以快速吸收这其中的知识。
找工具
主要找文件解析工具、反汇编器、调试器和反编译器。其中反汇编器是必需的,调试器也包含有相应的反汇编功能,而对于反编译器则要自求多福了,得之我幸失之我命。
找工具总结起来就是:Google 大法好。合理利用 Google 搜索语法,进行关键字搜索可以帮助你更快更好地找到合适工具。
寻找主入口(main函数)
字符串搜索法
栈回溯法
逐步分析法
Stack Overflow
学习环境 https://exploit.education/phoenix/stack-five
视频教程 https://www.youtube.com/watch?v=HSlhY4Uy8SA
手把手教你栈溢出从入门到放弃
https://zhuanlan.zhihu.com/p/25816426
https://zhuanlan.zhihu.com/p/25892385
ctf-wiki https://ctf-wiki.github.io/ctf-wiki/pwn/linux/stackoverflow/basic-rop-zh/#ret2text
Pwn入坑指南 https://www.cnblogs.com/wintrysec/p/10616856.html
熊师傅推荐的题库 https://github.com/scwuaptx/HITCON-Training
视频教程 入门学习路线 https://www.bilibili.com/video/av13427867
发生栈溢出的基本前提:
- 程序必须向栈上写入数据;
- 写入的数据大小没有被良好地控制。
Basic
调用约定
- 实现了层面(底层)的规范
- 约定了函数之间如何传递参数
- 约定了函数如何传递返回值
ebp(rbp) 用途:
- 索引栈上的参数,例如 x86 下,ebp + 8 指向第一个参数
- 保存栈顶位置 esp(rsp)
常见 x86 调用约定:
- 调用者负责清理栈上的参数(Caller Clean-up)
- cdecl
- 用栈传参
- 用 eax 保存返回值
- optlink
- cdecl
- 被调用者负责清理栈上的参数(Callee Clean-up)
- stdcall
- fastcall
需要注意的是,32 位和 64 位程序有以下简单的区别:
- x86
- 函数参数在函数返回地址的上方
- x64
- System V AMD64 ABI (Linux、FreeBSD、macOS 等采用) 中前六个整型或指针参数依次保存在 RDI, RSI, RDX, RCX, R8 和 R9 寄存器中,如果还有更多的参数的话才会保存在栈上。
- 内存地址不能大于 0x00007FFFFFFFFFFF,6 个字节长度,否则会抛出异常。
- cdecl 使用寄存器 rdi、rsi、rdx、rcx、r8、r9 传前 6 个,第七个及以上使用栈传递
int callee(int a, int b, int c) { |
pwndbg> disass callee |
类型
修改返回地址,让其指向溢出数据中的一段指令(shellcode)
修改返回地址,让其指向内存中已有的某个函数(return2libc)
修改返回地址,让其指向内存中已有的一段指令(ROP)
修改某个被调用函数的地址,让其指向另一个函数(hijack GOT)
Format Strings
| 函数 | 基本介绍 |
|---|---|
| printf | 输出到 stdout |
| fprintf | 输出到指定 FILE 流 |
| vprintf | 根据参数列表格式化输出到 stdout |
| vfprintf | 根据参数列表格式化输出到指定 FILE 流 |
| sprintf | 输出到字符串 |
| snprintf | 输出指定字节数到字符串 |
| vsprintf | 根据参数列表格式化输出到字符串 |
| vsnprintf | 根据参数列表格式化输出指定字节到字符串 |
| setproctitle | 设置 argv |
| syslog | 输出日志 |
| err, verr, warn, vwarn 等 | …… |
Array Indexing
Bad Seed
Z3 & Symbolic Execution(angr)
ROP
Return Oriented Programming
Partial Overwrite
Stack Pivoting
SIGROP(SROP)
ret2csu
ret2system
Heap Exploitation
Double Frees
Heap Consolidation
Use after Frees
Protostar: heap0
protostar: heap1
protostar: heap2
unlink() Exploitation
Heap Grooming
Fastbin Attack
Unsortedbin Attack
Largebin Attack
GLibc Tcache
House of Spirit
House of Lore
House of Force
House of Einherjar
House of Orange
Miscellaneous
Grab Bag
Shell coding
Patching
.NET
Security Protection Mechanism
checksec fog |
NX
NX enabled如果这个保护开启就是意味着栈中数据没有执行权限,以前的经常用的call esp或者jmp esp的方法就不能使用,但是可以利用rop这种方法绕过。
关闭:-z execstack |
开启了的话堆栈会变的可执行,可执行的话可能意味着可以执行shellcode
RELRO
RELRO 会有 Partial RELRO 和F ULL RELRO,若开启 FULL RELRO,意味着无法修改got表,否则能劫持程序流程。
关闭:-z norelro |
Stack (Canary)
如果栈中开启 Canary found,那么就不能用直接用溢出的方法覆盖栈中返回地址,而是要通过改写指针与局部变量、leak canary、overwrite canary 的方法来绕过。
关闭:-fno-stack-protector |
没开启的话,栈溢出会变的更加容易
PIE
Position Independent Executable 地址随机化。
没开启的话,程序的基地址就是已知的了(0x400000)
关闭: -no-pie |
Linux 平台下还有地址空间分布随机化(ASLR)的机制,即使可执行文件开启了 PIE 保护,还需要系统开启 ASLR 才会真正打乱基址,否则程序运行时依旧会在加载一个固定的基址上(不过和 No PIE 时基址不同)。
我们可以通过修改 /proc/sys/kernel/randomize_va_space 来控制 ASLR 启动与否,具体的选项有:
- 0,关闭 ASLR,没有随机化。栈、堆、.so 的基地址每次都相同。
- 1,普通的 ASLR。栈基地址、mmap 基地址、.so 加载基地址都将被随机化,但是堆基地址没有随机化。
- 2,增强的 ASLR,在 1 的基础上,增加了堆基地址随机化。
sudo bash -c 'echo 0 > /proc/sys/kernel/randomize_va_space' |
FORTIFY
FORTIFY_SOURCE 机制对格式化字符串有两个限制
包含%n的格式化字符串不能位于程序内存中的可写地址。
当使用位置参数时,必须使用范围内的所有参数。所以如果要使用%7$x,你必须同时使用1,2,3,4,5和6。
关闭:-D_FORTIFY_SOURCE=0 |
开启的话就是不能用 %n,%hn,%hhn 这种的,%4$p 也不行了。
Bypass
程序没有开启地址随机化:
def debug(addr): |
在程序运行时调用这个函数就可以调试了
程序开启地址随机化:
wordSz = 4 |
由于开启地址随机化之后ida pro打开程序后,显示的是程序的偏移地址,而不是实际的地址,当程序加载后程序的程序的实际地址是:基地址+偏移地址,调用debug函数的时候只要把偏移地址传递进去就好
泄露libc地址和版本的方法
【1】利用格式化字符串漏洞泄露栈中的数据,从而找到libc的某个函数地址,再利用libc-database来判断远程libc的版本,之后再计算出libc的基址,一般做题我喜欢找__libc_start_main的地址
【2】利用write这个函数,pwntools有个很好用的函数DynELF去利用这个函数计算出程序的各种地址,包括函数的基地址,libc的基地址,libc中system的地址
【3】利用printf函数,printf函数输出的时候遇到0x00时候会停止输出,如果输入的时候没有在最后的字节处填充0x00,那么输出的时候就可能泄露栈中的重要数据,比如libc的某个函数地址
简单的栈溢出
程序没有开启任何保护:
方法一:传统的教材思路是把shellcode写入栈中,然后查找程序中或者libc中有没有call esp或者jmp esp,比如这个题目: http://blog.csdn.net/niexinming/article/details/76893510
方法二:但是现代操作系统中libc中会开启地址随机化,所以先寻找程序中system的函数,再布局栈空间,调用gets(.bss),最后调用system(‘/bin/sh’) 比如这个题目:http://blog.csdn.net/niexinming/article/details/78796408
方法三:覆盖虚表方式利用栈溢出漏洞,这个方法是m4x师傅教我的方法,我觉得很巧妙,比如这个题目:http://blog.csdn.net/niexinming/article/details/78144301
开启nx的程序
开启nx之后栈和bss段就只有读写权限,没有执行权限了,所以就要用到rop这种方法拿到系统权限,如果程序很复杂,或者程序用的是静态编译的话,那么就可以使用ROPgadget这个工具很方便的直接生成rop利用链。有时候好多程序不能直接用ROPgadget这个工具直接找到利用链,所以就要手动分析程序来getshell了,比如这两个题目: http://blog.csdn.net/niexinming/article/details/78259866
开启canary的程序
开启canary后就不能直接使用普通的溢出方法来覆盖栈中的函数返回地址了,要用一些巧妙的方法来绕过或者利canary本身的弱点来攻击
【1】利用canary泄露flag,这个方法很巧妙的运用了canary本身的弱点,当__stack_check_fail时,会打印出正在运行中程序的名称,所以,我们只要将__libc_argv[0]覆盖为flag的地址就能将flag打印出来,比如这个题目: http://blog.csdn.net/niexinming/article/details/78522682
【2】利用printf函数泄露一个子进程的Canary,再在另一个子进程栈中伪造Canary就可以绕过Canary的保护了,比如这个题目:http://blog.csdn.net/niexinming/article/details/78681846
开启PIE的程序
【1】利用printf函数尽量多打印一些栈中的数据,根据泄露的地址来计算程序基地址,libc基地址,system地址,比如这篇文章中echo2的wp: http://blog.csdn.net/niexinming/article/details/78512274
【2】利用write泄露程序的关键信息,这样的话可以很方便的用DynELF这个函数了,比如这个文章中的rsbo2的题解:http://blog.csdn.net/niexinming/article/details/78620566
全部保护开启
如果程序的栈可以被完全控制,那么程序的保护全打开也会被攻破,比如这个题目:http://blog.csdn.net/niexinming/article/details/78666941
格式化字符串漏洞
格式化漏洞现在很难在成熟的软件中遇到,但是这个漏洞却很有趣
【1】pwntools有很不错的函数FmtStr和fmtstr_payload来自动计算格式化漏洞的利用点,并且自动生成payload,比如这个题目:http://blog.csdn.net/niexinming/article/details/78699413 和 http://blog.csdn.net/niexinming/article/details/78512274 中echo的题解
【2】格式化漏洞也是信息泄露的好伴侣,比如这个题目中制造格式化字符串漏洞泄露各种数据 http://blog.csdn.net/niexinming/article/details/78768850
uaf漏洞
如果把堆释放之后,没有把指针指针清0,还让指针保存下来,那么就会引发很多问题,比如这个题目 http://blog.csdn.net/niexinming/article/details/78598635
任意位置写
如果程序可以在内存中的任意位置写的话,那么威力绝对很大
【1】虽然只能写一个字节,但是依然可以控制程序的并getshell,比如这个题目 http://blog.csdn.net/niexinming/article/details/78542089
【2】修改got表是个控制程序流程的好办法,很多ctf题目只要能通过各种方法控制got的写入,就可以最终得到胜利,比如这个题目: http://blog.csdn.net/niexinming/article/details/78542089
【3】如果能计算出libc的基地址的话,控制top_chunk指针也是解题的好方法,比如这个题目: http://blog.csdn.net/niexinming/article/details/78759363
Virus
病毒通常会遵循如下相同步骤:
- 定位要感染的文件(一直等待直到打开某些东西,或者搜索目录)
- 检查某个文件是否已经被感染
- 如果已感染,跳过
- 保存文件日期/时间
- 设置一个跳转跳到我们的代码保存前几个字节
- 添加病毒主体代码
- 恢复文件日期/时间
DOS
COM 简介
DOS 内存布局
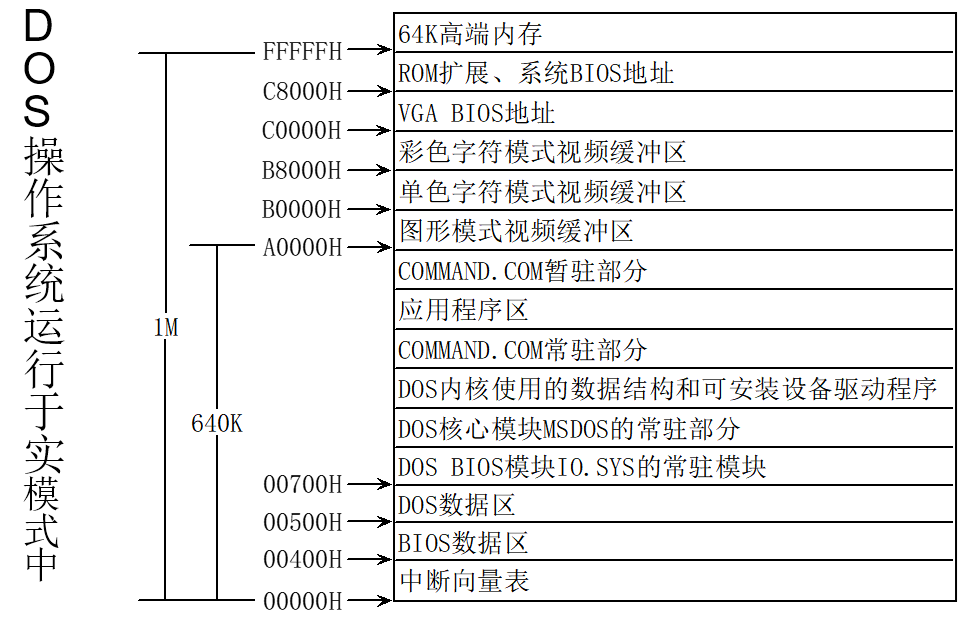
COM 覆盖型病毒
COM 伴随型病毒
COM 寄生型病毒
隐藏技术
变形技术
反跟踪、反调试、反分析
驻留内存
其他
Executable
ELF
ELF (Executable and Linkable Format)文件,也就是在 Linux 中的目标文件,主要有以下三种类型
- 可重定位文件(Relocatable File),包含由编译器生成的代码以及数据。链接器会将它与其它目标文件链接起来从而创建可执行文件或者共享目标文件。在 Linux 系统中,这种文件的后缀一般为
.o。 - 可执行文件(Executable File),就是我们通常在 Linux 中执行的程序。
- 共享目标文件(Shared Object File),包含代码和数据,这种文件是我们所称的库文件,一般以
.so结尾。一般情况下,它有以下两种使用情景:- 链接器(Link eDitor, ld)可能会处理它和其它可重定位文件以及共享目标文件,生成另外一个目标文件。
- 动态链接器(Dynamic Linker)将它与可执行文件以及其它共享目标组合在一起生成进程镜像。
关于 Link eDitor 的命名,https://en.wikipedia.org/wiki/GNU_linker
目标文件由汇编器和链接器创建,是文本程序的二进制形式,可以直接在处理器上运行。那些需要虚拟机才能够执行的程序 (Java) 不属于这一范围。
PE
Tools
pwntools
Pwntools is a python ctf library designed for rapid exploit development. It essentially help us write exploits quickly, and has a lot of useful functionality behind it.
Also one thing to note, pwntools has Python2 and Python3 versions. Atm this course uses the Python2, but I have plans to switch it all over to Python3. Just keep in mind that some things change between Python2 to the Python3 versions, however the changes are relatively small.
Installation
It’s fairly simple process. The installation process is pretty much just using pip:
$ sudo pip install pwn |
If you have any problems, google will help a lot.
Using it
So this is going to be an explanation on how you do various things with pwntools. It will only cover a small bit of functionality.
If we want to import it into python:
from pwn import * |
Now one thing that pwntools does for us, is it has some nice piping functionality which helps with IO. If we want to connect to the server at github.com (if you have an IP address, just swap out the dns name with the IP address) on port 9000 via tcp:
target = remote("github.com", 9000) |
If you want to run a target binary:
target = process("./challenge") |
If you want to attach the gdb debugger to a process:
gdb.attach(target) |
If we want to attach the gdb debugger to a process, and also immediately pass a command to gdb to set a breakpoint at main:
gdb.attach(target, gdbscript='b *main') |
Now for actual I/O. If we want to send the variable x to the target (target can be something like a process, or remote connection established by pwntools):
target.send(x) |
If we wanted to send the variable x followed by a newline character appended to the end:
target.sendline(x) |
If we wanted to print a single line of text from target:
print target.recvline() |
If we wanted to print all text from target up to the string out:
print target.recvuntil("out") |
Now one more thing, ELFs store data via least endian, meaning that data is stored with the least significant byte first. In a few situations where we are scanning in an integer, we will need to take this into account. Luckily pwntools will take care of this for us.
To pack the integer y as a least endian QWORD (commonly used for x64):
p64(x) |
To pack the integer y as a least endian DWORD (commonly used for x86):
p32(x) |
It can also unpack values we get. Let’s say we wanted to unpack a least endian QWORD and get it’s integer value:
u64(x) |
To unpack a DWORD:
u32(x) |
Lastly if just wanted to interact directly with target:
target.interactive() |
This is only a small bit of the functionality pwntools has. You will see a lot more of the functionality later. If you want to see more of pwntools, it has some great docs: http://docs.pwntools.com/en/stable/
send(payload)发送payloadsendline(payload)发送payload,并进行换行(末尾\n)sendafter(some_string, payload)接收到 some_string 后, 发送你的 payloadrecvn(N)接受 N(数字) 字符recvline()接收一行输出recvlines(N)接收 N(数字) 行输出recvuntil(some_string)接收到 some_string 为止
IDA Pro
https://xz.aliyun.com/t/4205 IDA Pro7.0使用技巧总结
其他的慢慢看 IDA 权威指南吧
IDA Pro 逆向速参 https://juejin.im/post/6844903550460362766
a:将数据转换为字符串
f5:一键反汇编
esc:回退键,能够倒回上一部操作的视图(只有在反汇编窗口才是这个作用,如果是在其他窗口按下esc,会关闭该窗口)
shift+f12:可以打开string窗口,一键找出所有的字符串,右击setup,还能对窗口的属性进行设置
ctrl+w:保存ida数据库
ctrl+s:选择某个数据段,直接进行跳转
ctrl+鼠标滚轮:能够调节流程视图的大小
x:对着某个函数、变量按该快捷键,可以查看它的交叉引用
g:直接跳转到某个地址
n:更改变量的名称
y:更改变量的类型
/ :在反编译后伪代码的界面中写下注释
\:在反编译后伪代码的界面中隐藏/显示变量和函数的类型描述,有时候变量特别多的时候隐藏掉类型描述看起来会轻松很多
;:在反汇编后的界面中写下注释
ctrl+shift+w:拍摄IDA快照
u:undefine,取消定义函数、代码、数据的定义
配置
Disassembly
OPCODE_BYTES = 6 // 机器码字节数,默认0 |
ASCII strings & names
Options => ASCII String styles
中文
IDA 从 7.0 版本开始正式支持中文字符串的显示,但仍需要配置 ida.cfg。
在 IDA \ CFG 目录下新建一个文件 Chinese.clt,内容如下。(好像默认就有了)
u2000..u206F, |
导航条
蓝色:.text section
- 深蓝:用户自己写的函数编译后的代码区
- 浅蓝:编译器自己添加的函数,像启动函数,异常函数等(我自己猜的,不一定百分百正确)
粉红色:.idata section
有关输入表的一些数据信息
军绿色:.rdata section
纯数据,只读
灰色:为了段对齐而留下的空隙
黑色:禁区,不存在任何数据
ghidra
GDB
gdb 还有其他一些小技巧,可以参考awesome-cheatsheets/tools/gdb.txt中的列表。该列表最初由韦神创建,我时不时也会添加一些上去。当然为了方便大家的查阅,这里直接给出汇总表格附录:
启动 GDB
| 命令 | 含义 | 备注 |
|---|---|---|
gdb object |
正常启动,加载可执行 | |
gdb object core |
对可执行 + core 文件进行调试 | |
gdb object pid |
对正在执行的进程进行调试 | |
gdb |
正常启动,启动后需要 file 命令手动加载 | |
gdb -tui |
启用 gdb 的文本界面(或 ctrl-x ctrl-a 更换 CLI/TUI) |
帮助信息
| 命令 | 含义 | 备注 |
|---|---|---|
help |
列出命令分类 | |
help running |
查看某个类别的帮助信息 | |
help run |
查看命令 run 的帮助 | |
help info |
列出查看程序运行状态相关的命令 | |
help info line |
列出具体的一个运行状态命令的帮助 | |
help show |
列出 GDB 状态相关的命令 | |
help show commands |
列出 show 命令的帮助 |
断点
| 命令 | 含义 | 备注 |
|---|---|---|
break main |
对函数 main 设置一个断点,可简写为 b main | |
break 101 |
对源代码的行号设置断点,可简写为 b 101 | |
break basic.c:101 |
对源代码和行号设置断点 | |
break basic.c:foo |
对源代码和函数名设置断点 | |
break *0x00400448 |
对内存地址 0x00400448 设置断点 | |
info breakpoints |
列出当前的所有断点信息,可简写为 info break | |
delete 1 |
按编号删除一个断点 | |
delete |
删除所有断点 | |
clear |
删除在当前行的断点 | |
clear function |
删除函数断点 | |
clear line |
删除行号断点 | |
clear basic.c:101 |
删除文件名和行号的断点 | |
clear basic.c:main |
删除文件名和函数名的断点 | |
clear *0x00400448 |
删除内存地址的断点 | |
disable 2 |
禁用某断点,但是部删除 | |
enable 2 |
允许某个之前被禁用的断点,让它生效 | |
rbreak {regexpr} |
匹配正则的函数前断点,如 ex_* 将断点 ex_ 开头的函数 |
|
tbreak function/line |
临时断点 | |
hbreak function/line |
硬件断点 | |
ignore {id} {count} |
忽略某断点 N-1 次 | |
condition {id} {expr} |
条件断点,只有在条件生效时才发生 | |
condition 2 i == 20 |
2号断点只有在 i == 20 条件为真时才生效 | |
watch {expr} |
对变量设置监视点 | |
info watchpoints |
显示所有观察点 | |
catch exec |
断点在exec事件,即子进程的入口地址 |
运行程序
| 命令 | 含义 | 备注 |
|---|---|---|
run |
运行程序 | |
run {args} |
以某参数运行程序 | |
run < file |
以某文件为标准输入运行程序 | |
run < <(cmd) |
以某命令的输出作为标准输入运行程序 | |
run <<< $(cmd) |
以某命令的输出作为标准输入运行程序 | Here-String |
set args {args} ... |
设置运行的参数 | |
show args |
显示当前的运行参数 | |
cont |
继续运行,可简写为 c | |
step |
单步进入(si 执行一行汇编),碰到函数会进去。 | |
step {count} |
单步多少次 | |
next |
单步跳过(ni 执行一行汇编),碰到函数不会进入。 | |
next {count} |
单步多少次 | |
CTRL+C |
发送 SIGINT 信号,中止当前运行的程序 | |
attach {process-id} |
链接上当前正在运行的进程,开始调试 | |
detach |
断开进程链接 | |
finish |
结束当前函数的运行 | |
until |
持续执行直到代码行号大于当前行号(跳出循环) | |
until {line} |
持续执行直到执行到某行 | |
kill |
杀死当前运行的函数 |
栈帧
| 命令 | 含义 | 备注 |
|---|---|---|
bt |
打印 backtrace | |
frame |
显示当前运行的栈帧 | |
up |
向上移动栈帧(向着 main 函数) | |
down |
向下移动栈帧(远离 main 函数) | |
info locals |
打印帧内的相关变量 | |
info args |
打印函数的参数 |
代码浏览
| 命令 | 含义 | 备注 |
|---|---|---|
list 101 |
显示第 101 行周围 10行代码 | |
list 1,10 |
显示 1 到 10 行代码 | |
list main |
显示函数周围代码 | |
list basic.c:main |
显示另外一个源代码文件的函数周围代码 | |
list - |
重复之前 10 行代码 | |
list *0x22e4 |
显示特定地址的代码 | |
cd dir |
切换当前目录 | |
pwd |
显示当前目录 | |
search {regexpr} |
向前进行正则搜索 | |
reverse-search {regexp} |
向后进行正则搜索 | |
dir {dirname} |
增加源代码搜索路径 | |
dir |
复位源代码搜索路径(清空) | |
show directories |
显示源代码路径 |
浏览数据
| 命令 | 含义 | 备注 |
|---|---|---|
print {expression} |
打印表达式,并且增加到打印历史 | |
print /x {expression} |
十六进制输出,print 可以简写为 p | |
print array[i]@count |
打印数组范围 | |
print $ |
打印之前的变量 | |
print *$->next |
打印 list | |
print $1 |
输出打印历史里第一条 | |
print ::gx |
将变量可视范围(scope)设置为全局 | |
print 'basic.c'::gx |
打印某源代码里的全局变量,(gdb 4.6) | |
print /x &main |
打印函数地址 | |
x *0x11223344 |
显示给定地址的内存数据 | |
x /nfu {address} |
打印内存数据,n是多少个,f是格式,u是单位大小 | |
x /10xb *0x11223344 |
按十六进制打印内存地址 0x11223344 处的十个字节 | |
x/x &gx |
按十六进制打印变量 gx,x和斜杆后参数可以连写 | |
x/4wx &main |
按十六进制打印位于 main 函数开头的四个 long | |
x/gf &gd1 |
打印 double 类型 | |
help x |
查看关于 x 命令的帮助 | |
info locals |
打印本地局部变量 | |
info functions {regexp} |
打印函数名称 | |
info variables {regexp} |
打印全局变量名称 | |
ptype name |
查看类型定义,比如 ptype FILE,查看 FILE 结构体定义 | |
whatis {expression} |
查看表达式的类型 | |
set var = {expression} |
变量赋值 | |
set *address = value |
可将 * 换成 char / short / long 分别设定 1/2/8 byte | |
set {int}0x600000 = 1337 |
||
display {expression} |
在单步指令后查看某表达式的值 | |
undisplay |
删除单步后对某些值的监控 | |
info display |
显示监视的表达式 | |
show values |
查看记录到打印历史中的变量的值 (gdb 4.0) | |
info history |
查看打印历史的帮助 (gdb 3.5) |
文件操作
| 命令 | 含义 | 备注 |
|---|---|---|
file {object} |
加载新的可执行文件供调试 | |
file |
放弃可执行和符号表信息 | |
symbol-file {object} |
仅加载符号表 | |
exec-file {object} |
指定用于调试的可执行文件(非符号表) | |
core-file {core} |
加载 core 用于分析 |
信号控制
| 命令 | 含义 | 备注 |
|---|---|---|
info signals |
打印信号设置 | |
handle {signo} {actions} |
设置信号的调试行为 | |
handle INT print |
信号发生时打印信息 | |
handle INT noprint |
信号发生时不打印信息 | |
handle INT stop |
信号发生时中止被调试程序 | |
handle INT nostop |
信号发生时不中止被调试程序 | |
handle INT pass |
调试器接获信号,不让程序知道 | |
handle INT nopass |
调试起不接获信号 | |
signal signo |
继续并将信号转移给程序 | |
signal 0 |
继续但不把信号给程序 |
线程调试
| 命令 | 含义 | 备注 |
|---|---|---|
info threads |
查看当前线程和 id | |
thread {id} |
切换当前调试线程为指定 id 的线程 | |
break {line} thread all |
所有线程在指定行号处设置断点 | |
thread apply {id..} cmd |
指定多个线程共同执行 gdb 命令 | |
thread apply all cmd |
所有线程共同执行 gdb 命令 | |
set schedule-locking ? |
调试一个线程时,其他线程是否执行 | |
set non-stop on/off |
调试一个线程时,其他线程是否运行 | |
set pagination on/off |
调试一个线程时,分页是否停止 | |
set target-async on/off |
同步或者异步调试,是否等待线程中止的信息 |
进程调试
| 命令 | 含义 | 备注 |
|---|---|---|
info inferiors |
查看当前进程和 id | |
inferior {id} |
切换某个进程 | |
kill inferior {id...} |
杀死某个进程 | |
set detach-on-fork on/off |
设置当进程调用fork时gdb是否同时调试父子进程 | |
set follow-fork-mode parent/child |
设置当进程调用fork时是否进入子进程 |
汇编调试
| 命令 | 含义 | 备注 |
|---|---|---|
info registers |
打印普通寄存器 | |
info all-registers |
打印所有寄存器 | |
print/x $pc |
打印单个寄存器 | |
stepi |
指令级别单步进入 | si |
nexti |
指令级别单步跳过 | ni |
display/i $pc |
监控寄存器(每条单步完以后会自动打印值) | |
x/x &gx |
十六进制打印变量 | |
info line 22 |
打印行号为 22 的内存地址信息 | |
info line *0x2c4e |
打印给定内存地址对应的源代码和行号信息 | |
disassemble {addr} |
对地址进行反汇编,比如 disassemble 0x2c4e |
其他命令
| 命令 | 含义 | 备注 |
|---|---|---|
show commands |
显示历史命令 (gdb 4.0) | |
info editing |
显示历史命令 (gdb 3.5) | |
ESC-CTRL-J |
切换到 Vi 命令行编辑模式 | |
set history expansion on |
允许类 c-shell 的历史 | |
break class::member |
在类成员处设置断点 | |
list class:member |
显示类成员代码 | |
ptype class |
查看类包含的成员 | /o可以看成员偏移,类似pahole |
print *this |
查看 this 指针 | |
define command ... end |
定义用户命令 | |
<return> |
直接按回车执行上一条指令 | |
shell {command} [args] |
执行 shell 命令 | |
source {file} |
从文件加载 gdb 命令 | |
quit |
退出 gdb |
pwndbg
用法特性:https://github.com/pwndbg/pwndbg/blob/dev/FEATURES.md
分屏
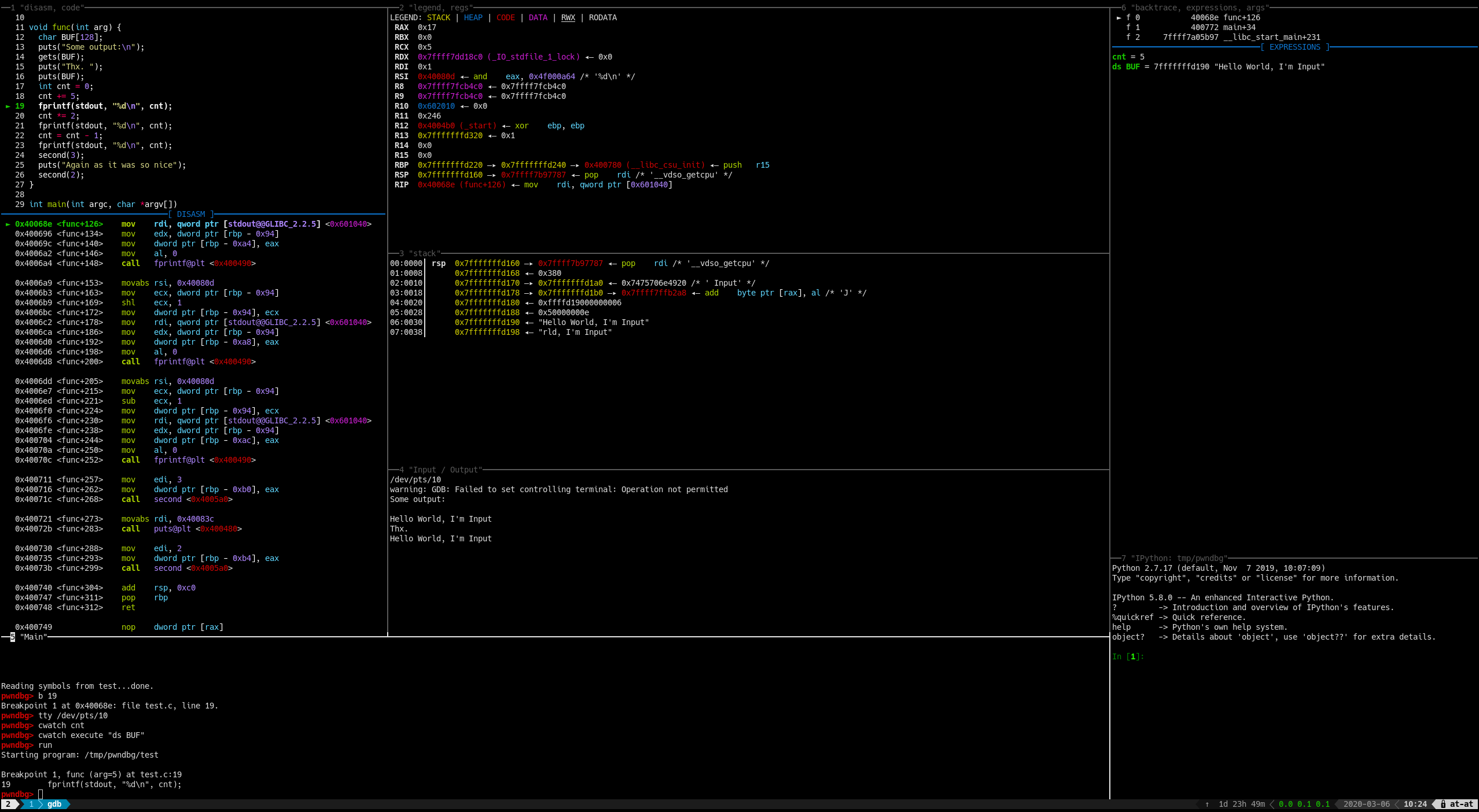
peda
git clone https://github.com/longld/peda.git ~/peda |
Ollydbg
PE 类工具
masm32
Immunitydebugger
pwndbg
z3
strings
file
binwalk
Reference
https://guyinatuxedo.github.io/
https://adworld.xctf.org.cn/task REVERSE或者PWN或者MOBILE三个方向合计完成任意9题