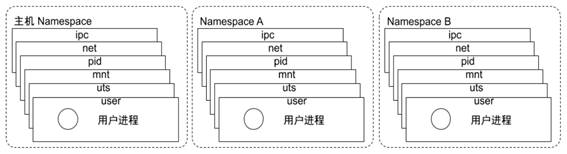
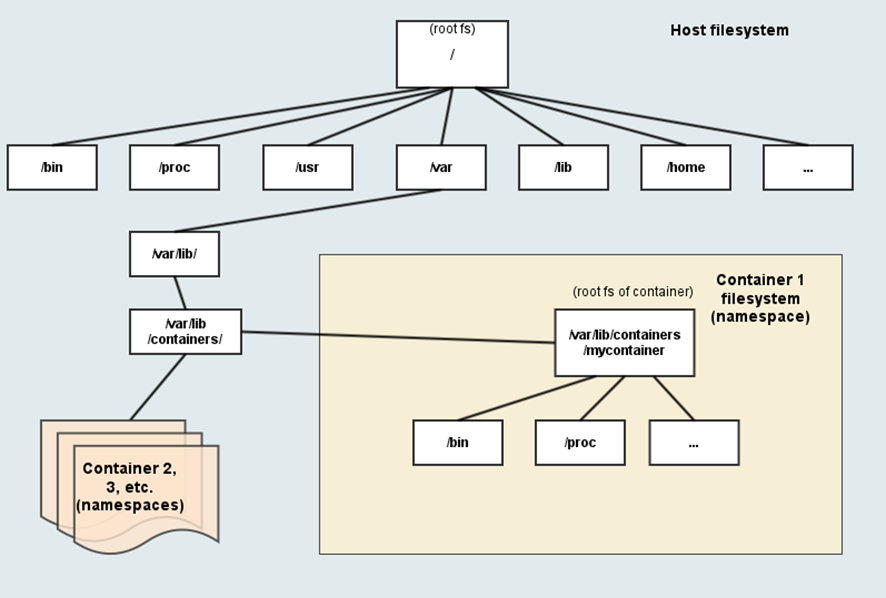
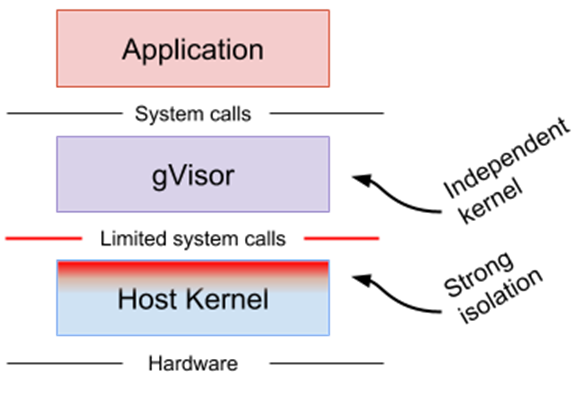
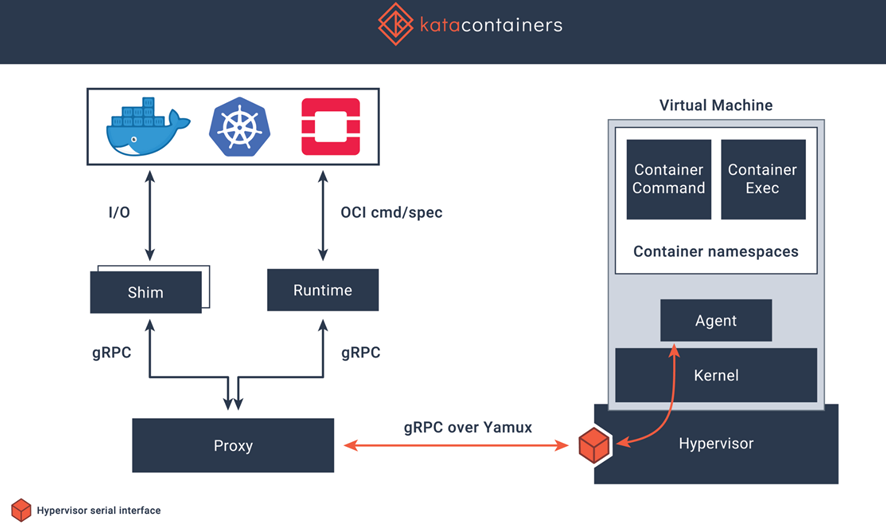
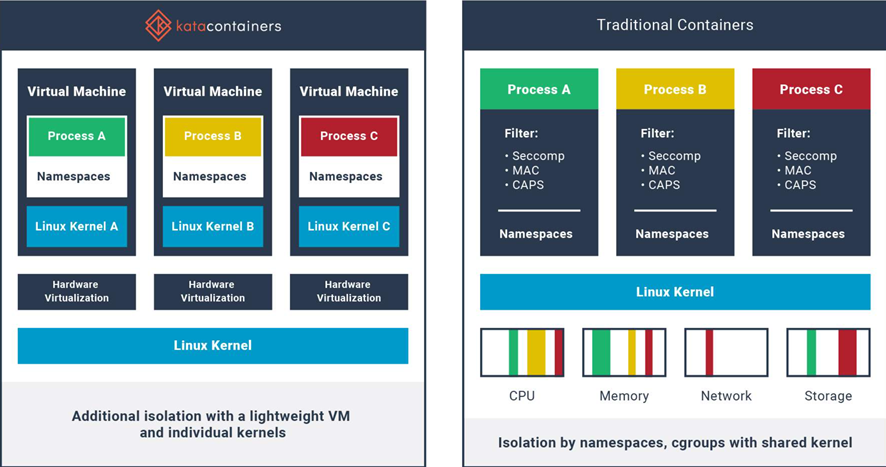
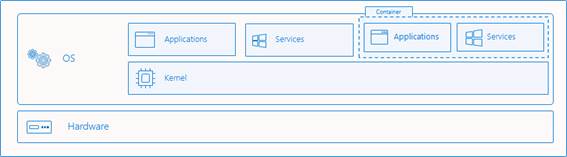
A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource.
Changes to the global resource are visible to other processes that are members of the namespace, but are invisible to other processes.
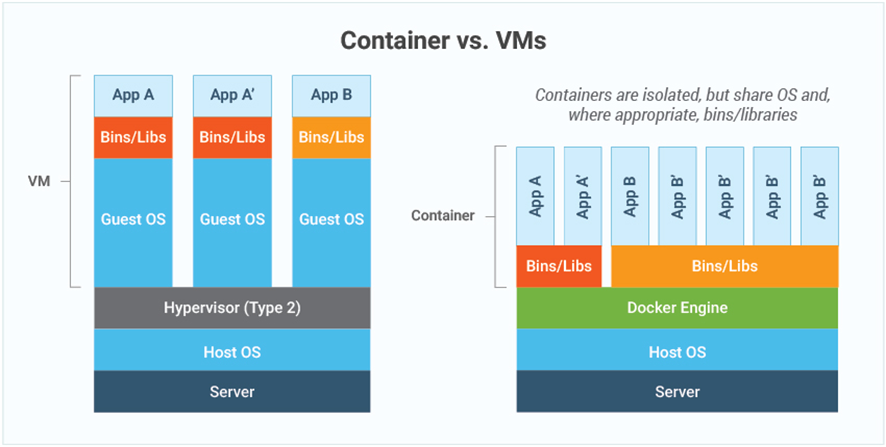
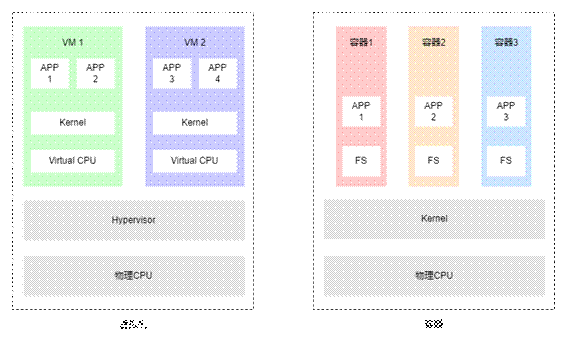
One use of namespaces is to implement containers.
Limits what you can see.
Namespace Flag Isolates Cgroup CLONE_NEWCGROUP Cgroup root directory IPC CLONE_NEWIPC System V IPC, POSIX message queues Network CLONE_NEWNET Network devices, stacks, ports, etc. Mount CLONE_NEWNS Mount points PID CLONE_NEWPID Process IDs Time CLONE_NEWTIME Boot and monotonic clocks User CLONE_NEWUSER User and group IDs UTS CLONE_NEWUTS Hostname and NIS domain name
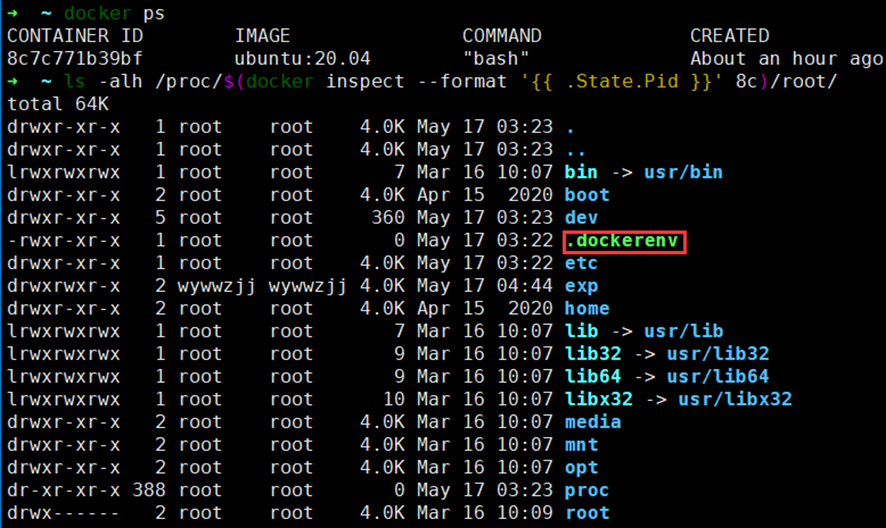
First experience of Namespaces
unshare - run program with some namespaces unshared from parent
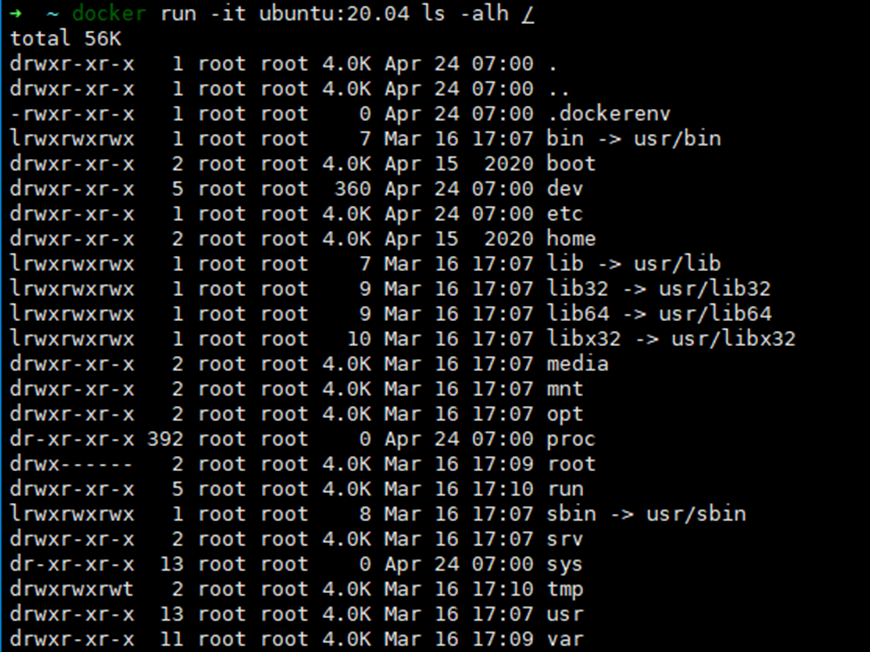
➜ ~ id uid=1000(iubu) gid=1000(iubu) groups=1000(iubu),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),122(lpadmin),134(lxd),135(sambashare),999(docker)
➜ ~ unshare -m -n -p -u -U -r -f --mount-proc bash root@ubuntu:~# id uid=0(root) gid=0(root) groups=0(root),65534(nogroup) root@ubuntu:~# ps -aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.2 0.1 19920 5288 pts/2 S 13:33 0:00 bash root 7 0.0 0.0 21584 3812 pts/2 R+ 13:33 0:00 ps -aux root@ubuntu:~# hostname whlab && hostname whlab root@ubuntu:~# ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 root@ubuntu:~# exit exit ➜ ~ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:d0:43:f7 brd ff:ff:ff:ff:ff:ff altname enp2s1 ➜ ~ hostname ubuntu
Options: -a, --all enter all namespaces (target) -t, --target <pid> target process to get namespaces from -m, --mount[=<file>] enter mount namespace -u, --uts[=<file>] enter UTS namespace (hostname etc) -i, --ipc[=<file>] enter System V IPC namespace -n, --net[=<file>] enter network namespace -p, --pid[=<file>] enter pid namespace -C, --cgroup[=<file>] enter cgroup namespace -U, --user[=<file>] enter user namespace -S, --setuid <uid> set uid in entered namespace -G, --setgid <gid> set gid in entered namespace --preserve-credentials do not touch uids or gids -r, --root[=<dir>] set the root directory -w, --wd[=<dir>] set the working directory -F, --no-fork do not fork before execing <program> -Z, --follow-context set SELinux context according to --target PID
-h, --help display this help -V, --version display version
root@69cdae2e90c3:/# mount overlay on / type overlay (rw,relatime,lowerdir=/var/lib/docker/overlay2/l/I7OJVG6PNZR6XYZMPPC346MA6N:/var/lib/docker/overlay2/l/EEK3WLG3RPSB6CMMDQI6TAKSHS,upperdir=/var/lib/docker/overlay2/efd343546cc3e3dbc17d5c2d9166e475fe7759a487a6150684ac001c7627425e/diff,workdir=/var/lib/docker/overlay2/efd343546cc3e3dbc17d5c2d9166e475fe7759a487a6150684ac001c7627425e/work)
chroot
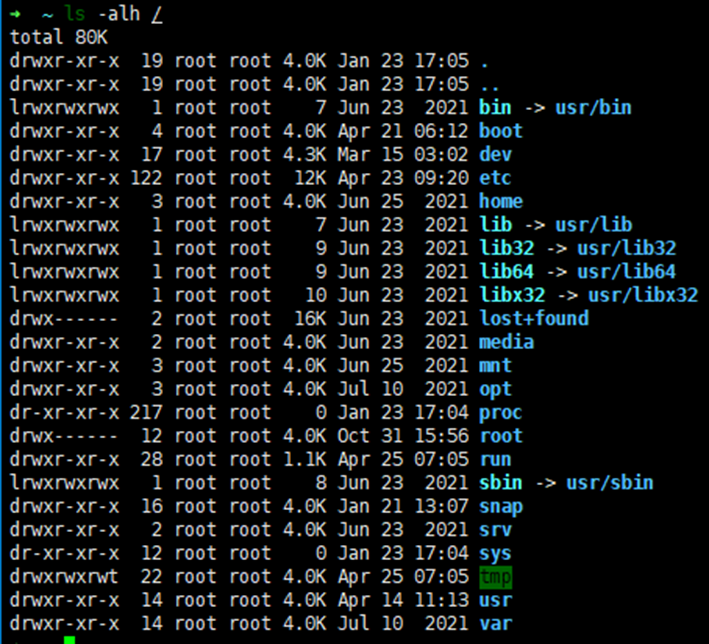
root@ubuntu:/home/iubu/runc/ubuntu/rootfs# ls bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var root@ubuntu:/home/iubu/runc/ubuntu/rootfs# chroot . bash root@ubuntu:/# ps Error, do this: mount -t proc proc /proc root@ubuntu:/# ls -al / -rwxr-xr-x 1 1000 1000 0 Apr 28 16:00 .dockerenv drwxr-xr-x 2 1000 1000 12288 Apr 28 16:00 bin drwxr-xr-x 2 1000 1000 4096 Apr 28 16:00 boot drwxr-xr-x 4 1000 1000 4096 Apr 28 16:00 dev drwxr-xr-x 30 1000 1000 4096 Apr 28 16:00 etc drwxr-xr-x 2 1000 1000 4096 Apr 28 16:00 home ... drwxr-xr-x 13 1000 1000 4096 Apr 28 16:00 var
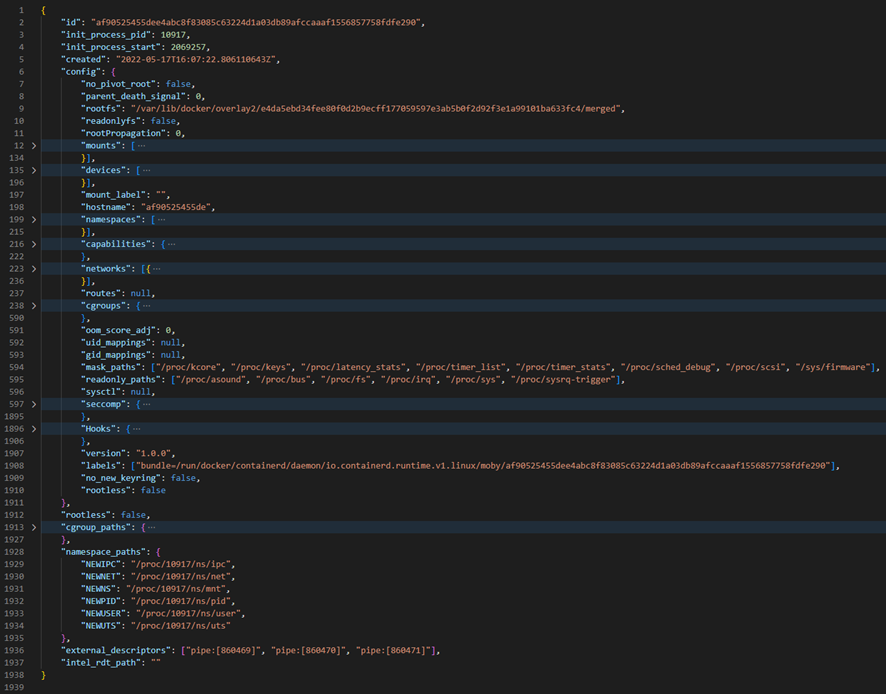
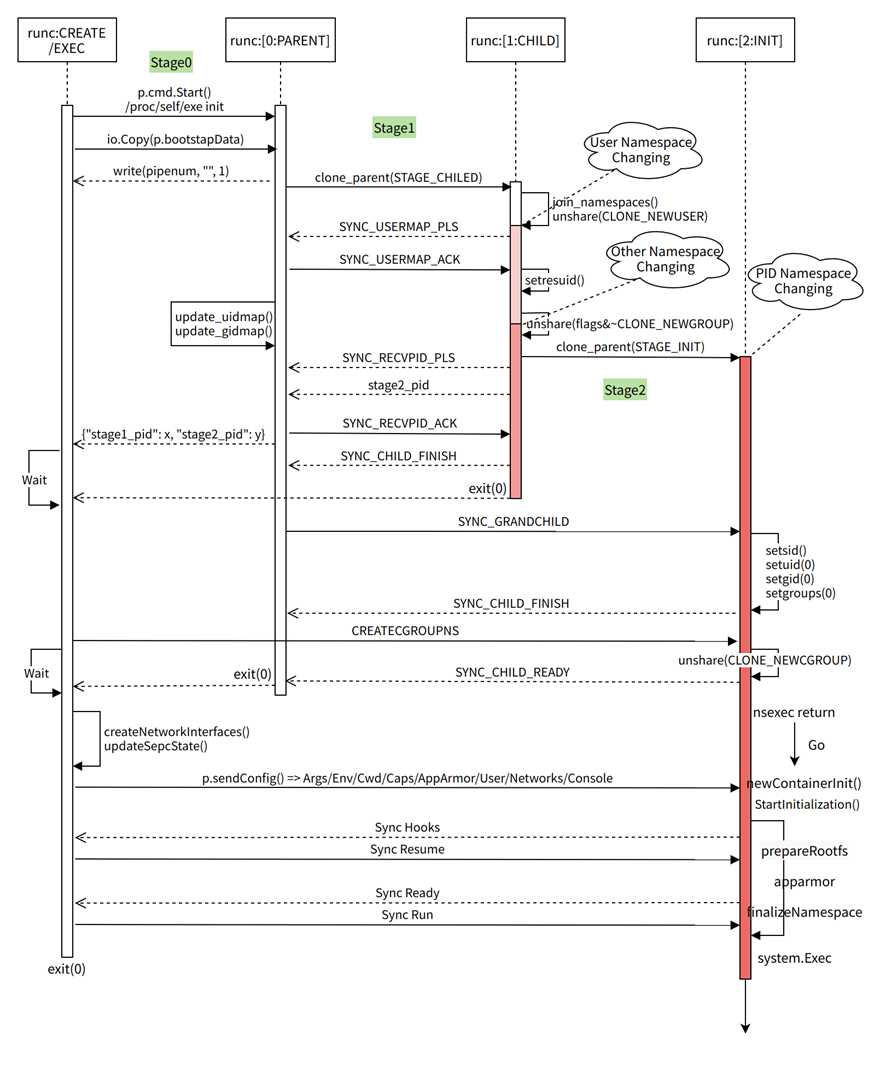
All config in json
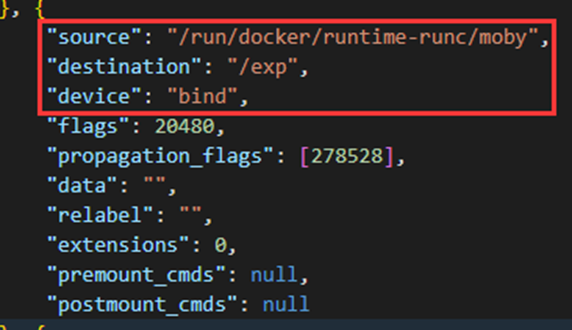
docker run -d -v /run/docker/runtime-runc/moby:/exp ubuntu:20.04 sleep inf af90525455dee4abc8f83085c63224d1a03db89afccaaaf1556857758fdfe290
# 创建一对 veth ip link add <p1-name> type veth peer name <p2-name> # 设置 Network Namespace ip link add <p1-name> netns <p1-ns> type veth peer <p2-name> netns <p2-ns>
bridge - Ethernet Bridge device ... veth - Virtual ethernet interface vlan - 802.1q tagged virtual LAN interface vxlan - Virtual eXtended LAN ip6tnl - Virtual tunnel interface IPv4|IPv6 over IPv6 ipip - Virtual tunnel interface IPv4 over IPv4 sit - Virtual tunnel interface IPv6 over IPv4 gre - Virtual tunnel interface GRE over IPv4 ...
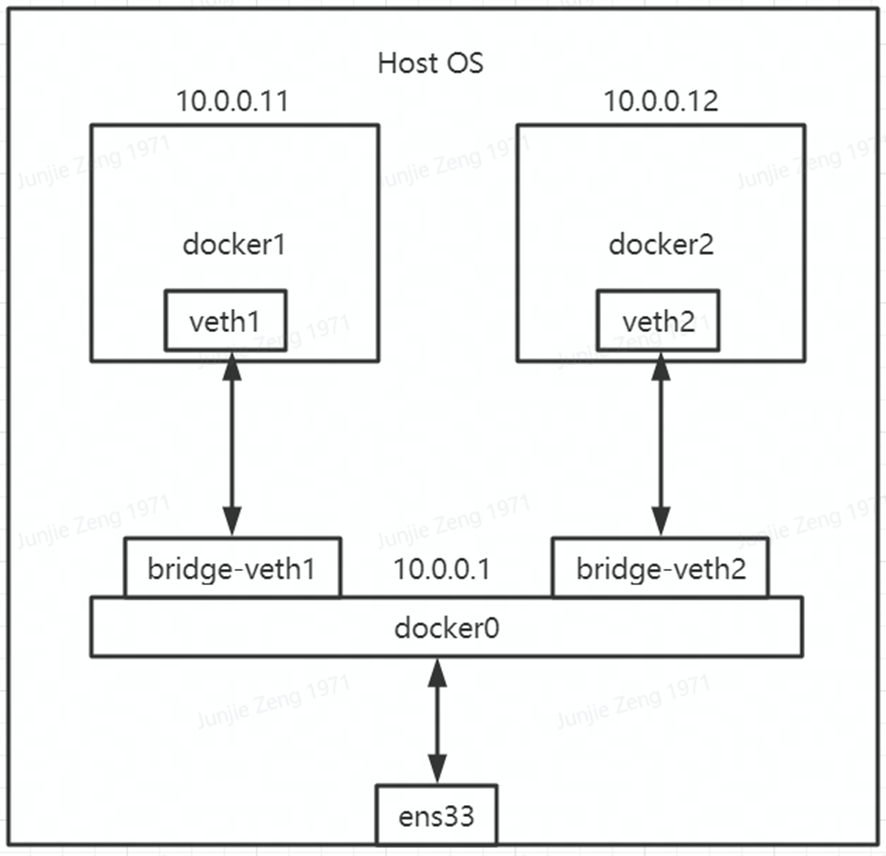
自己动手,构建一个如上图的简易网络环境:
# 创建一个 net namespace ➜ ~ ip netns add docker1 ➜ ~ ip netns list docker1 ➜ ~ l /run/netns -r--r--r-- 1 root root 0 Apr 26 05:33 docker1 ➜ ~ mount | grep netns tmpfs on /run/netns type tmpfs (rw,nosuid,nodev,noexec,relatime,size=399468k,mode=755) nsfs on /run/netns/docker1 type nsfs (rw) nsfs on /run/netns/docker1 type nsfs (rw)
# 新建的 netns 默认有一个 lo ➜ ~ ip netns exec docker1 ip a 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ➜ ~ ip netns exec docker1 ip link set dev lo up # 可省略 ➜ ~ ip netns exec docker1 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever
# 创建一对虚拟网卡 ➜ ~ ip link add bridge-veth1 type veth peer name veth1 ➜ ~ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:c2:f4:77 brd ff:ff:ff:ff:ff:ff 3: veth1@bridge-veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether aa:29:f4:e8:ed:d6 brd ff:ff:ff:ff:ff:ff 4: bridge-veth1@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 4e:d1:a9:86:2f:32 brd ff:ff:ff:ff:ff:ff
# 将 veth 的一端 veth1 放入 docker1 ns 中 ➜ ~ ip link set veth1 netns docker1 ➜ ~ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:c2:f4:77 brd ff:ff:ff:ff:ff:ff 4: bridge-veth1@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 4e:d1:a9:86:2f:32 brd ff:ff:ff:ff:ff:ff link-netns docker1 # 可看到 veth1 已出现在 docker1 中 ➜ ~ ip netns exec docker1 ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: veth1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether a2:c9:82:eb:67:cb brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 将 veth1 改个名字 eth0,并设置 IP 地址 ➜ ~ ip netns exec docker1 ip link set dev veth1 name eth0 ➜ ~ ip netns exec docker1 ip addr add 10.0.0.11/24 dev eth0 ➜ ~ ip netns exec docker1 ip link set eth0 up ➜ ~ ip link set bridge-veth1 up ➜ ~ ip netns exec docker1 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 3: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether be:d0:48:d1:39:bf brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.0.0.11/24 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::bcd0:48ff:fed1:39bf/64 scope link valid_lft forever preferred_lft forever
同理再设置一个 docker2:
ip netns add docker2 ip netns exec docker2 ip link set dev lo up ip link add bridge-veth2 type veth peer name veth2 netns docker2 ip netns exec docker2 ip link set dev veth2 name eth0 ip netns exec docker2 ip addr add 10.0.0.12/24 dev eth0 ip netns exec docker2 ip link set eth0 up ip link set dev bridge-veth2 up
➜ ~ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:c2:f4:77 brd ff:ff:ff:ff:ff:ff 4: bridge-veth1@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 4e:d1:a9:86:2f:32 brd ff:ff:ff:ff:ff:ff link-netns docker1 5: bridge-veth2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 62:7d:2f:b1:cb:45 brd ff:ff:ff:ff:ff:ff link-netns docker2
添加一个网桥,即 docker0 部分:
➜ ~ ip link add docker0 type bridge ➜ ~ ip link set docker0 up
# 将 bridge-veth1、bridge-veth2 接到网桥上 ➜ ~ ip link set bridge-veth1 master docker0 ➜ ~ ip link set bridge-veth2 master docker0
# 查看网桥接了哪些网卡 ➜ ~ ip link show master docker0
当前网络地址:
➜ ~ ip -all netns exec ip a netns: docker2 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 86:61:6b:7c:cf:50 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.0.0.12/24 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::8461:6bff:fe7c:cf50/64 scope link valid_lft forever preferred_lft forever
netns: docker1 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 3: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether aa:29:f4:e8:ed:d6 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.0.0.11/24 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::a829:f4ff:fee8:edd6/64 scope link valid_lft forever preferred_lft forever
docker1、docker2 实现互通:
➜ ~ ip -all netns exec ping -c 1 10.0.0.12 netns: docker2 PING 10.0.0.12 (10.0.0.12) 56(84) bytes of data. 64 bytes from 10.0.0.12: icmp_seq=1 ttl=64 time=0.023 ms
--- 10.0.0.12 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.023/0.023/0.023/0.000 ms
netns: docker1 PING 10.0.0.12 (10.0.0.12) 56(84) bytes of data. 64 bytes from 10.0.0.12: icmp_seq=1 ttl=64 time=0.029 ms
--- 10.0.0.12 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.029/0.029/0.029/0.000 ms
➜ ~ ip -all netns exec ping -c 1 10.0.0.11 netns: docker2 PING 10.0.0.11 (10.0.0.11) 56(84) bytes of data. 64 bytes from 10.0.0.11: icmp_seq=1 ttl=64 time=0.039 ms
--- 10.0.0.11 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.039/0.039/0.039/0.000 ms
netns: docker1 PING 10.0.0.11 (10.0.0.11) 56(84) bytes of data. 64 bytes from 10.0.0.11: icmp_seq=1 ttl=64 time=0.020 ms
--- 10.0.0.11 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.020/0.020/0.020/0.000 ms
还是不通外网:
➜ ~ ip netns exec docker1 ping -c 1 1.1.1.1 ping: connect: Network is unreachable
还差关键一步,设置转发:
➜ ~ ip addr add 10.0.0.1/24 dev docker0
# 添加一个路由,默认全部走网桥上 ➜ ~ ip -all netns exec ip route add default via 10.0.0.1 ➜ ~ ip -all netns exec ip route netns: docker2 default via 10.0.0.1 dev eth0 10.0.0.0/24 dev eth0 proto kernel scope link src 10.0.0.12
netns: docker1 default via 10.0.0.1 dev eth0 10.0.0.0/24 dev eth0 proto kernel scope link src 10.0.0.11
➜ ~ ip -all netns exec ping -c 1 1.1.1.1 netns: docker2 PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data. 64 bytes from 1.1.1.1: icmp_seq=1 ttl=127 time=132 ms
--- 1.1.1.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 132.465/132.465/132.465/0.000 ms
netns: docker1 PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data. 64 bytes from 1.1.1.1: icmp_seq=1 ttl=127 time=132 ms
--- 1.1.1.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 132.086/132.086/132.086/0.000 ms
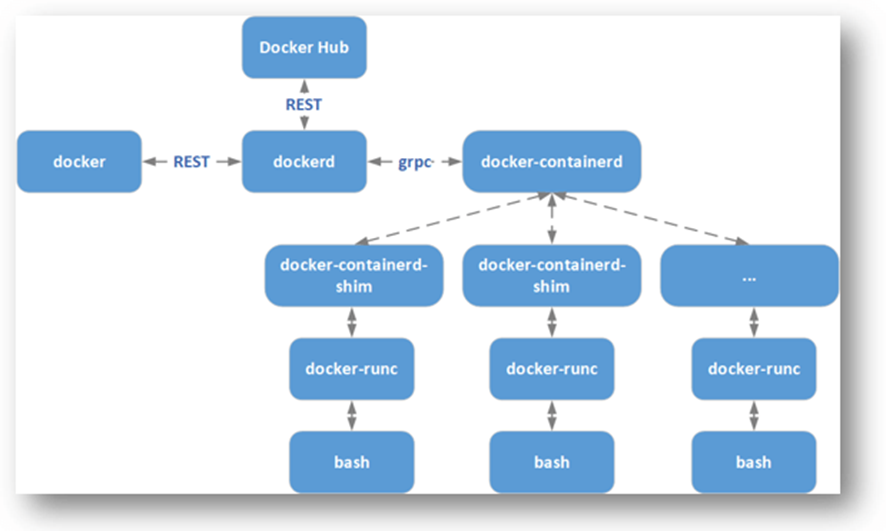
Docker Networking
➜ ~ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:ae:69:6b brd ff:ff:ff:ff:ff:ff 3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 02:42:4b:d6:d3:79 brd ff:ff:ff:ff:ff:ff 19: vethadac88e@if18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default link/ether 26:e8:b8:a7:eb:36 brd ff:ff:ff:ff:ff:ff link-netnsid 1
➜ ~ docker exec -it 9f bash root@9fa04dc61480:/# id uid=0(root) gid=0(root) groups=0(root) root@9fa04dc61480:/# hostname test hostname: you must be root to change the host name
root@69cdae2e90c3:/# fdisk -l Device Start End Sectors Size Type /dev/sda3 1054720 83884031 82829312 39.5G Linux filesystem
root@69cdae2e90c3:/# mount /dev/sda3 /mnt root@69cdae2e90c3:/# ls /mnt 2333 boot dev home lib32 libx32 media opt root sbin srv sys usr bin cdrom etc lib lib64 lost+found mnt proc run snap swapfile tmp var
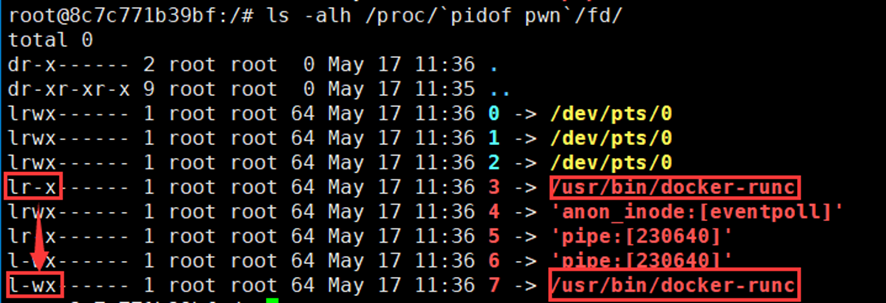
Following Log4Shell, AWS released several hot patch solutions that monitor for vulnerable Java applications and Java containers and patch them on the fly. Each solution suits a different environment, covering standalone servers, Kubernetes clusters, Elastic Container Service (ECS) clusters and Fargate.
We’ve decided not to share the exploit’s implementation details at this time to prevent malicious parties from weaponizing it.
April 19: AWS releases final fixes and advisories; Unit 42 discloses the vulnerabilities publicly.